



The Cribl Three-Plane Model
The Cribl Data Engine is built on a three-tiered architectural model, consisting of a management plane, a control plane, and a data plane, all working together to manage, process, and route your data. Understanding this structure enables you to efficiently configure, troubleshoot, and securely scale the system, as it strictly separates user access, orchestration, and high-speed data flow.
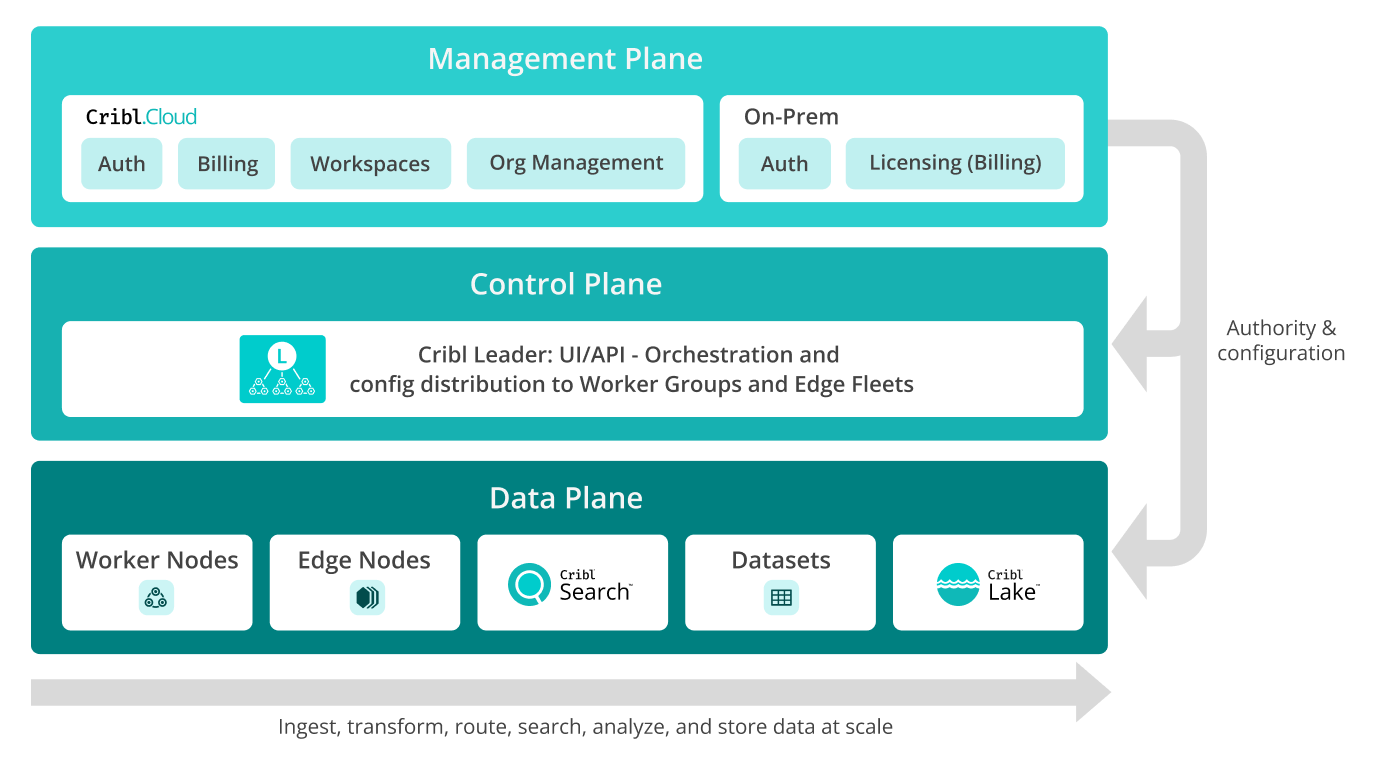
The Cribl three-plane model organizes the platform into distinct functional zones: Management for account-level orchestration; Control for centralizing UI/API configurations; and Data for the distributed processing and storage of events. This structure allows for independent scaling of administrative tasks and heavy-lift data operations.
Components of the Cribl Data Engine
You can think of Cribl products as operating on three planes: a management plane, control plane, and data plane.
Management Plane
Exclusive to Cribl.Cloud, the management plane includes the services required to:
- Create new Organizations (the account boundary for unique customers in Cribl.Cloud).
- Provide access-control and authorization services.
- Provision and manage Workspaces (unique VPC containers, each isolating an instance of the Cribl Product Suite).
- Manage billing, metering, and cost controls.
The management plane is largely independent of individual products and services.
Control Plane
The control plane, or Cribl Leader, is the collection of services that provide configuration management for each product in the Cribl Product Suite. The control plane provides the central UI and API experience for operating Cribl Stream, Edge, Search, and Lake.
The control plane coordinates configuration pushes for updating products and their components (such as Worker Groups and Fleets), based on user changes.
In Cribl Stream pull-based data collection, the control plane coordinates Collection jobs’ state and dispatching. In Cribl Search, the control plane coordinates operators for querying and returning data at rest.
Data Plane
The data plane identifies where Cribl products collect, process, query, and store data. The components here handle most of the activity across Cribl products.
Cribl Stream Data Plane
In Cribl Stream, the data plane is made up of the Workers. Workers operate in the following sequence:
Workers ingest data from various Sources (Push- or Pull-based Sources).
Workers then process this data using Pipelines to enrich, transform, reduce, and mask it.
Next, they route and distribute the data, based on the configured Routes, by sending it to external Destinations.
Cribl Stream Workers handle logs, metrics, traces, security events (SNMP), and custom data from REST-based collections.
Each Worker is designed to process several terabytes of data per day using a distributed, shared-nothing processing.
Distributed Processing
Cribl Workers distribute events across available Worker Processes (CPUs) available on each Worker. This architecture enables high-scale parallel processing of data, with high levels of availability and resilience. You can group Workers into Worker Groups with shared configurations. This allows for both vertical and horizontal scaling of common workloads.
Cribl Edge Data Plane
In Cribl Edge, the data plane is the Edge Node - a lightweight package of Cribl Edge core components, designed to be run on customer endpoints. These endpoints can be servers, cloud or datacenter VMs, or container nodes (such as ECS instances or Kubernetes nodes).
The Edge Node is an agent that collects data from the local filesystem, local APIs, and local system state. Edge offers processing, routing, and distribution capabilities similar to those in Cribl Stream, at lower overall volume (per endpoint scale), and with much lower resource requirements.
In typical deployments, a single Cribl Edge Node uses less than one physical CPU core for collection, processing, routing, and distribution. However, under sustained peak throughput, the Worker Process can utilize up to one full physical core. On systems with hyperthreading enabled, the OS metrics may attribute high utilization across the logical CPUs associated with the saturated core.
Cribl Search Data Plane
In Cribl Search, the data plane consists of on-demand compute resources called Operators in Cribl Search. The Cribl Control Plane coordinates the search process, dynamically executing the workload based on the user’s query and the Datasets being queried.
Operators return results to the Cribl control plane for analysis and visualization. Cribl operators can be dispatched to a variety of different Dataset Providers, including Amazon S3 cloud storage, APIs, structured data stores, the Cribl control plane, and Cribl Edge Nodes.
Cribl Lake Data Plane
In Cribl Lake, the data plane consists of the backing storage buckets for storing, querying, and replaying data. Cribl Lake uses open formats, backed by a variety of cloud storage providers.
Cribl Lake is composed of Datasets, which are unique partitions within a storage bucket. Partitions define the folder structure of the data, for ease of querying and organization. Cribl Lake Datasets define both the partition and the data’s retention period.