



Sample or Throttle High-Volume LLM Telemetry
LLM workloads can produce large volumes of telemetry. Use sampling and filtering in Pipelines to keep what matters most: expensive requests, errors, guardrail activity, and representative samples of routine traffic–lowering noise and downstream storage and compute cost.
You might:
- Retain all spans where total tokens exceed a threshold.
- Sample low-token requests at a low rate.
- Always keep spans that show errors or guardrail activity.
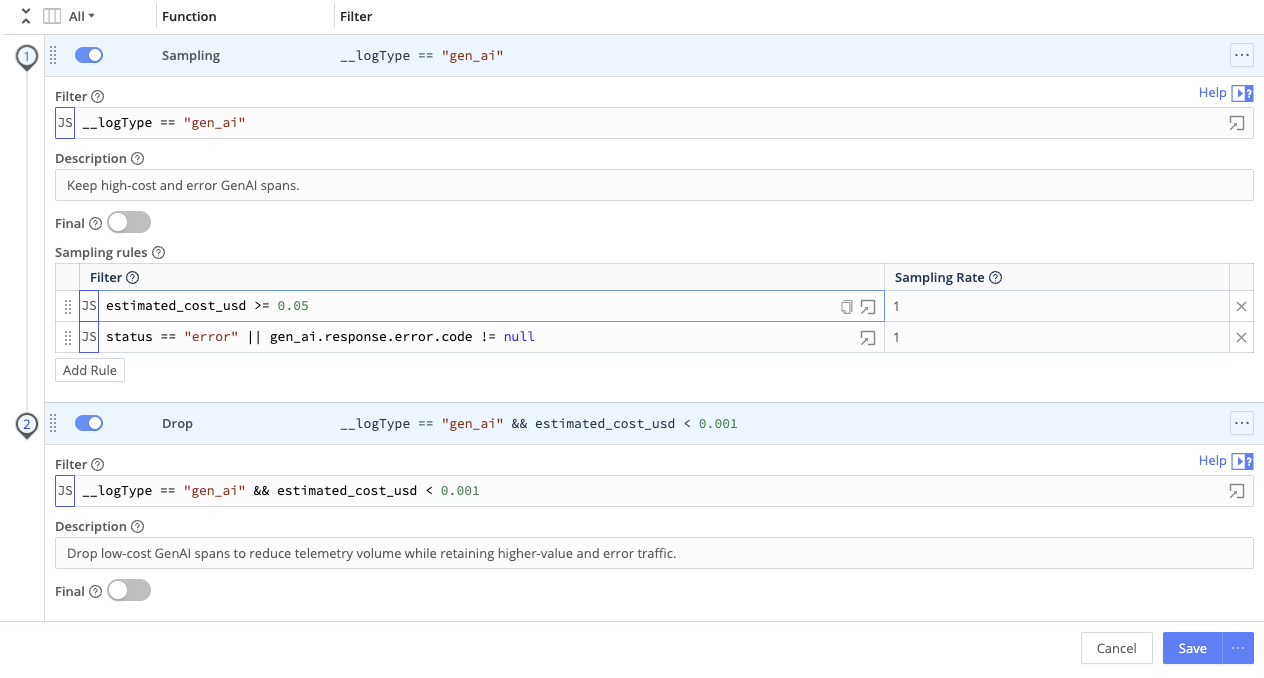
Use Sample and Drop Functions
Layer Sampling and Drop Functions in a Pipeline so you can keep errors, guardrail hits, and costly requests while trimming routine traffic.
- On the Route that handles your LLM spans, attach a Pipeline.
- Add Sampling Functions for probabilistic sampling, or Drop Functions for rule-based exclusion.
- Filter on token or cost fields (for example, total tokens per request, or per-request cost if available).
- Combine with other fields: service or application name, environment, user or tenant metadata, and error or status indicators.
This approach keeps full visibility into costly, anomalous, or security-relevant activity while trimming bulk low-signal events.
Prerequisites
- LLM spans that include token counts, cost, status, or other fields you can use in Filters.
- Agreement on sampling policies (for example, always keep errors, sample successes).
See LLM Telemetry Use Cases in Cribl for typical field names.