



Cribl Stream Basic Concepts
Notable features and concepts to get a fundamental understanding of Cribl Stream
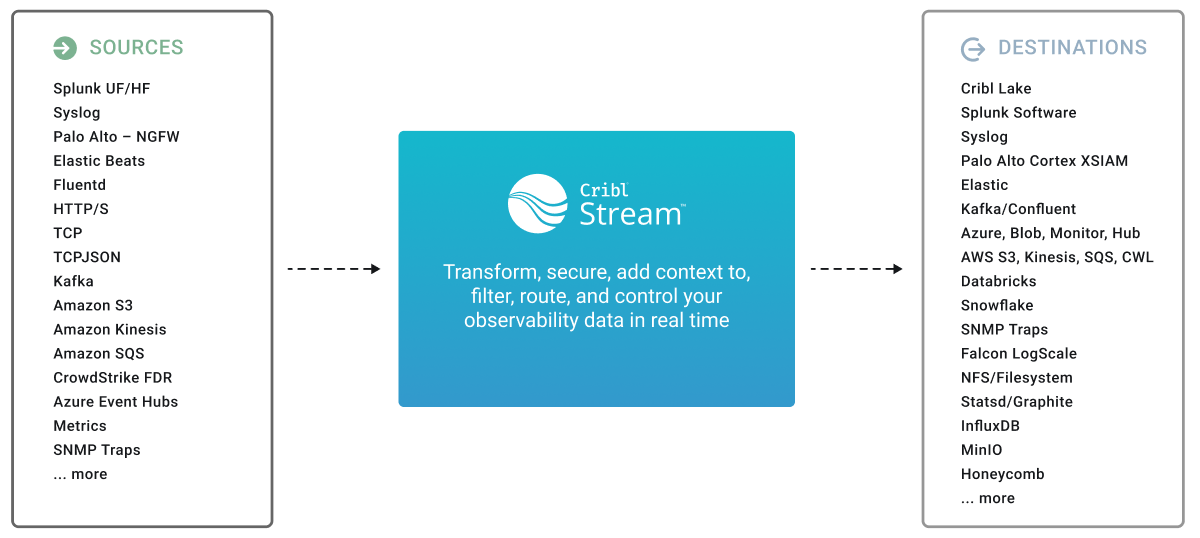
As we describe features and concepts, it helps to have a mental model of Cribl Stream as a system that receives events from various sources, processes them, and then sends them to one or more destinations.
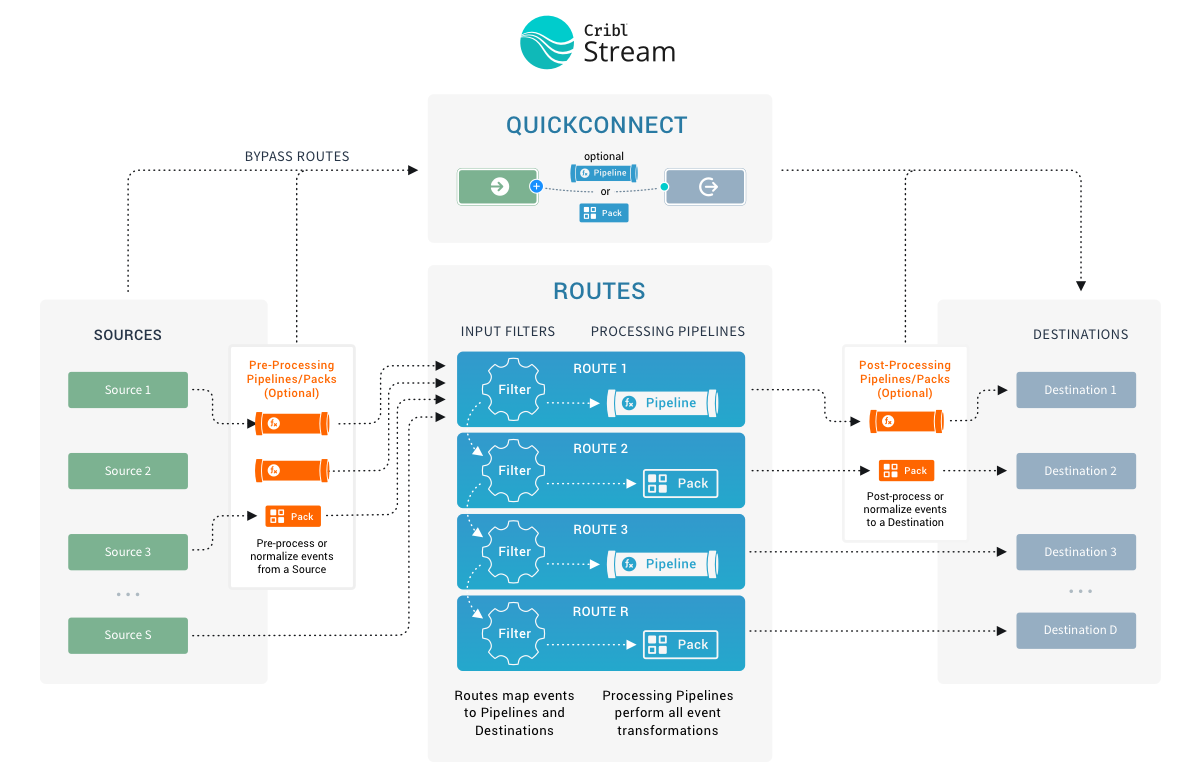
Let’s zoom in on the center of the above diagram, to take a closer look at the processing and transformation options that Cribl Stream provides internally. The basic interface concepts to work with are Sources, which collect data; and Routes, which manage data flowing through Pipelines, which consist of Functions.
Sources
Sources are configurations that enable Cribl Stream to receive data from remote senders (such as Splunk, TCP, Syslog) or to collect data from remote file stores or the local machine.
Destinations
Destinations are downstream receivers that receive data from Cribl Stream after data processing and transformation. Destinations are where Cribl Stream delivers your data after processing and transformation. Cribl Stream can send data to many different Destinations, including Splunk, Kafka, Kinesis, InfluxDB, Snowflake, Databricks, TCP JSON, and others.
Routes
Routes evaluate incoming events against filter expressions to find the appropriate Pipeline to send them to. Routes are evaluated in order. Each Route can be associated with only one Pipeline and one output (configured as a Cribl Stream Destination).
By default, the Final toggle is on when each Route is created, so a Route-Pipeline-Destination set will consume events that match its filter, and that’s that.
However, if you toggle Final off, one or more event clones will be sent down the associated Pipeline, while the original event continues down Cribl Stream’s Routing table to be evaluated against other configured Routes. This is very useful in cases where the same set of events needs to be processed in multiple ways, and delivered to different destinations. For more details, see Routes.
Pipelines
A series of Functions is called a Pipeline, and the order in which you specify the Functions determines their execution order. Events are delivered to the beginning of a Pipeline by a Route, and as they’re processed by a Function, the events are passed to the next Function down the line.

Pipelines attached to Routes are called processing Pipelines. You can optionally attach pre-processing Pipelines to individual Cribl Stream Sources, and attach post-processing Pipelines to Cribl Stream Destinations. All Pipelines are configured through the same UI - these three designations are determined only by a Pipeline’s placement in Cribl Stream’s data flow.

Events only move forward - toward the end of a Pipeline, and eventually out of the system. For more details, see Pipelines.
Functions
At its core, a Function is a piece of code that executes on an event, and that encapsulates the smallest amount of processing that can happen to that event. For instance, a very simple Function can be one that replaces the term foo with bar on each event. Another one can hash or encrypt bar. Yet another function can add a field - say, dc=jfk-42 - to any event with source=*us-nyc-application.log.

Functions process each event that passes through them. To help improve performance, Functions can optionally be configured with filters, to limit their processing scope to matching events only. For more details, see Functions.
QuickConnect
QuickConnect is a visual interface for setting up data flow through your Cribl Stream deployment. You can quickly drag and drop connections between Sources and Destinations, optionally including or excluding Pipelines or Packs.
The only major constraint is that QuickConnect completely bypasses Routes. So QuickConnect configurations have no Routing table, and no conditional cloning, cascading, or routing of data - every QuickConnect connection is parallel and independent.
Use the Routing menu to toggle between the Data Routes and QuickConnect interfaces. (The Routing menu appears at the top of the Worker Groups page in a Distributed deployment, and at the top of the Stream Home page in a Single-instance deployment.)

A Scalable Model
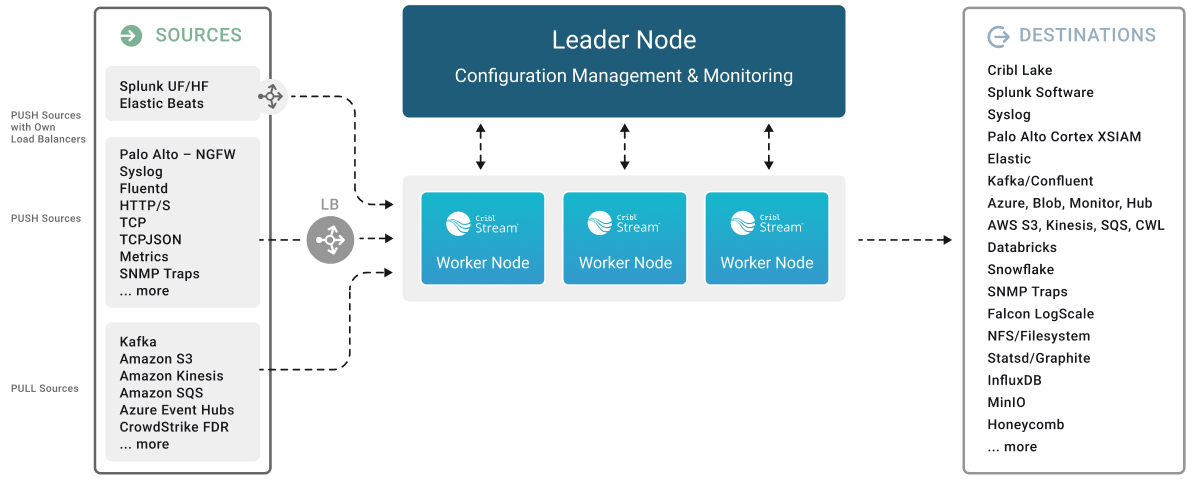
You can scale Cribl Stream up to meet enterprise needs in a distributed deployment. Here, multiple Cribl Stream Workers (instances) share the processing load. But as you can see in the preview schematic below, even complex deployments follow the same basic model outlined above.
Shared-Nothing Architecture
All Cribl Stream deployments are based on a shared-nothing architecture pattern. This means that each instance (or Worker Node) and its associated Worker Processes operate autonomously, handling inputs, outputs, and event processing independently.
This architecture ensures scalability and resilience. The system, composed of a Leader and multiple Worker Nodes, will continue to operate even if individual Worker Processes or Worker Nodes fail. It also allows individual Nodes to upgrade without system-wide downtime.