



CVA Decision Tree
This guide explains the key design questions you must answer to choose the right Cribl Validated Architecture (CVA) for your requirements. The goal is to use these considerations to logically narrow down a baseline topology and then select the necessary overlays.
By the end of this process, you will be able to define your architecture precisely, such as:
- “Our baseline topology is Distributed: Multi-Worker Group Regional/Geographic.”
- “We require Worker Group→Worker Group bridging and Replay-First as overlays.”
Interpret the CVA Decision Tree
The visual CVA Decision Tree functions as a structured guide to apply the architectural considerations detailed in the baseline topology and overalys sections. It formalizes the process of defining your CVA topology by leading you through a series of “Yes/No” questions.
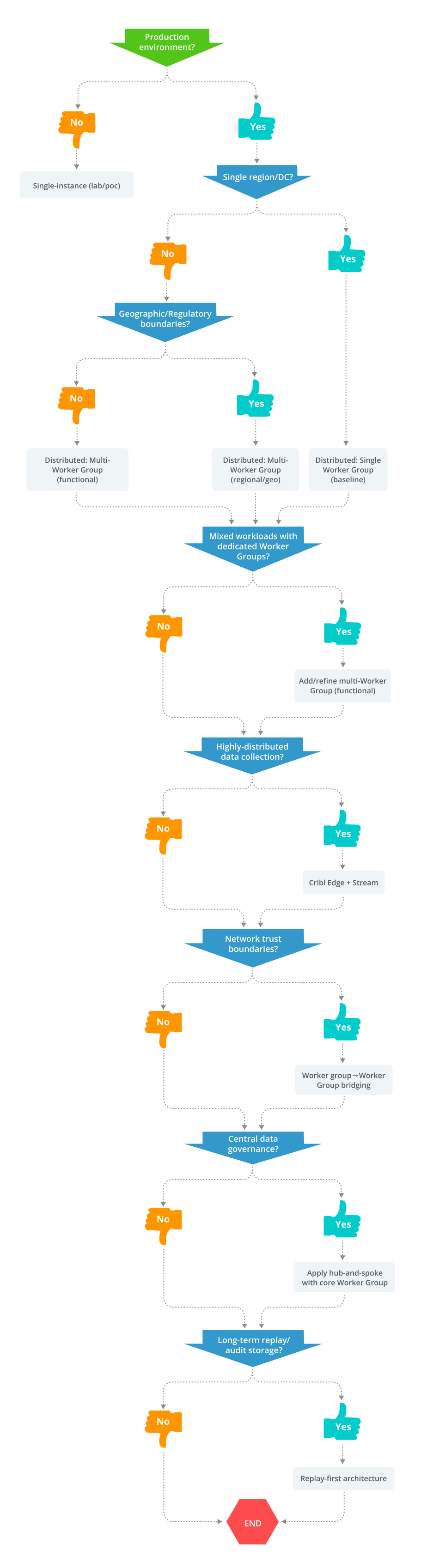
By following the “Yes” or “No” path for each decision, you logically arrive at the most appropriate combination of baseline topology and optional overlays.
The outcome of the CVA Decision Tree translates directly into your first set of architectural decisions. The first three decision points: environment, data locality, and boundaries define your foundational baseline topology.
Choosing your architecture is a funnel, not a menu. Follow these decisions in order; if your requirements are met by an earlier stage, you can stop there.
1. Baseline Topology Selection: The Core Decision Points
The first three considerations help you determine your foundational baseline topology.
1.1. Environment: Production vs. Non-Production
Decision Point:
- Is this a production environment?
- How much risk can the environment tolerate, and how painful would a rebuild be?
| Environment Type | Design Guidance | Baseline Topology |
|---|---|---|
| Non-Production (Labs, Dev/Test, PoCs) | Data loss/downtime is acceptable; minimal infrastructure is desired. | Single-Instance Topology |
| Production or Pre-Production | Requires predictable SLAs, high availability (HA), and clear disaster recovery (DR) strategy. | Distributed (Single Worker Group) Topology (Proceed to 1.2) |
For the Single-instance topology, avoid hard-coding local paths. Design routes for easy promotion to distributed topologies when ready.
1.2. Data Locality and Residency: Single-Region vs. Multi-Region
Decision Point:
- Are Sources and Destinations in a single region? Or,
- Do you have strong data residency/sovereignty requirements?
| Requirement | Design Guidance | Baseline Topology |
|---|---|---|
| Mostly single-region/DC | Operational simplicity is key; minimal residency rules apply. | Distributed (Single Worker Group) Topology |
| Multiple regions/DCs/countries | Cross-region egress cost, latency, or sovereignty is a concern. | Distributed (Multi-Worker Group/Fleet) proceed to 1.3 |
1.3. Boundaries: Geographic, Legal, or Functional Separation
Decision Point:
(Only applicable if you are deploying a Multi-Worker Group topology. How should those Worker Groups/Fleets be partitioned?)
- Do you need separation based on geographic, legal, or tenant boundaries, or by workload type?
| Boundary Requirement | Design Guidance | Baseline Topology |
|---|---|---|
| Functional/workload type only | Separation needed for technical reasons (for example, push vs pull data) within one legal/geographic domain. | Distributed (Multi-Worker Group/Fleet) with Functional Split overlay |
| Hard geographic/legal/tenant | Strict separation required (for example, EU vs US, separate BUs, on-prem vs cloud). | Distributed (Multi-Worker Group/Fleet) with Regional/Geo split overlay |
For the Distributed (Multi-Worker Group/Fleet), use one Worker Group per region (for example,
wg-us-east) plus an optional Core Worker Group for global aggregation.For the layout Distributed Multi-Worker Group, separate Worker Groups by function (for example, Push Worker Group, Pull/Collector Worker Group, Replay Worker Group). For details, see Functional Split overlay.
2. Overlays: Tailoring Your Architecture
Once you have a baseline, use the remaining considerations to select optional overlays that address specific operational, security, and governance needs.
2.1. Workload Separation and Interference
Consideration: Do heavy workloads (for example, replays, S3 pulls) interfere with low-latency traffic (for example, live syslog)?
- If interference occurs: Refine your baseline using the Distributed (Multi-Worker Group/Fleet) with Functional Split overlay. This involves moving push, pull, and heavy replay jobs to dedicated Worker Groups for independent scaling, maintenance, and tuning.
- If workloads are homogeneous: Keep the simpler Worker Group layout from your baseline.
2.2. Security and Trust Boundaries
Consideration: Does data cross hard network or trust boundaries (DMZ → Core, Vendor → Internal)?
- If hard boundaries exist: Apply the Worker Group to Worker Group Bridging overlay. Terminate raw Sources in a Source-facing Worker Group (for example, in the DMZ) and forward only normalized, filtered data to a core Worker Group using a governed bridge (Cribl HTTP/TCP). This defines an explicit, governed path across the boundary.
- If no hard boundaries: Route directly from Source-facing Worker Groups to Destinations.
2.3. Source Layout and Network Quality (Edge vs. Stream)
Consideration: Are Sources highly distributed, and are network links high-latency, expensive, or unreliable?
- If Sources are distributed/links are fragile: Apply the Cribl Edge and Stream overlay. Deploy Cribl Edge on remote hosts/sites for local collection, light filtering, and buffering. Forward from Cribl Edge to the nearest ingest/regional Worker Group (Cribl Stream) for heavy transformation and routing. This minimizes bandwidth use and adds resilience.
- If Sources are centralized/links are stable: You might not need to use Cribl Edge.
2.4. Governance Requirements: Central vs. Local Control
Consideration: Do you need a single, central place to enforce schemas, PII masking, and fan-out logic across many downstream systems?
- If strong central governance is required: Apply the Hub-and-spoke with Core Worker Group overlay. Spoke Worker Groups (regional/domain) handle initial ingest. A Core Worker Group acts as the “brain,” enforcing canonical schemas, masking rules, and enrichment and and distributing to Destinations (such as SIEMs, Cribl Lake).
- If governance is simple: A simpler regional/functional Worker Group layout is adequate.
2.5. Durability and Replay Strategy
Consideration: Is long-term, low-cost storage of full-fidelity data for compliance, forensics, and re-feeding a strategic requirement?
- If replay-first is strategic: Apply the Replay-First overlay. Land all/most data once into object storage (such as Cribl Lake or S3). Maintain only a slim real-time path. Use replay (via dedicated Worker Groups) to backfill, migrate, or run historical investigations, decoupling collection from Destination choices.
- If basic resilience is sufficient: Use persistent queues and short-term staging for limited replay, without a full replay-first design.