



Single-Instance/Basic Deployment
Getting started with Cribl Stream on a single instance
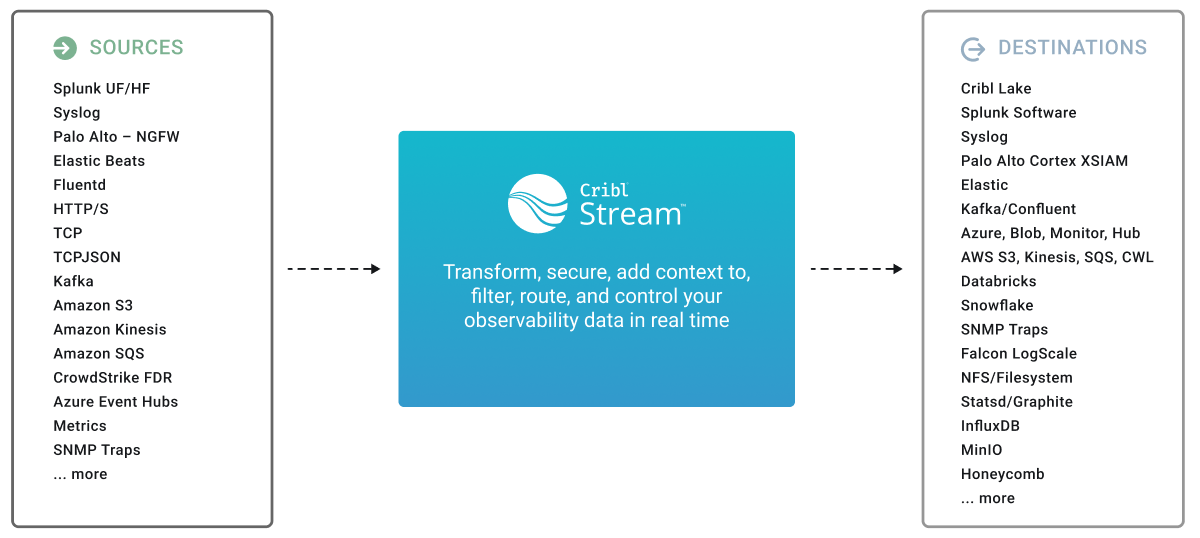
For small-volume or light processing environments - or for test or evaluation use cases - a single instance of Cribl Stream might be sufficient to serve all inputs, event processing, and outputs. This page outlines how to implement a single-instance deployment.
Architecture
Install on Linux
For system requirements, see OS and System Requirements. To launch Cribl Stream in compliance with secure Federal Information Processing Standards (FIPS), see FIPS Mode.
- Install the package on your instance of choice. Download it here.
- Ensure that required ports are available (see Network Ports).
- Un-tar in a directory of choice, e.g., in the
/opt/directory:tar xvzf cribl-<version>-<build>-<arch>.tgz
To prevent issues with Cribl file operations,
/opt/cribland all its subdirectories must reside on the same device. Mounting separate devices within/opt/criblis not recommended. For external storage needs, such as lookups or Persistent Queues (PQs), create a completely separate directory outside of/opt/cribl. While/opt/criblis the default installation path, Cribl can be installed to other locations if necessary.
Install Cribl Stream and Cribl Edge on the Same Host
You can run an Edge Node with a Leader that is managing Cribl Stream, or an Edge Node and a Worker Node on the same host. For details, see Installing Cribl Edge and Cribl Stream on the Same Host.
Next, refer to the Run Cribl Stream topic for details on managing Cribl Stream.