



These docs are for Cribl Edge 4.1 and are no longer actively maintained.
See the latest version (4.17).
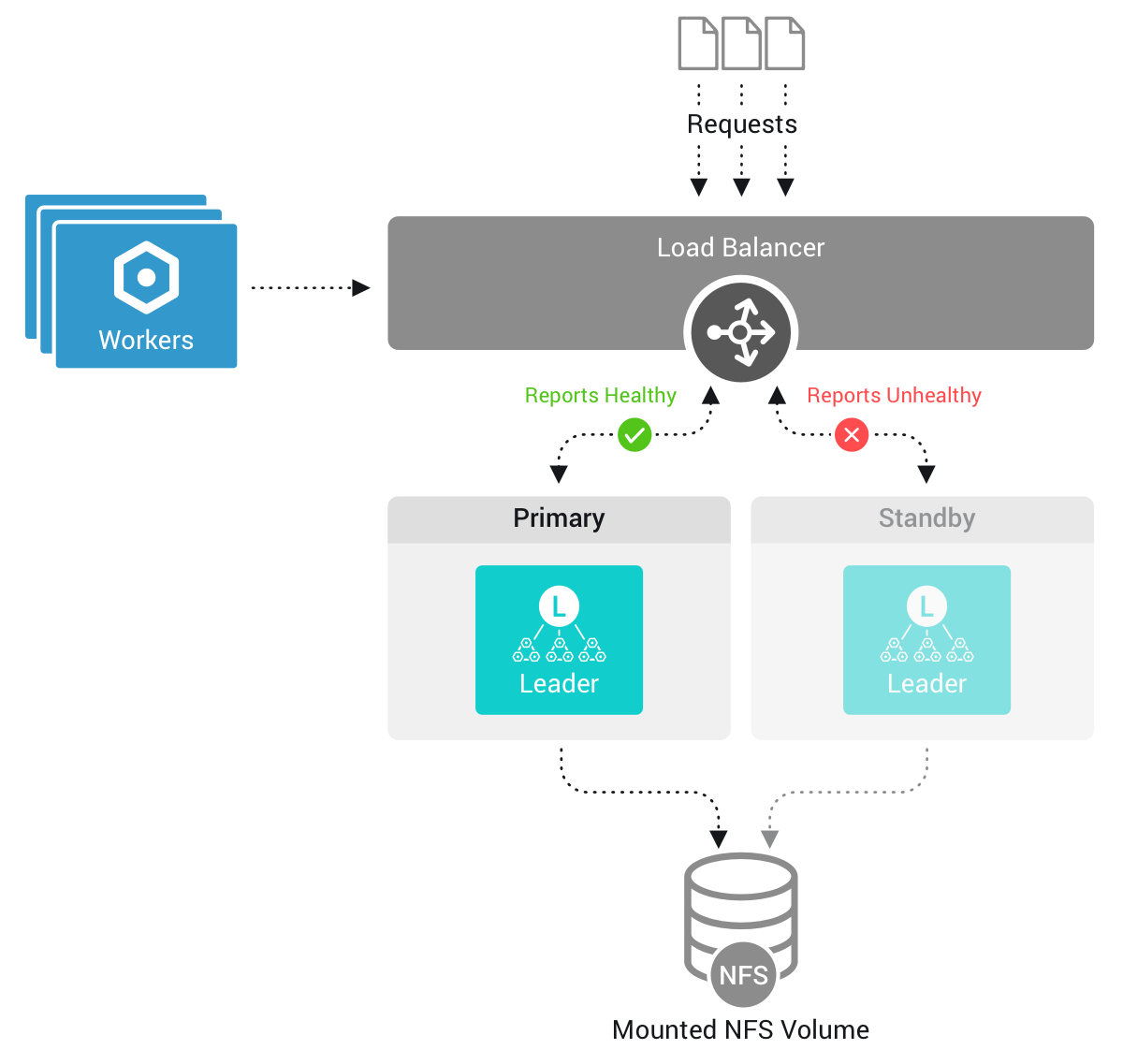
Leader High Availability/Failover
To handle unexpected outages in your on-prem distributed deployment, Cribl Edge 3.5 and above supports configuring a second Leader for failover. This way, if the primary Leader goes down, Collectors and Collector-based Sources can continue ingesting data without interruption.
For license tiers that support configuring backup Leaders, see Cribl Pricing.
How It Works
When you configure a second Leader, there will be only one active Leader Node at a time. The second Leader Node will be used only for failover. For this architecture to work, you must configure all failover Leaders’ volumes to point at the same Network File System (NFS) volume/shared drive. During the transition to a High Availability Leader setup, Cribl Edge automates the data migration process. By configuring the failover: volume: /path/nfs setting in the YAML configuration (or UI), all necessary files are automatically copied to the specified failover directory.
If the primary Leader Node goes down:
- Cribl Edge will recover by switching to the standby Leader Node.
- The new Leader Node will have the same configs, state, and metrics as the previous Leader Node.
- The Edge Nodes connect to the new Leader.
Required Configuration
Before adding a second Leader, ensure that you have the configuration outlined in this section.
Auth Tokens
Make sure that both Leaders have matching auth tokens. If you configure a custom Auth token, match its value on the opposite Leader.
- In the UI, check and match these values at each Leader’s Settings > Global Settings > Distributed Settings > Leader Settings > Auth token.
- Or, from the filesystem, check and match all Leaders’ instance.yml >
mastersection >authTokenvalues.
(If tokens don’t match, Edge Nodes will fail to authenticate to the alternate Leader when it becomes active.)
NFS
- On all Leader Nodes, use the latest version of the NFS client. NFSv4 is required.
- Ensure that the NFS volume has at least 100 GB available disk space.
- Ensure that the NFS volume’s IOPS (Input/Output Operations per Second) is ≥ 200. (Lower IOPS values can cause excessive latency.)
- Ensure that ping/latency between the Leader Nodes and NFS is < 50 ms.
You can validate the NFS latency using a tool like
ioping. Navigate to the NFS mount, and enter the following command:ioping .For details on this particular option, see the ioping docs.
NFS Mount Options
The Leader Node will access large numbers of files whenever you use the UI or deploy configurations to Cribl Edge Edge Nodes. When this happens, NFS’s default behavior is to synchronize access time updates for those files, often across multiple availability zones and/or regions. To avoid the problematic latency that this can introduce, Cribl recommends that you add one of the following NFS mount options:
relatime: Update the access time only if it is more than 24 hours ago, or if the file is being created or modified. This allows you to track general file usage without introducing significant latency in Cribl Edge. To do the same for folders, add thereldiratimeoption.noatime: Never update the access time. (Cribl Edge does not need access times to be updated to operate correctly.) This is the most performant option - but you will be unable to see which files are being accessed. To do the same for folders, add thenodiratimeoption.
Load Balancers
Configure all Leaders behind a load balancer.
- Port
4200must be exposed via a network load balancer. - Port
9000can be exposed via an application load balancer or network load balancer.
Health checks over HTTP/HTTPS via the /health endpoint are only supported on port 9000. Load balancers that support such health checks include:
- Amazon Web Services (AWS) Network Load Balancer (NLB). Suitable for TCP, UDP, and TLS traffic.
- AWS Application Load Balancer (ALB). Application-aware, suitable for HTTP/HTTPS traffic.
- HAProxy.
- NGINX Plus.
AWS Network Load Balancers
If you need to access the same target through a Network Load Balancer, use an IP-based target group and deactivate client IP preservation. For details, see:
Source-Level Health Checks
For many HTTP-based Sources, you can enable a Source-level health check endpoint in the Advanced Settings tab. Load balancers can send periodic test requests to these endpoints, and a 200 OK response indicates that the Source is healthy.
Frequent requests to Source-level health check endpoints can trigger throttling settings. In such cases, Cribl will return a 503 Service Unavailable response, which can be misinterpreted as a service failure. A 503 response may indicate that the health checks are running too frequently instead of an actual service failure.
Recommended Configuration
Use the latest NFS client across all Leaders. If you are on AWS, we recommend the following:
- Use Amazon’s Elastic File System (AWS EFS) for your NFS storage.
- Ensure that the user running Cribl Edge has read/write access to the mount point.
- Configure the EFS Throughput mode to
Enhanced>Elastic. - For details on NFS mount options, see Recommended NFS mount options.
For best performance, place your Leader Nodes in the same geographic region as the NFS storage. If the Leader and NFS are distant from each other, you might run into the following issues:
- Latency in UI and/or API access.
- Missing metrics between Leader restarts.
- Slower performance on data Collectors.
Set the primary Leader’s Resiliency drop-down to Failover.
Configuring Additional Leader Nodes
You can configure additional Leader Nodes in the following ways. These configuration options are similar to configuring the primary Leader Node:
Remember, the
$CRIBL_VOLUME_DIRenvironment variable overrides$CRIBL_HOME.
Using the UI
In Settings > Global Settings > Distributed Settings > General Settings, select Mode:
Leader.Next, on the Leader Settings left tab, select Resiliency:
Failover. This exposes several additional fields.In the Failover volume field, enter the NFS directory to support Leader failover (e.g.,
/mnt/criblor/opt/cribl-ha). Specify an NFS directory outside of$CRIBL_HOME. A valid solution is to useCRIBL_DIST_MASTER_FAILOVER_VOLUME=<shared_dir>. See Using Environment Variables for more information.Optionally, adjust the Lease refresh period from its default
5s. This setting determines how often the primary Leader refreshes its hold on the Lease file.Optionally, adjust the Missed refresh limit from its default
3. This setting determines how many Lease refresh periods elapse before standby Nodes attempt to promote themselves to primary.Click Save to restart.
In Cribl Edge 4.0.3 and later, when you save the Resiliency:
Failoversetting, further Distributed Settings changes via the UI will be locked on both the primary and backup Leader. (This prevents errors in bootstrapping Workers due to incomplete token synchronization between the two leaders.) However, you can still update each Leader’s distributed settings by modifying its configuration files, as covered in the very next section.
Using the YAML Config File
In $CRIBL_HOME/local/_system/instance.yml, under the distributed section:
- Set
resiliencytofailover. - Specify a volume for the NFS disk to automatically add to the Leader Failover cluster.
distributed:
mode: master
master:
host: <IP or 0.0.0.0>
port: 4200
resiliency: failover
failover:
volume: /path/to/nfsNote that
instance.ymlconfigs are local, not on the shared NFS volume.
Using the Command Line
You can configure another Leader Node using a CLI command of this form:
./cribl mode-master -r failover -v /tmp/shared
For all options, see the CLI Reference.
Using Environment Variables
You can configure additional Leader Nodes via the following environment variables:
CRIBL_DIST_MASTER_RESILIENCY=failover: Sets the Leader’sResiliencytoFailovermode.CRIBL_DIST_MASTER_FAILOVER_VOLUME=<shared_dir>: Sets the location (e.g.,/mnt/cribl) of the NFS directory to support Leader failover.CRIBL_DIST_MASTER_FAILOVER_MISSED_HB_LIMIT: Determines how many Lease refresh periods elapse before the standby Nodes attempt to promote themselves to primary. Cribl recommends setting this to3.CRIBL_DIST_MASTER_FAILOVER_PERIOD: Determines how often the primary Leader refreshes its hold on the Lease file. Cribl recommends setting this to5s.
For further variables, see Environment Variables.
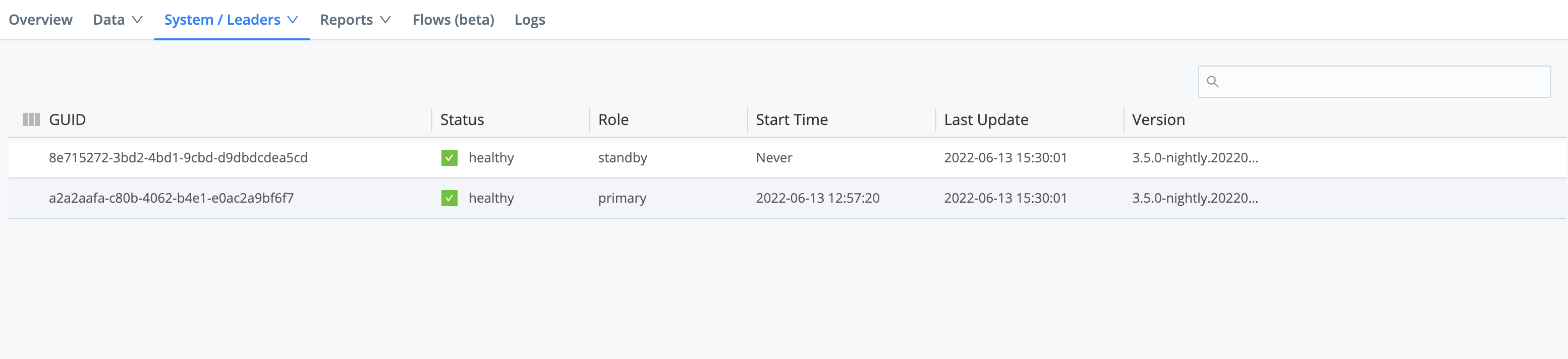
Monitoring the Leader Nodes
To view the status of your Leader Nodes, select Monitoring > System > Leaders.
Upgrading
When upgrading:
- Stop both Leaders.
- Upgrade (Stream, Edge) the Primary Leader, Second Leader, and then each Edge Node, respectively.
Disabling the Second Leader
Cribl recommends that you maintain a second Leader to ensure continuity in your on-prem distributed environment. Should you decide to disable it, contact support to assist you.
Addressing HA Migration Timeouts
When enabling High Availability (HA) mode on a production system with a lot of data, the process of moving that data can sometimes take longer than expected. If the system runs out of time during this move, it might only copy part of the data, which can cause problems when the system restarts.
To mitigate the risk of incomplete data transfers, temporarily increase the system’s transfer time prior to enabling HA. You can do this by adjusting a setting called TimeoutSec in the system’s configuration. Specifically, locate the Service section and add or modify the TimeoutSec directive. For example, set it to 600 seconds (10 minutes):
[Service]
TimeoutSec=600A successful data transfer will be confirmed by specific messages in the system’s log, such as:
{"time":"2025-02-17T22:01:46.295Z","cid":"api","channel":"ResiliencyConfigs","level":"info","message":"failover migration is complete"}
A failed migration due to timeout might show logs ending with a system shutdown, like this:
{"time":"2025-02-06T15:29:15.416Z","cid":"api","channel":"ShutdownMgr","level":"info","message":"Starting shutdown ...","reason":"Got SIGTERM","timeout":0}
After the HA setup is complete, revert the TimeoutSec setting to its original value. Leaving the timeout extended indefinitely can lead to prolonged leader downtime if a problem occurs during a future failover. Make sure to document the original setting before making changes to facilitate easy reversion.