



Collector Sources
Unlike other Cribl Stream Sources, Collectors are designed to ingest data intermittently, rather than continuously. You can use Collectors to dispatch on-demand (ad hoc) collection tasks, which fetch or “replay” (re-ingest) data from local or remote locations.
Collectors also support scheduled periodic collection jobs - recurring tasks that can make batch collection of stored data more like continual processing of streaming data. You configure Collectors prior to, and independently from, your configuration of ad hoc versus scheduled collection runs.
Collectors are integral to Cribl Stream’s larger story about optimizing your data throughput. Send full-fidelity log and metrics data (“everything”) to low-cost storage, and then use Cribl Stream Collectors to selectively route (“replay”) only needed data to your systems of analysis.
Collector Resources
- Video introduction to Data Collection, in < 2 minutes.
- Video introduction to Data Collection Scheduling, in < 2 minutes.
- Free, interactive try-out of Collectors in Cribl’s Data Collection & Replay sandbox.
- Example Collector configurations - ready to import into Cribl Stream - in Cribl’s Collector Templates repository.
- Using Collectors guides: S3 Storage and Replay | REST API Collectors | Microsoft Graph API Collection | ServiceNow API Collection | Creating a Custom Collector.
Collector Types
Cribl Stream currently provides the following Collector options:
- Azure Blob - enables data collection and replay from Azure Blob Storage objects.
- Cribl Lake - enabled data collection and reply from Cribl Lake Datasets.
- Database - enables data collection from database management systems like MySQL and SQL Server.
- File System/NFS - enables data collection and replay from local or remote filesystem locations.
- Google Cloud Storage - enables data collection and replay from Google Cloud Storage buckets.
- Health Check - monitors the availability of system endpoints.
- REST/API Endpoint - enables data collection and replay via REST API calls. Provides four Discover options, to support progressively more complex (and dynamic) item enumerations.
- S3 - enables data collection and replay from Amazon S3 buckets or S3-compatible stores.
- Script - enables data collection and replay via custom scripts.
- Splunk Search - enables data collection and replay from Splunk queries. Supports both simple and complex queries, as well as real-time searches.
If you are exploring Collectors for the first time, the File System/NFS Collector is the simplest to configure, while the REST/API Collector offers the most complex configuration options.
How Do Collectors Work
You can configure a Cribl Stream Node to retrieve data from a remote system by selecting Manage from the top nav, then a Worker Group to configure. Next, click Data > Sources > Collectors. Data collection is a multi-step process:
First, define a Collector instance. In this step, you configure collector-specific settings by selecting a Collector type and pointing it at a specific target. For example, the target will be a directory if the type is File System, or an S3 bucket/path if the type is Amazon S3.
Next, schedule or manually run the Collector. In this step, you configure either scheduled-job-specific or run-specific settings - such as the run Mode (Preview, Discovery, or Full Run), the Filter expression to match the data against, the time range, and so on.
In a Distributed environment, the Leader Node orchestrates collection jobs. The Leader maintains the job definitions and breaks them down into individual tasks. It then distributes these tasks to registered Worker Nodes for execution. Workers do not pull job definitions, they execute the tasks assigned to them by the Leader.
A collection job is typically made up of one or more tasks that: discover the data to be fetched; fetch data that match the run filter; and finally, pass the results either through the Routes or (optionally) into a specific Pipeline and Destination.
Collector Changes
A key difference in how Collectors work relates to when configuration changes are applied. Unlike many other configurations, certain Collector modifications do not require a Commit & Deploy to take effect.
Leader-Scheduled Collectors
For the following Collector types, the job definition is managed entirely on the Leader Node:
- REST/API Endpoint
- Database
- Health Check
Any changes made to the configuration of these Collectors - such as updating a URL, adding a field, or changing a query - are applied on the next scheduled run automatically. No Commit & Deploy is needed for the Collector’s own configuration. This is because the Leader always uses its current, saved configuration to generate tasks for Workers at execution time.
For all other Collector types not listed above, changes require a Commit & Deploy to be propagated to the Worker Nodes.
Dependencies Require Commit & Deploy
While the job definition for a Leader-scheduled Collector doesn’t need to be deployed, any dependencies it relies on do. If your Collector job references Knowledge objects like Event Breakers, Pipelines, or Lookups, those objects must be deployed to the Workers.
If you update a dependent object but fail to deploy it, the collection job will fail with an error, such as “missing event breaker.”
Advanced Collector Configuration
You can edit the configuration of an existing Collector. Or, you can create a new Collector from a template. A template is just a Collector configuration file (in JSON, as usual) intended to copied and edited.
Editing an Existing Collector
When configuring the Collector, click Manage as JSON on the Configure tab.
Cribl Stream will open a JSON editor.
Edit the Collector as desired.
(Optional) If you want to make the Collector configuration available locally, click Export.
When JSON configuration contains sensitive information, it is redacted during export.
Click OK to exit the Manage as JSON modal.
Finish configuring the Collector and click Save.
Create a New Collector from a Template
You can create a new Collector from a template like those in Cribl’s Collector Templates repository.
For many popular Collectors, the Collector Templates repository provides configurations (with companion Event Breakers, and event samples in some cases) that you can import into your Cribl Stream instance, saving the time you’d have spent building them yourself. For many Collectors, you will need to import both the Collector itself (a
collector.jsonfile) and its Event Breaker (abreaker.jsonfile). See the Event Breakers topic for instructions on how to import them.
Collector configurations can contain placeholders defined in the form <Label|Description>, where Label is the input field label and Description is the tooltip text. The Cribl Stream JSON editor makes it easy to work with placeholders, as you’ll see in the following procedure and placeholders example.
Click Manage as JSON at the bottom of the New Collector modal.
Cribl Stream will open a JSON editor.
Import the Collector configuration (that is, the template) using either of the two following methods:
Import method: If your desired Collector configuration file is available locally, click Import, navigate to the file, select it, and click Open.
Copy and paste method: If your desired Collector configuration file is open in a local text editor, or is in a Git repository, copy the file. (In the Cribl’s Collector Templates repo, navigate to the
collector.jsonfile in the desired Collector’s folder, then click the copy icon.) Back in the JSON text editor, paste the Collector configuration.
If the template contains placeholders:
- If you used the import method, Cribl Stream will open the Replace Placeholder Values modal.
- If you used the copy and paste method, click OK to open the modal.
Enter desired values for any fields defined as placeholders.
(Optional) Edit the configuration further as desired.
(Optional) If you want to make the Collector configuration available locally, click Export.
When JSON configuration contains sensitive information, it is redacted during export.
Click OK to exit the Manage as JSON modal.
Finish configuring the Collector and click Save.
Placeholders Example
Here’s an example where the configuration defines placeholders for fields named Client ID and Client Credentials:
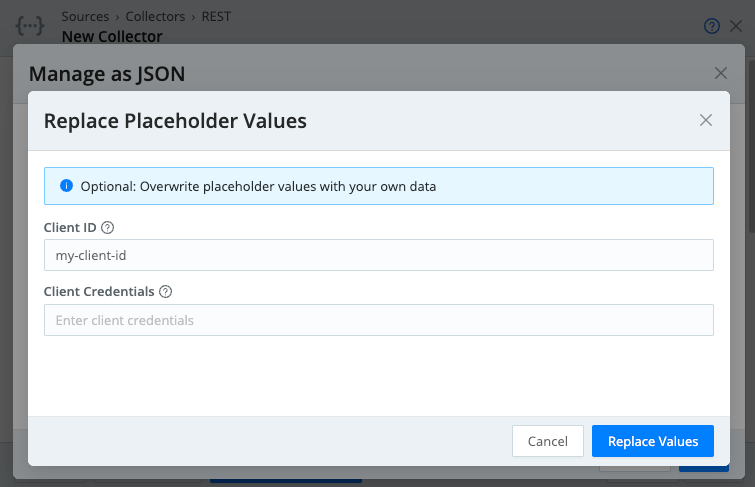
Filling in fields is optional; if you leave a field empty, its placeholder will remain in the JSON configuration, and you can enter a value later.
Scheduled Collection Jobs
You might process data from inherently non-streaming sources, such as REST endpoints, blob stores, and so on. Scheduled jobs enable you to emulate a data stream by scraping data from these sources in batches, on a set interval.
You can schedule a specific job to pick up new data from the source - data that hadn’t been picked up in previous invocations of this scheduled job. This essentially transforms a non-streaming data source into a streaming data source.
Collectors in Distributed Deployments
In a Distributed deployment, you configure Collectors at the Worker Group level, and Worker Nodes execute the tasks. However, the Leader Node oversees the task distribution, and tries to maintain a fair balance across jobs.
When Workers ask for tasks, the Leader will normally try to assign the next task from a job that has the least tasks in progress. This is known as “Least-In-Flight Scheduling,” and it provides the fairest task distribution for most cases. If desired, you can change this default behavior by opening Group Settings > General Settings > Limits > Jobs, and then setting Job dispatching to Round Robin.
More generally: In a Distributed deployment, you configure Collectors and their jobs on individual Worker Groups. But because the Leader manages Collectors’ state, if the Leader instance fails, Collection jobs will fail as well. (This is unlike other Sources, where Worker Groups can continue autonomously receiving incoming data if the Leader goes down.)
Monitor and Inspect Collection Jobs
Select Monitoring > System > Job Inspector to view and manage pending, in-flight, and completed collection jobs and their tasks.
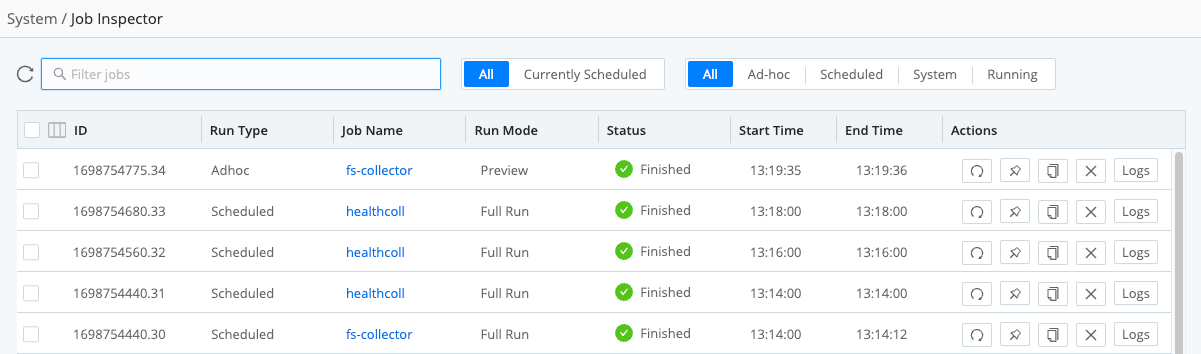
Here are the options available on the Job Inspector page:
All vs. Currently Scheduled tabs: Click Currently Scheduled to see jobs forward-scheduled for future execution - including their cron schedule details, last execution, and next scheduled execution. Click All to see all jobs initiated in the past, regardless of completion status.
Job categories (buttons): Select among Ad-hoc, Scheduled, System, and Running. (At this level, Scheduled means scheduled jobs already running or finished.)
Group selectors: Select one or more check boxes to display action buttons at the bottom of the table, like Pause and Resume.
Sortable headers: Click any column to reverse its sort direction.
Search bar: Click to filter displayed jobs by arbitrary strings.
Action buttons: For finished jobs, the icons (from left to right) indicate: Rerun; Keep job artifacts; Copy job artifacts; Delete job artifacts; and Display job logs in a modal. For running jobs, the options (again from left to right) are: Pause; Stop; Copy job artifacts; Delete job artifacts; and Live (show collection status in a modal).
Monitor Job Artifacts
Collection jobs create artifacts that include internal accounting data about the job execution process and log files. Because the artifacts have limited value after the job is completed, the system automatically deletes them when they exceed configured limits. This process is called “artifact reaping”.
To monitor collection job artifacts that are being reaped,
you can enable debug logging for the JobArtifactReaper logging channel.
The system will then log the reason why the artifacts were reaped.
To do this, set logging level for JobArtifactReaper to debug.