



These docs are for Cribl Edge 4.0 and are no longer actively maintained.
See the latest version (4.17).
Parser
The Parser Function can be used to extract fields out of events, or to reserialize (rewrite) events with a subset of fields. Reserialization will maintain the format of the events.
For example: If an event contains comma-delimited fields, and fieldA and fieldB are filtered out, those fields’ positions will be set to null, but not deleted completely.
Parser cannot remove fields that it did not create. A subsequent Eval Function can do so.
Usage
Filter: Filter expression (JS) that selects data to feed through the Function. Defaults to true, meaning evaluate all events.
Description: Simple description about this Function. Defaults to empty.
Final: If toggled to Yes, stops feeding data to the downstream Functions. Defaults to No.
Operation mode: Extract will create new fields. Reserialize will extract, filter fields, and then reserialize.
Type: Parser/Formatter type to use. Options:
- CSV
- Extended Log File Format
- Common Log Format
- Key=Value Pairs
- JSON Object
- Delimited Values
- Regular Expression
- Grok
Setting Type to Delimited Values displays the following extra options:
- Delimiter: Delimiter character to split value. Defaults to comma (
,). You can also specify pipe (|) or tab characters. - Quote char: Character used to quote literal values. Defaults to
". - Escape char: Character used to escape delimiter or quote characters. Defaults to:
\ - Null value: Field value representing the null value. These fields will be omitted. Defaults to:
-
Library: Select an option from the Parsers Library. Although specifying a Library will auto-generate an example list of fields, the list may still need to be modified to accommodate the desired fields from the events as well as the actual field order.
Source field: Field that contains text to be parsed. Not usually needed in Reserialize mode.
Destination field: Name of field in which to place the extracted and serialized fields. If the field already exists, it will be overwritten. If multiple new fields are created and this setting is configured then all new fields are created as elements of an array with the array name set to the name specified for this setting. If you want all new fields to be independent, rather than in an array, then specify them using List of fields below. (Extract and Reserialize modes only.)
Clean fields: This option appears for Type: K=V Pairs. Toggle to Yes to clean field names by replacing non-alphanumeric characters with _. This will also strip leading and trailing " symbols.
List of fields: Fields expected to be extracted, in order. If not specified, Parser will auto-generate fields.
Fields to keep: List of fields to keep. Supports wildcards (*). Takes precedence over Fields to remove. Supports nested addressing. See details below.
Fields to remove: List of fields to remove. Supports wildcards (*). Cannot remove fields matching Fields to keep. Supports nested addressing. See details below.
Fields filter expression: Expression to evaluate against each field’s {index, name, value} context. Return truthy to keep fields, or falsy to remove fields. Index is zero-based. See details below.
Advanced Settings
Allowed key characters: Enter characters permitted in a key name, even though they are normally separator or control characters. Separate entries with a tab or hard return. This setting does not affect how the value is parsed.
Allowed value characters: Enter characters permitted in a value name, even though they are normally separator or control characters. Separate entries with a tab or hard return. This setting does not affect how the key is parsed.
Fields/Values Interaction
This Function’s Filter, Type, Fields to keep, Fields to remove, and Fields filter expression settings interact as follows.
Order of Evaluation
The order is: Fields to keep > Fields to remove > Fields filter expression.
Precedence
If a field is in both Fields to keep and Fields to remove, Fields to keep takes precedence.
If a field is in both Fields to remove and Fields filter expression, Fields to remove takes precedence.
Negation
Both Fields to remove and Fields to keep support negated terms. When you use negated terms, your fields list is order-sensitive. E.g., !foobar, foo* means “All fields that start with foo, except foobar.” However, !foo*, * means “All fields, except for those that start with foo.”
Characters to Escape
Particular characters need special treatment when parsed in (respectively) Key=Value Pairs and CSV modes.
Key-Value Pairs
When a Parser Function’s Type is set to Key=Value Pairs: Within your data, field values that contain an = delimiter must be surrounded by quotes ("..."), or the Function will return unexpected results. As an example, here is a set of four fields and values, in which two values are quoted to parse predictably:
one=1,two="value=2",three=3,four="value=4"
These would resolve to the following parsed values:
| Field Name | Value |
|---|---|
one | 1 |
two | "value=2" |
three | 3 |
four | "value=4" |
CSV
When a Parser Function’s Type is set to CSV: Within your data, column values that contain quotes or commas must quote those characters, or the Function will return unexpected results. To illustrate this, here is a properly formatted example of four CSV values:
"value with ""escaped"" quotes is 1",2,3,"you know, this is 4"
The first value includes quotation marks, which are each escaped with surrounding quotes, and the whole value is delimited by outer quotes. The fourth value includes a comma, so that value is delimited by outer quotes. These four columns would cleanly evaluate to:
value with “escaped” quotes is 1
2
3
you know, this is 4
Example 1
Insert the following sample, using Sample Data > Import Data:
2019/06/24 05:10:55 PM Z a=000,b=001,c=002,d=003,e=004,f=005,g1=006,g2=007,g3=008
Create the following test Parser Function.
First, set the Type to Key=Value Pairs.
Scenario A:
Keep fields a, b, c. Drop the rest.
Expected result: a, b, c
- Fields to Keep:
a,b,c - Fields to Remove:
* - Fields Filter Expression: <empty>
Result: The event will gain four new fields and values, as follows.
- a:
000 - b:
001 - c:
002 - cribl_pipe:
parser2
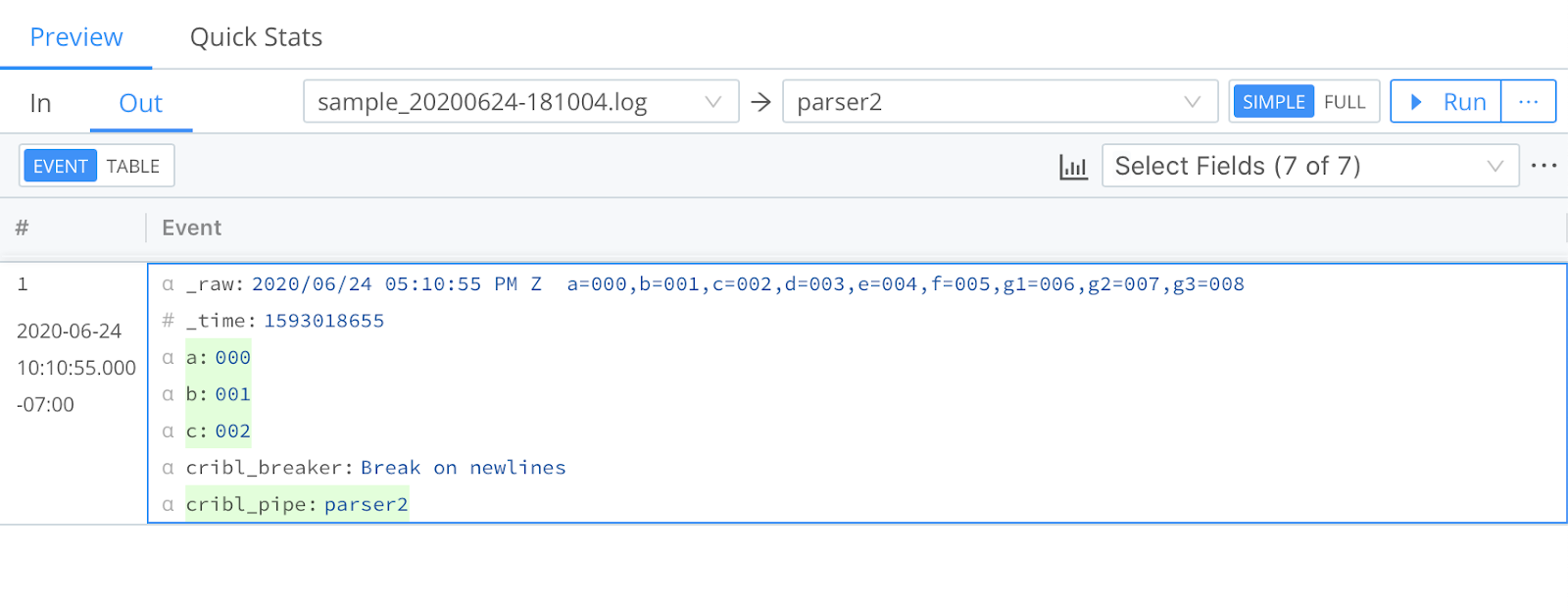
You can check your stats by clicking the Preview pane’s Basic Statistics (chart) button. In the resulting pop-up, the Number of Fields should have incremented ty four.
Now that you have the hang of it, try out the other simple scenarios below.
Scenario B:
Keep fields a, b, those that start with g. Drop the rest.
Expected result: a, b, g1, g2, g3
- Fields to keep:
a,b - Fields to remove: [empty]
- Fields filter expression:
name.startsWith('g')
Scenario C:
Keep fields a, b, those that start with g but only if value is 007. Drop the rest.
Expected result: a, b, g2
- Fields to keep:
a,b - Fields to remove: [empty]
- Fields filter expression:
name.startsWith('g') && value=='007'
Scenario D:
Keep fields a, b, c, those that start with g, unless it’s g1. Drop the rest.
Expected result: a, b, c, g2, g3
- Fields to keep:
a,b,c - Fields to remove:
g1 - Fields filter expression:
name.startsWith('g')
Scenario E:
Keep fields a, b, c, those that start with g but only if index is greater than 6. Drop the rest.
Expected result: a, b, c, g2, g3
- Fields to keep:
a,b,c - Fields to remove: [empty]
- Fields filter expression:
name.startsWith('g') && index>6
The
indexrefers to the location of a field in the array of all fields extracted by this Parser. It is zero-based. In the case above,g2andg3haveindexvalues of7and8, respectively.
Example 2
Assume we have a JSON event that needs to be reserialized, given these requirements:
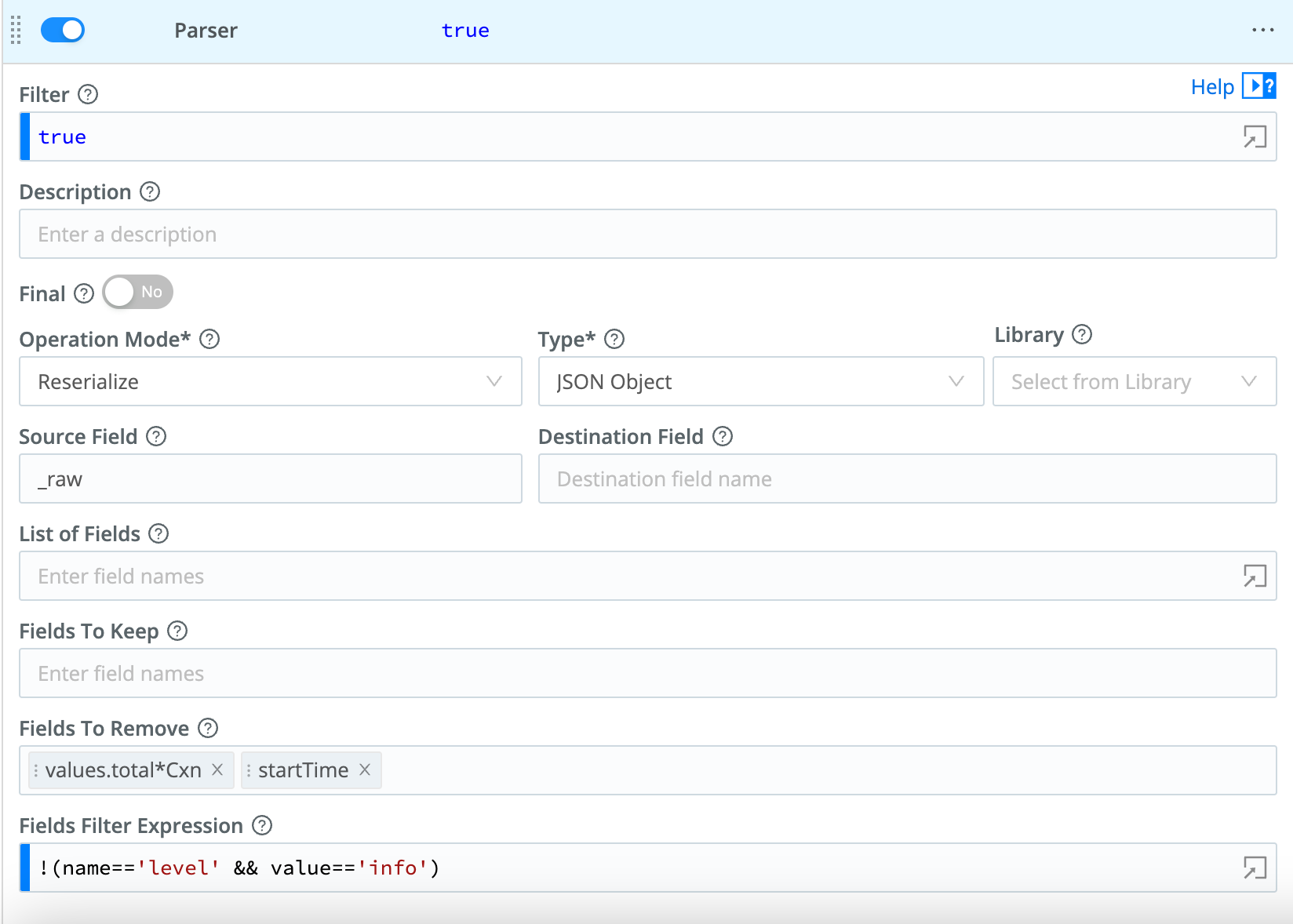
- Remove the
levelfield only if it’s set toinfo. - Remove the
startTimefield, and all fields in thevalues.total.path that end inCxn.
Parser Function configuration:

JSON event after being processed by the Function:

Example 3
Insert the following sample, using Sample Data > Import Data:
2019/06/24 15:25:36 PM Z a=000,b=001,c=002,d=003,e=004,f=005,g1=006,g2=007,g3=008,
For all scenarios below, first create a Parser Function to extract all fields, by setting the Type to Key=Value Pairs. Then add a second Parser Function with the configuration shown under Parser 2.
Scenario A:
Serialize fields a, b, c, d in CSV format.
Expected result: _raw field will have this value 000,001,002,003
Parser 2:
- Operation mode:
Serialize - Source field: [empty]
- Destination field: [empty]
- Type:
CSV - List of fields:
a,b,c,d(needed for positional formats)
Scenario B:
Serialize fields a, b, c in JSON format, under a field called bar.
Expected result: bar field will be set to: {"a":"000","b":"001","c":"002","d":"003"}
Parser 2:
- Operation mode:
Serialize - Source field: [empty]
- Destination field:
bar - Type:
JSON - List of fields: [empty]
- Fields to keep:
a,b,c,d