



These docs are for Cribl Edge 4.7 and are no longer actively maintained.
See the latest version (4.17).
Parquet Schemas
Cribl Edge supports two kinds of schemas:
- Parquet schemas for writing data from a Cribl Edge Destination to Parquet files. This page outlines how to manage these in the UI at Knowledge > Parquet Schemas.
- JSON schemas for validating JSON events.
These schemas obviously serve different purposes. Beware of assuming that operations that work for one kind of schema can be used with the other. For example, the validation method for JSON schemas - C.Schema('<schema_name>').validate(<object_field>) - can’t be used to validate Parquet schemas.
Configuring Parquet Schemas
Destinations whose General Settings > Data format drop-down includes a Parquet option can write out data as files in the Apache Parquet columnar storage format.
When logging is set to debug, you will see what schema is associated with the Parquet files that Cribl Edge writes out. On Linux, you can use the Cribl Edge CLI’s parquet command to view a Parquet file, its metadata, or its schema.
If you turn on a Destination’s Parquet Settings > Automatic schema, Cribl Edge will automatically generate a Parquet schema based on the events of each Parquet file it writes. The automatically-generated schema preserves the exact structure of the ingested events, with no data lost. In Cribl Edge v.4.4.2, every field in the generated schema will have a data type of JSON, STRING, INT_64, UNSIGNED_INT_64, or DOUBLE.
(The one exception is the Amazon Security Lake Destination, where automatic schema generation is not relevant because Amazon Security Lake exclusively uses the OCSF Parquet schemas already available in the drop-down.)
Pros and Cons of Automatically Generated Parquet schemas
When you decide whether or not to generate Parquet schemas automatically, consider these pros and cons.
Advantages:
- Configuration is minimal.
- There’s no need to know how events you want to ingest are structured.
- There’s no need to change Parquet schema when event structure changes.
Disadvantages:
- Writing Parquet files takes longer than with predefined schemas. Note that schema complexity increases linearly with the number of events used to generate the schema.
- Automatically-generated Parquet schemas cannot be as fine-tuned as predefined ones, to capture certain nuances. For example, encoding will always be
PLAIN, compression will always beSNAPPY. - Some aspects of event structure (such as maps and sets) cannot be captured in the schema.
- Some aspects of time-related fields cannot be captured in the schema.
- Because the system produces a new Parquet schema for each file written, there may be differences between successive schemas. This can limit your ability to concatenate a collection of Parquet files.
Configuring Parquet Schemas
If you are not using automatic schema generation, or if there’s no pre-existing schema that suits your data:
Before configuring a Destination for Parquet output, you should add an existing Parquet schema, or create a new Parquet schema that suits the data you’re working with.
You do not need to start from scratch: Cribl provides sample Parquet schemas for you to clone and then customize as needed.
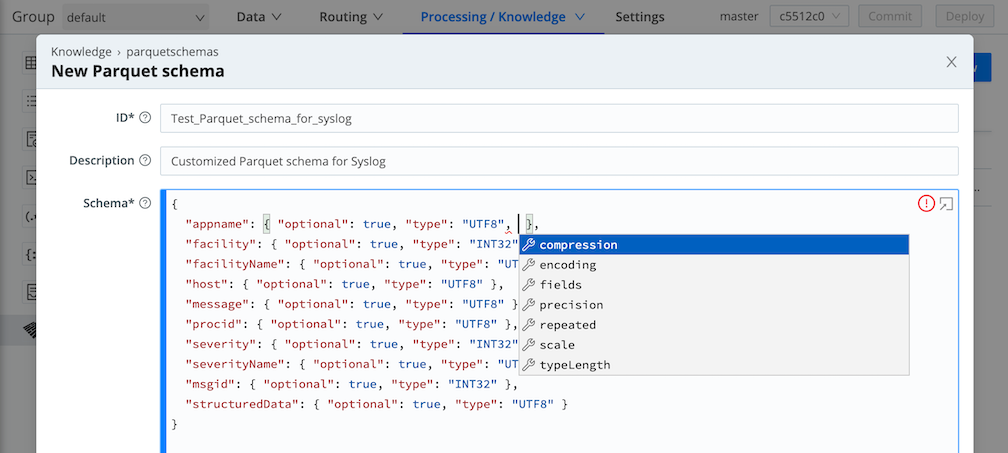
From the top nav, select Processing > Knowledge, then select the Parquet Schemas left tab.
If you’re adding a Parquet schema:
- Click Add Parquet schema to open the New Parquet schema modal.
If you’re cloning an existing Parquet schema to create a new schema:
- Click the name of the schema you want to start with, to open it in a modal.
- Click Clone Parquet Schema to open the New Parquet schema modal.
- Give the new schema a name and description.
From here, whether you’re working with a brand-new or cloned schema:
- Add and/or edit fields as desired.
- Click Save.
Now, when you configure your Destination, the schema you created will be available from the Parquet Settings > Parquet schema drop-down.
Creating/Modifying Parquet Schemas from Destinations
When the existing schemas on a Destination’s Parquet schema drop-down don’t meet your needs, follow this procedure to add or modify (clone) a new schema.
Navigate to the Parquet Schemaa Library at Processing > Knowledge > Parquet Schemas.
Add or modify the schema, as described above.
To modify an existing schema, Cribl strongly recommends that you first clone the schema, and give the clone its own distinct name. See Cloning Is Safer just below.
- Return to the Destination, and select the new or modified schema from the Parquet schema drop-down.
Cloning Is Safer than Modifying
Modifying an existing schema in the Schema Library does not propagate your modifications to the Destination’s copy of the schema.
Cloning and renaming schemas is the safest approach, because in Step 3 above, this ensures that your Destination will now use the newly modified version of the schema.
If you do not clone and rename the schema (i.e., you leave the schema name unchanged), you still must re-select the schema in the Destination’s Parquet schema drop-down to bring the modified version into the Destination.
Working with Parquet in Cribl Edge
Different Parquet readers and writers behave differently. Keep the following guidelines in mind when working with Parquet in Cribl Edge.
The Parquet Schema Editor
In the Parquet Schema editor, you express your Parquet schema in JSON. This does not look like the examples in the Parquet spec, which have their own syntax (like the repetition/name/type triple), but they are functionally equivalent. See the examples below.
The editor provides autocompletion and validation to guide you. (However, Cribl Edge currently does not fully support autocompletion on deeply nested schemas.)
File Extensions
For now, Cribl Edge can read Parquet files only if they have the extension .parquet, .parq, or .pqt.
Field Content
When Cribl Edge writes to a Parquet file:
If the data contains a field that is not present in the schema - i.e, an extra field - Cribl Edge writes out the parent rows, but omits the extra field.
If the data contains a field that is present in the Parquet schema, but whose properties violate the schema, Cribl Edge treats this as a data mismatch. Cribl Edge drops the rows containing that field - it does not write those rows to the output Parquet file at all.
If the data contains JSON, the JSON must be stringified. Otherwise, Cribl Edge treats this as a data mismatch, and does not write out the row. For example, this valid (but not stringified) JSON will trigger a data mismatch:
{ "name": "test"}.The same JSON in stringified form will work fine:
"{\"name\": \"test\"}".
Data Types
Cribl Edge supports:
- All primitive types.
- All logical types.
- All converted types.
Converted types have been superseded by logical types, as described in the Apache Parquet docs. Cribl Edge can read Parquet files that use converted types, but will write out the same data using corresponding logical types.
Repetition Type
You have three alternatives when defining a field’s Repetition type:
- Set
optionaltotrue. - Set
repeatedtotrue. - Set neither
optionalnorrepeated. This implicitly sets the Repetition type torequired, and it is the default.
Usage guidelines:
- Do not set both
optionalandrepeatedtotrue. - Do not use the
requiredkey at all. - Instead of omitting
optional, you have the option to include it, but set it tofalse. - Instead of omitting
repeated, you have the option to include it, but set it tofalse. - If any field’s Repetition type is
repeated, Cribl Edge represents this field as a single key whose value is an array - not as separate key-value pairs with identical keys.
Encodings
Among the
*DICTIONARYencodings, Cribl Edge supports onlyDICTIONARY. Trying to assign the unsupported encodingsPLAIN_DICTIONARYorRLE_DICTIONARYwill produce an error.BYTE_STREAM_SPLITencoding can be used only withDOUBLEorFLOATtypes, and otherwise produces errors.The
RLEand allDELTA*encodings also produce errors.
Parquet Schema Expressed as JSON
These examples should give you a hint of how to express Parquet schema in JSON. For a full explanation of the Parquet syntax, see the Parquet spec.
List Example
In this example, the whole schema is named the_list, and its structure consists of a container named list whose zero or more elements are each named element. Note that in Parquet schema, to specify that a field is nested (i.e., contains other fields), you just give it the type group.
message schema {
REQUIRED group the_list (LIST) {
REPEATED group list {
REQUIRED BYTE_ARRAY element (STRING);
}
}
}Expressed as JSON, the same schema is more spread-out, because to specify that a field is nested, you give it a sub-field named fields. (This is equivalent to declaring the nested field’s type as group.)
{
"the_list": {
"type": "LIST",
"fields": {
"list": {
"repeated": true,
"fields": {
"element": {
"type": "STRING"
}
}
}
}
}
}Map Example
In this example, the whole schema is named the_map, and its structure consists of a container named key_value whose zero or more pairs of elements each contain a key and a value element. Both the key and the value are strings in this case, but they could be other data types.
message schema {
REQUIRED group the_map (MAP) {
REPEATED group key_value {
REQUIRED BYTE_ARRAY key (STRING);
REQUIRED BYTE_ARRAY value (STRING);
}
}
}{
"the_map": {
"type": "MAP",
"fields": {
"key_value": {
"repeated": true,
"fields": {
"key": {
"type": "STRING"
},
"value": {
"type": "STRING"
}
}
}
}
}
}Array of Arrays Example
In this example, the whole schema is named array_of_arrays, and its structure consists of a container named list whose zero or more elements - which are themselves lists - are each named element. Within each of those element lists are one or more additional list/element structures.
message schema {
REQUIRED group array_of_arrays (LIST) {
REPEATED group list {
REQUIRED group element (LIST) {
REPEATED group list {
REQUIRED INT64 element;
}
}
}
}
}Expressed as JSON, the same schema is cumbersome to read compared to Parquet, which was designed to express nested structures concisely.
{
"array_of_arrays": {
"type": "LIST",
"fields": {
"list": {
"repeated": true,
"fields": {
"element": {
"type": "LIST",
"fields": {
"list": {
"repeated": true,
"fields": {
"element": {
"type": "INT64"
}
}
}
}
}
}
}
}
}
}Limitations
Cribl Edge does not support writing Parquet files which employ any of the following:
- Parquet Modular Encryption.
- The Parquet Bloom Filter.
- Separation of metadata and/or column data into multiple files.
Cribl Edge does not support reading or writing Parquet files which employ the deprecated INT96 data type.