



Manage Lake Datasets
Create, edit, partition, datatype, and delete Lake Datasets.
This page focuses on Lake Datasets that you populate from Cribl Stream using the Cribl Lake Destination. However, for selected types of data, you have the option to create and populate a Lake Dataset using Cribl Lake Direct Access.
You can also send Cribl Search results to Cribl Lake by using the Search
export operator. Data ingested from Search to Lake will typically have field names and values
pre-parsed, and this parsing is a prerequisite to achieving a Lakehouse performance boost.
You can maintain up to 200 Datasets per Cribl Lake instance (meaning, per Workspace).
Read on to learn how to manage your Lake Datasets:
- Create a New Lake Dataset
- Edit a Lake Dataset
- Delete a Lake Dataset
- Understand Lake Partitions and Lakehouse-Indexed Fields
- Datatypes for Lake Datasets
- Dataset Type for Search (v1 and v2)
- Choose a Lake Dataset Format
- S3 Storage Class for BYOS Datasets
Create a New Lake Dataset
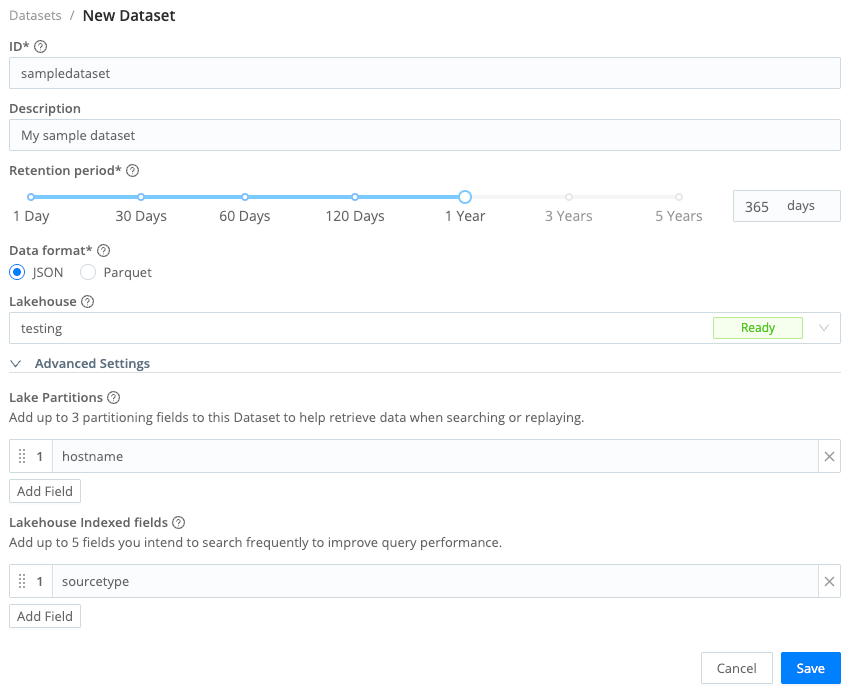
To create a new Lake Dataset:
In the Cribl Lake sidebar, select Datasets.
Select Add Dataset.
Enter an ID for the new Dataset.
The identifier can contain letters (lowercase or uppercase), numbers, and underscores, up to 512 characters.
You can’t change the identifier after a Dataset is created, so make sure it is meaningful and relevant to the data you plan to store in it.
The identifier must be unique and must not match any existing Cribl Search Datasets. Duplicate identifiers can cause problems when searching Cribl Lake data.
Optionally, enter a Description for the new Dataset.
Select a Storage Location. The internal
Cribl Lakestorage option is always available on this drop-down, and is the default location if you’ve configured no external Storage Locations. (Do not select an external Storage Location for a Dataset that you will populate via Direct Access.)If you selected an S3-backed Storage Location, optionally select a Storage Class for objects written to your bucket. The default is Standard. For details and search compatibility notes, see S3 Storage Class for BYOS Datasets.
Define the Retention period. Cribl Lake will store data in the Dataset for the time duration you enter here. The allowed range is anywhere from 1 day to 10 years.
Select the Data format. Keep the default JSON to prioritize storage efficiency. Choose Parquet to optimize for search performance. Read more: Choose a Lake Dataset Format and Structure Events for Cribl Lake.
DDSS is available for a Dataset that you will populate via Splunk Cloud Self Storage. The HTTP Ingestion Enabled check box will be automatically selected when you configure Direct Access (HTTP) to populate a Dataset.
Optionally, select the Lakehouse you want to link to the Dataset. When you select a Lakehouse at this point, the Lake Dataset will become a mirrored Dataset.
You can’t link Lakehouses to Datasets populated via Splunk Cloud Direct Access or those using an external Storage Location.
If you selected a Lakehouse, define the Lakehouse retention period. See Lakehouse Retention for more details.
Optionally, in Advanced Settings, select up to three Lake Partitions for the Dataset.
If you are linking the Dataset to a Lakehouse, then in Advanced Settings, you have the option to select up to five Lakehouse Indexed fields.
Confirm with Save.
You will now be able to select this new Dataset by using its identifier in a Cribl Lake Destination or Cribl Lake Collector.
Edit a Lake Dataset
To edit an existing Lake Dataset:
- In the Cribl Lake sidebar, select Datasets.
- Select the Dataset you want to edit and change the desired information, including description, Storage Location, retention period, partitions, linked Lakehouse, and (for S3-backed Storage Locations) Storage Class. You can’t modify the identifier of an existing Lake Dataset.
- Confirm with Save.
Change a Lake Dataset Retention Period
If you change the retention period of an existing Lake Dataset, this affects all data in the Dataset.
If you increase the retention period, data currently in the Dataset will adopt the new retention period.
Changing the retention period of the Dataset might affect the retention of its Lakehouse. If you decrease the Dataset retention below the current Lakehouse retention, the Lakehouse retention will be automatically reduced to match.
If you decrease the retention period, data older than the new time window will be lost. Make sure that this is your intention before you save the change.
Delete a Lake Dataset
To delete a Lake Dataset:
- In the Cribl Lake sidebar, select Datasets.
- Select the check box next to the Dataset(s) you want to delete.
- Select Delete Selected Datasets.
Scheduled Deletion
A Lake Dataset is not deleted instantly. Instead, after you select it for deletion, it will be marked with
Deletion in progress. In this state, you can no longer edit it, or connect it to Collectors or Destinations.
Data that is older than 24 hours will be removed the following day, after midnight UTC. Datasets are only deleted when all of the data in the dataset is 24 hours old or older. Once a Lake Dataset is marked for deletion, you will no longer be charged for any data that it contains.
You can’t delete built-in Lake Datasets, or Lake Datasets that have any connected Collectors or Destinations.
Understand Lake Partitions and Lakehouse-Indexed Fields
Each Lake Dataset can have up to three partitions configured, and, if you’re using a Lakehouse, up to five Lakehouse-indexed fields, to speed up searching and replaying data from Cribl Lake.
A typical use case for applying partitions and indexed fields is to accelerate hostname or sourcetype if you are
receiving data from multiple hosts or sources.
You can use partitions and indexed fields both in Search queries and in the filter for runs of the Cribl Lake Collector.
Which Fields to Use as Partitions and Indexed Fields?
To ensure that search and replay work best, make sure you provide broader partitions or Lakehouse-indexed fields first. The order in which you configure partitions or indexed fields for a Lake Dataset influences the speed of search and replay of the data.
We also do not recommend partitions or indexed fields that:
- Contain PII (personally identifiable information).
- Contain objects.
- Have a name starting with an underscore (such as
_raw).
For partitions, additionally avoid using fields that:
- Have high cardinality values.
- Are nullable (that is, can have the value of
null).
Don’t use
sourceordatasetas partitions or Lakehouse-indexed fields. These are internal fields reserved for Cribl, and are not supported as partitions/indexed fields.
Configure Datatypes for Lake Datasets
Lake Datasets, like regular Cribl Search Datasets, can be associated with Datatypes. Datatypes help separate Dataset data into discrete events, timestamp them, and parse them as needed.
The following applies on the Dataset Processing tab in Cribl Search (Datatype Rulesets). It is separate from Dataset Type v2 filter rows (glob plus Datatype ID on the Federated Dataset configuration), which map NDJSON and Parquet objects in Lake storage when you use Federated Search v2. See Dataset Type for Search (v1 and v2).
To configure Datatypes for a Lake Dataset:
- On the top bar, select Products, and then select Search.
- In the sidebar, select Data.
- In the list of Datasets select your Lake Dataset.
- Select the Processing tab.
- In the Datatypes list, add desired Rulesets via the Add Datatype Ruleset button. (The order of Rulesets matters.)
- When the list of Rulesets is complete, confirm with Save.
For more information about using Datatypes and Rulesets in searches, see Cribl Search Datatypes.
Select the Dataset Type for a Search (v1 and v2)
You choose a Dataset Type (v1 or v2) only in Cribl Search, on a federated Dataset that points at your
Lake Dataset through the Lake Dataset Provider (cribl_lake or equivalent). You’ll set the Dataset storage format, retention, partitions, and Lakehouse on the New Dataset window.
You’ll set the type of your Lake Dataset (v1 or v2) in Cribl Search.
- Dataset Type v2 supports Lake Datasets stored as JSON (newline-delimited JSON events) or Parquet.
- DDSS Lake Datasets support only Dataset Type v1. See Splunk Cloud Self Storage (DDSS) Direct Access.
See Dataset Type and filters for Lake Datasets for UI steps (including the Filters table on Type v2, where each row sets a Filter glob and Datatype ID). See Federated Search v2 for limits and migration guidance.
Choose a Lake Dataset Format
When you create a Lake Dataset, you can set its format to JSON, Parquet, or DDSS. Each format has specific use cases and performance characteristics.
For Dataset Type v2 in Search, JSON Lake Datasets store newline-delimited JSON objects and Parquet Lake
Datasets store Parquet files. On the federated Dataset, configure the Filters table so each row pairs a Filter
glob with a Datatype ID (for example generic_ndjson or cribl_lake_parquet). See
Dataset Type and filters for Lake Datasets. DDSS remains
Dataset Type v1 only.
To make the most of JSON or Parquet, preprocess your events in Cribl Stream. Learn more at Structure Events for Cribl Lake.
When to Use JSON
Set your Lake Dataset format to the default JSON when:
- You’re just getting started and want to explore Cribl Lake.
- Your data is semi-structured.
- You need a high level of compression, and ordinary search performance.
- You plan to store your original events in the
_rawfield (for compliance, or replay), and drop all other fields. - You’re more likely to retrieve full events, rather than specific fields.
When to Use Parquet
Set your Lake Dataset format to Parquet when:
- Your data is structured as events with multiple fields.
- You want to leverage columnar storage for better analytics performance.
- You expect your queries to filter and aggregate on specific fields.
We don’t recommend Parquet if you plan to store unstructured events, like CSV values, or only the _raw field in an
event. In this scenario, you will see no performance improvement over JSON.
When to Use DDSS
Set your Lake Dataset format to DDSS when you’re archiving data from Splunk Cloud using Self Storage. Learn more at Splunk Cloud Self Storage (DDSS) Direct Access.
S3 Storage Class for BYOS Datasets
When you create or edit a BYOS Dataset backed by an S3 Storage Location, you can select the S3 storage class that Cribl Lake uses when writing objects to your bucket. Choosing the right class upfront lets you optimize storage costs without relying on S3 lifecycle policies.
The Storage Class dropdown appears in the Datasets modal only for Lake Datasets attached to S3-backed Storage Locations. Managed Lake Datasets and Azure Datasets do not expose this setting.
Available Storage Classes for BYOS Datasets
Cribl Lake can write data to the following buckets for S3 BYOS:
| Storage Class | AWS Identifier | Notes |
|---|---|---|
| Standard | STANDARD | Default. General-purpose storage for frequently accessed data. |
| Intelligent-Tiering | INTELLIGENT_TIERING | Automatically moves objects between access tiers based on usage. |
| Standard-IA | STANDARD_IA | Lower cost for infrequently accessed data. Retrieval fees apply. |
| One Zone-IA | ONEZONE_IA | Like Standard-IA, but data is stored in a single Availability Zone. |
| Glacier Instant Retrieval | GLACIER_IR | Archival storage with millisecond retrieval. |
| Glacier Flexible Retrieval | GLACIER | Archival storage. Retrieval takes minutes to hours. |
| Glacier Deep Archive | DEEP_ARCHIVE | Lowest cost archival storage. Retrieval takes hours. |
The default storage class is Standard.
Objects written to Glacier Flexible Retrieval or Glacier Deep Archive cannot be searched on demand. Manual restoration in S3 is required before searching.
Changing the storage class on an existing Lake Dataset applies only to newly written objects. Cribl Lake does not modify or migrate existing objects in the bucket.
Search Compatibility
Cribl Search can read objects stored in the following classes: Standard, Intelligent-Tiering, Standard-IA, One Zone-IA, and Glacier Instant Retrieval. For more information, see Storage Classes.
Objects stored in Glacier Flexible Retrieval or Glacier Deep Archive are skipped at search time. To search those objects, restore them manually through the AWS S3 Console or API before running a search.
Storage Class in the API
The storage class is stored as a storageClass field in the Dataset configuration and is available through the Dataset
create and update API endpoints. Set storageClass to the AWS identifier for the class you want. If you omit the
field, the Dataset defaults to STANDARD. For an example, see
Attach a Dataset via API.