Emit LLM Cost and Usage Metrics from Token Counts
Turn per-request token usage and cost signals into metrics for financial analysis, alerting, and capacity planning. Most LLM instrumentation exposes prompt tokens, completion tokens, total tokens, and sometimes per-request or per-token cost. Use those fields when present, or estimate cost from token counts and your own pricing model.
Prerequisites
- Token (and optionally cost) fields present in your LLM spans, or a defined mapping from tokens to cost.
- A metrics Destination or SIEM that accepts the metric format you publish.
For example field names for tokens and cost, see LLM Telemetry Use Cases in Cribl.
Derive Cost and Publish Metrics
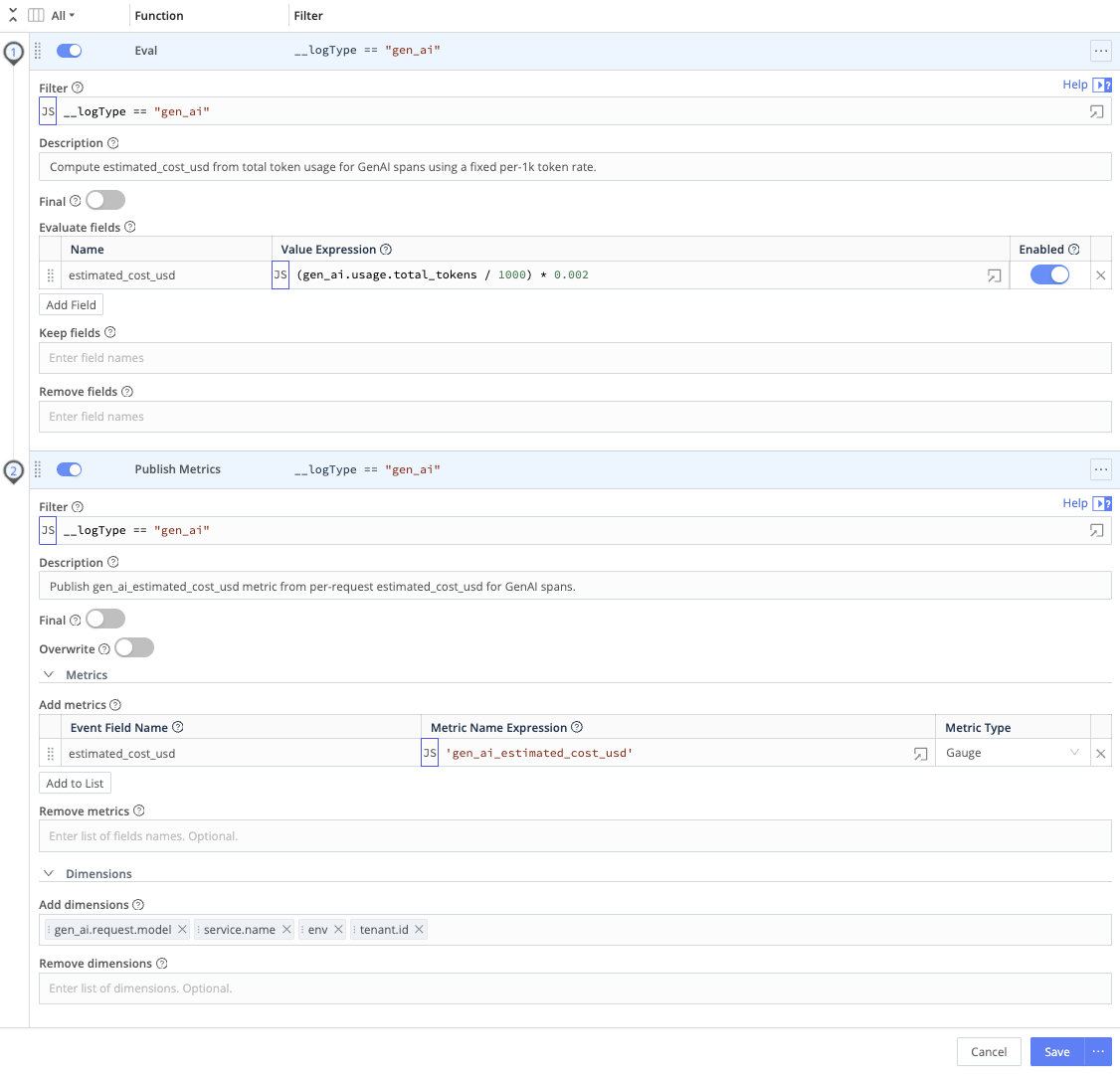
Use an Eval Function to derive cost or usage from token fields, then a Publish Metrics Function so downstream systems receive labeled metrics for FinOps and alerting.
- On the Route that handles your LLM spans, attach a Pipeline.
- Add an Eval Function that:
- Reads the total token count field from your telemetry.
- Applies your per-token rate (for example, a constant for USD per 1,000 tokens).
- Writes the result to a field such as
estimated_cost_usd, for exampleestimated_cost_usd = (total_tokens / 1000) * <your_per_1k_token_rate>.
- Add a Publish Metrics Function to:
- Emit
estimated_cost_usd(or your cost field) as a metric. - Add labels such as model name, application or service, environment (
env,deployment, or equivalent), and user or tenant identifiers where appropriate.
- Emit
- Send metrics to your metrics backend or SIEM.