



Distributed Deployment
Cribl Stream Distributed deployment is a multi-instance deployment that is fit for large data volumes and increased processing.
In a Distributed deployment, a single Leader Node manages all Worker Nodes and is responsible for tracking and monitoring their activity metrics, keeping configurations in sync, and handling version control.
The following topics explain more high-level concepts related to Distributed deployment:
- To facilitate authoring and management of configuration settings for a particular set of Worker Nodes as a group, see Worker Groups.
- To plan for unexpected outages in Distributed deployments, see Leader High Availability/Failover.
For detailed deployment requirements, see OS and System Requirements, and for details on managing Cribl Stream, see Run Cribl Stream.
Concepts
Review the following basic concepts as a first step toward understanding how a Distributed deployment works.
Single instance: A single Cribl Stream instance, running as a standalone (not distributed) installation on one server.
Leader Node: A Cribl Stream instance that runs in Leader mode. You use the Leader Node to centrally monitor and author configurations for the Worker Nodes in a Distributed deployment.
Worker Node: A Cribl Stream instance that runs as a managed Worker. The Leader Node fully manages the configuration of each Worker Node. (By default, the Worker Nodes poll the Leader for configuration changes every 10 seconds.)
Worker Group: A collection of Worker Nodes that share the same configuration. You map Workers to a Worker Group using a Mapping Ruleset.
- Use multiple Worker Groups to make your configuration reflect organizational or geographic constraints. For example, you might have a US Worker Group, an APAC Worker Group, and an EMEA Worker Group, each with their own distinct certifications and settings.
Worker Process: A Linux process within a Single Instance, or within Worker Nodes, that handles data inputs, processing, and output. The process count is constrained by the number of physical or virtual CPUs available; for details, see Sizing and Scaling.
Mapping Ruleset: An ordered list of filters used to map Workers Nodes into Worker Groups.
Options and Constraints
You can manually change the local configuration on a Worker Node, but changes won’t persist on the filesystem. To permanently modify the configuration of a Worker Node, save and commit it, and then deploy it from the Leader Node. See Deploy Stream Configurations.
With certain license tiers, you can configure Permissions-based or Role-based access control at the Worker Group level. Non-administrator users can access Workers only within the Worker Groups on which they’re authorized.
Architecture
Here’s a visual overview of a distributed Cribl Stream deployment.
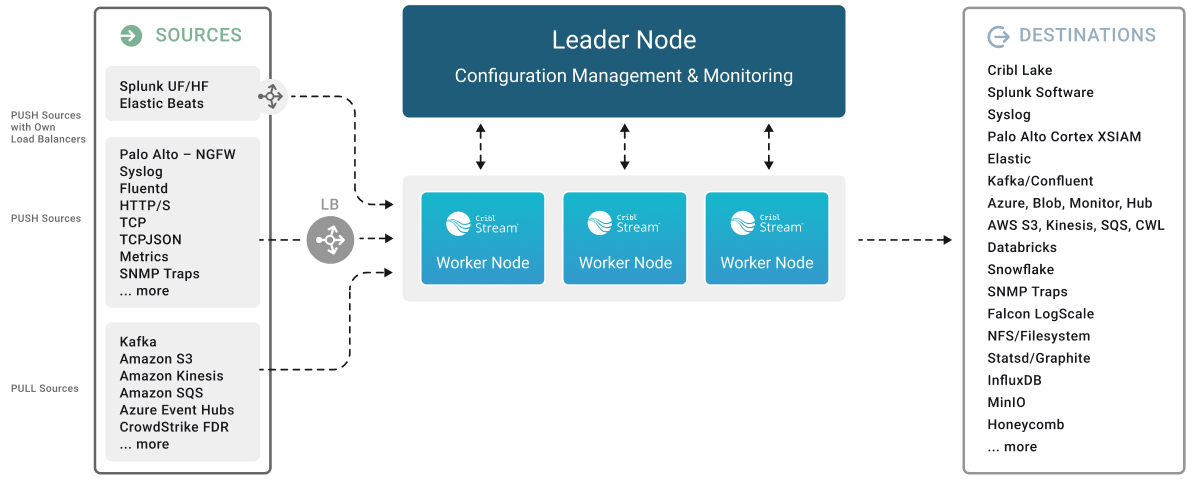
The division of labor among components of the Leader Node and Worker Nodes in a Distributed deployment is as follows:
Leader Node
- API Process: Handles all the API interactions.
- Config Helpers: One process per Worker Group. Helps with maintaining configurations, previews, etc.
Worker Nodes
- API Process: Handles communication with the Leader Node (that is, with its API Process) and handles other API requests.
- Worker Processes: Handle all the data processing.
For comparison, the division of labor on a Single-instance deployment is simpler, because the Leader Node and Worker Nodes are essentially condensed into one stack:
- API Process: Handles all the API interactions.
- Worker Processes: Handle all data processing.
- One Worker Process in a Cribl Stream deployment has a dual role: it processes data like other Worker Processes and assists the Leader Node in managing configurations. The API Process functions similarly to a Leader Node’s API Process, handling API requests and responses. Other Worker Processes operate as standard Worker Nodes, primarily focused on data processing.
How Worker Nodes and the Leader Node Work Together
The Leader Node has two primary roles:
It serves as a central location for the operational metrics of Worker Nodes. The Leader Node contains a monitoring console that includes dashboards that cover almost every operational aspect of the deployment.
It authors, validates, deploys, and synchronizes configurations across Worker Groups.
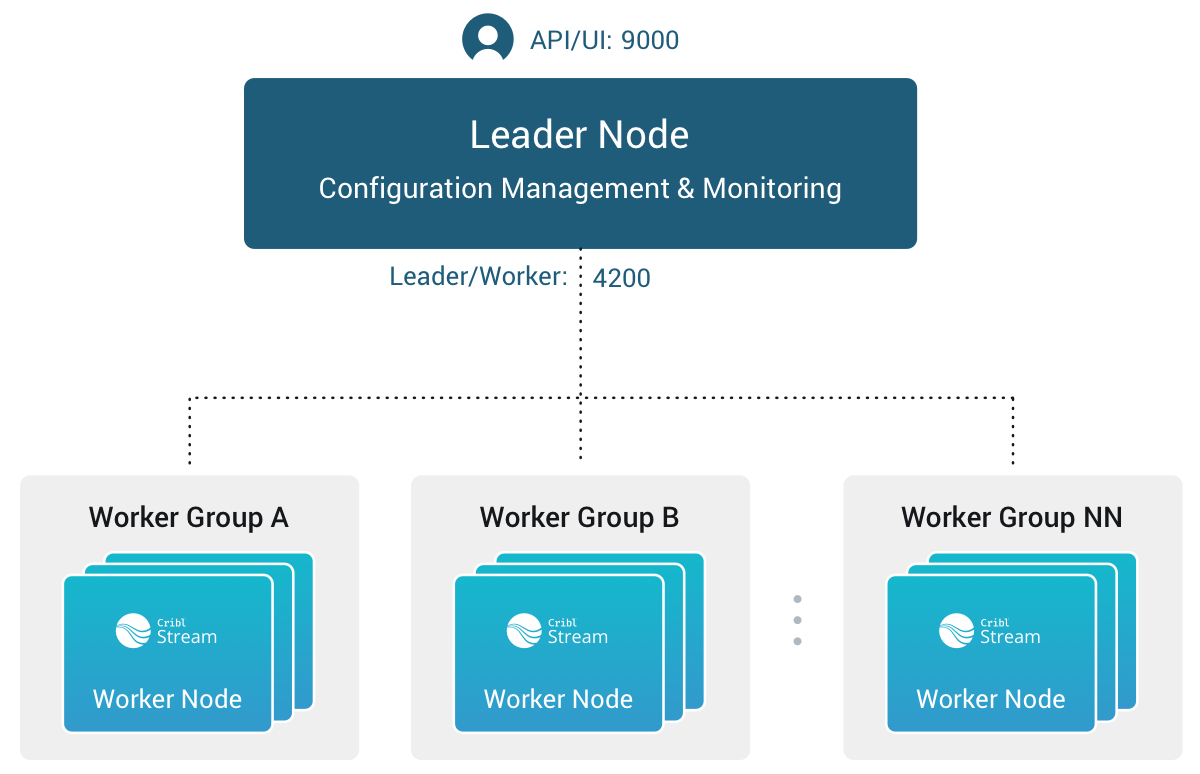
Network Port Requirements (Defaults)
The following are the default network port requirements.
- UI access to Leader Node: TCP 9000.
- Worker Node to Leader Node: TCP 4200. Used for Heartbeat/Metrics/Leader requests/notifications to clients (for example: live captures, teleporting, status updates, config bundle notifications, and so on).
- Worker Node to Leader Node: HTTPS 4200. Used for config bundle downloads.
Communication
Worker Nodes periodically (every 10 seconds) send a heartbeat to the Leader Node. This heartbeat includes information about the Worker Nodes and a set of current system metrics. The heartbeat payload includes facts - such as hostname, IP address, GUID, tags, environment variables, current software/configuration version, etc. - that the Leader Node tracks with the connection. If a Worker Node fails to successfully send two consecutive heartbeats, it is removed from the Workers page until the next time Leader Node receives a heartbeat message from it.
When a Worker Node checks in with the Leader Node:
- The Worker Node sends heartbeat to Leader Node.
- The Leader Node uses the Worker Node’s configuration, tags (if any), and Mapping Rules to map it to a Worker Group.
- The Worker Node gets its Worker Group’s updated configuration bundle, if necessary.
Persistent Socket Connections for Leaders
Distributed deployments use Unix domain socket files on the Leader for inter-process communication between internal services. On most Linux distributions, system cleaners periodically delete files in /tmp. If socket files under /tmp are removed, certain product pages stop working until the Leader is restarted and the sockets are recreated.
Configure socket protection as part of your initial Leader installation. See Persistent Socket Connections for options to:
- Stop the host from cleaning
/tmp/cribl-*socket files. - Move socket files to a protected directory using the Helper processes socket dir setting on the Leader.
In-Flight Data Safeguarding
If a Worker Node goes down, it loses any data that it’s actively processing. With streaming senders (Push Sources), Cribl Stream normally handles that data only in-memory. So, to minimize the chance of data loss, configure persistent queues on Sources and/or Destinations that support it.
Leader/Worker Dependency
If the Leader Node goes down, Worker Groups can continue autonomously receiving and processing incoming data from most Sources. They can also continue executing Collection tasks already in process.
However, if the Leader Node fails, future scheduled Collection jobs will also fail. So will data collection on the Amazon Kinesis Data Streams, Prometheus Scraper, and all Office 365 Sources, which function as Collectors.
Workers GUID on Host Image or VM
When you install and first run the software, Cribl Stream generates a GUID that it stores in a .dat file located in CRIBL_HOME/local/cribl/auth, e.g.:
$ cat /opt/cribl/local/cribl/auth/676f6174733432.dat
{"it":1647910738,"phf":0,"guid":"e0e48340-f961-4f50-956a-5153224b34e3","lics":["license-free-3.4.0-XYZ98765"]}When deploying Cribl Stream as part of a host image or a virtual machine, be sure to remove this file, so that you don’t end up with duplicate GUIDs. Cribl Stream will regenerate the file on the next run.
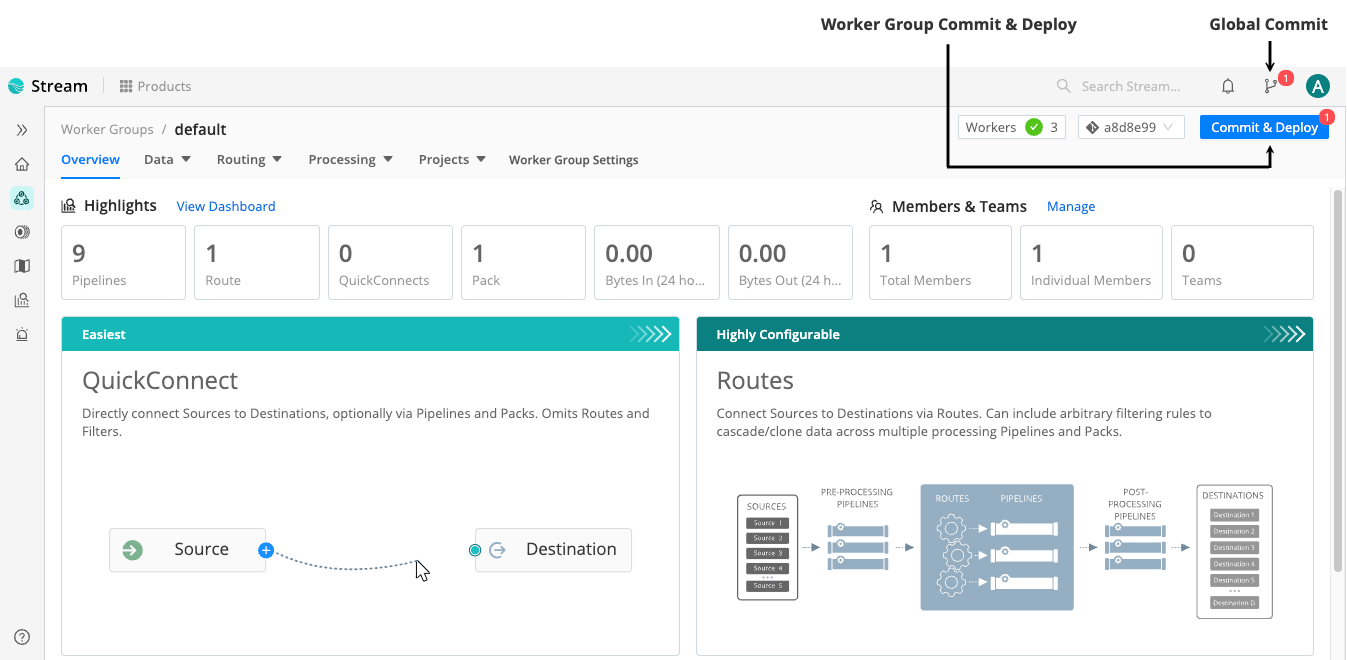
Commit and Deploy Controls
Distributed mode includes Worker Group-specific Commit and Deploy controls. These controls function differently from the global Commit button because they have a different scope.
The global Version Control button:
- Scope: Commits changes for all Worker Groups and the Leader Node simultaneously.
- Result: Changes are versioned but not deployed.
The Worker Group Commit and Deploy buttons:
- Scope: Commits and deploys changes for only the currently selected Worker Group.
- Result: Allows for a single-click Commit and Deploy, making changes live for that specific group immediately.
These controls will appear slightly differently depending on whether you have changes committed but not yet deployed, and on whether you’ve enabled the Collapse actions setting.
For details, see Version Control.
Manage Workers and Worker Groups
To manage your Cribl Stream deployment’s resources, use the Worker and Worker Group management features.
Manage Worker Groups
To manage Worker Groups, in the sidebar, select Worker Groups.
This opens the Worker Groups landing page, where you can view summary of information for each Worker Group and select it to view its Worker Nodes.
Manage Workers
To manage Worker Nodes, in the sidebar, select Workers.
The Workers tab provides status information for each Worker Node in the selected Worker Group. An Auto-refresh toggle (on by default) ensures that the Config Version automatically refreshes when you commit or deploy. (This option is available in Cribl Stream 4.4 and newer and appears only in Worker Groups that contain fewer than 100 Worker Nodes.)
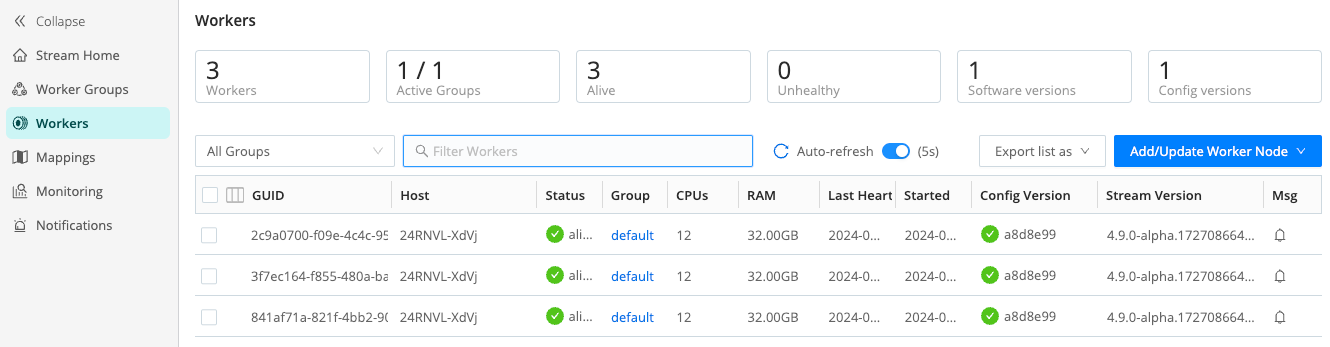
If you see unexpected results here, keep in mind that:
- Worker Nodes that miss 5 heartbeats, or whose connections have closed for more than 30 seconds, will be removed from the list.
- For a newly created Worker Group, the Config Version column can show an indefinitely spinning progress spinner. This happens because the Worker Nodes are polling for a config bundle that has not yet been deployed. To resolve this, select Deploy to force a deploy.
To export the list of Worker Nodes, select the Export list as drop-down.
Select JSON or CSV as the export file format. If a list has any filters
applied, the exported list will also be filtered. To export an entire list,
remove any applied filters.
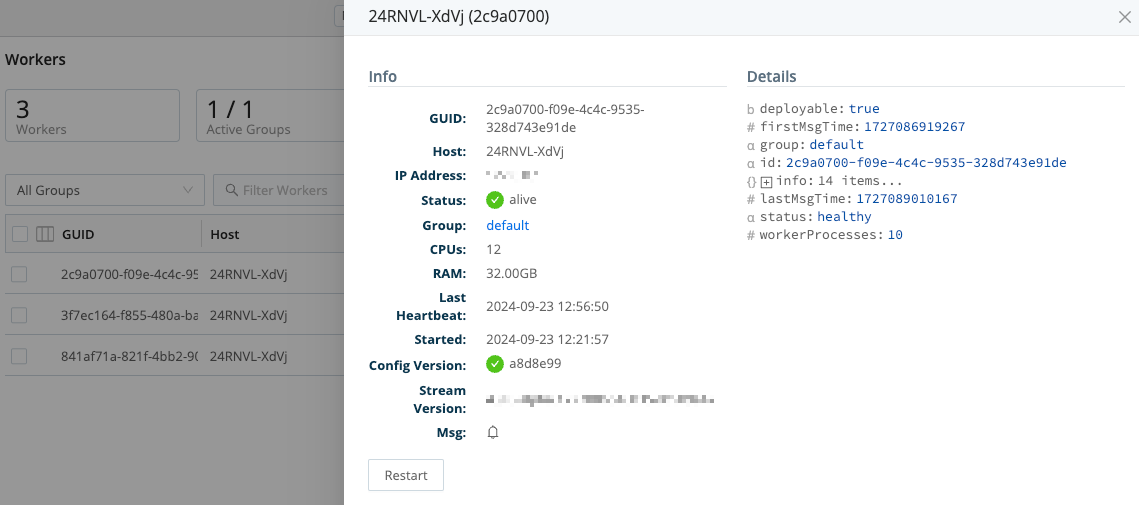
To reveal more details about a Worker Node, click anywhere on its row.
Manage Mappings
The Mappings page displays status and controls for the active Mapping Ruleset.
To manage your mapping rulesets, select Mappings in the sidebar.
Select a Mapping Ruleset ID to manage and preview its rules.
Auto-Scale Workers and Load-Balance Incoming Data
If data flows in via load balancers, make sure to register all instances. Each Cribl Stream Node exposes a health endpoint that your load balancer can check to make a data/connection routing decision.
| Health Check Endpoint | Healthy Response |
|---|---|
curl http://<host>:<port>/api/v1/health | {"status":"healthy"} |