



Distributed (Multi-Worker Group/Fleet) Topology
The Distributed (Multi-Worker Group/Fleet) topology is the foundational blueprint for large-scale Cribl deployments that require logical segregation, independent scaling, and distinct configuration across different sets of data or workloads. It is the necessary evolution from the Single Worker Group when complexity or capacity limits are reached.
In this configuration, one Leader Node (or a high availability pair for resilience) manages two or more distinct Worker Groups/Fleets. Each Worker Group/Fleet acts as a primary scaling unit, comprising multiple Worker/Edge Nodes sized for N-1 capacity.
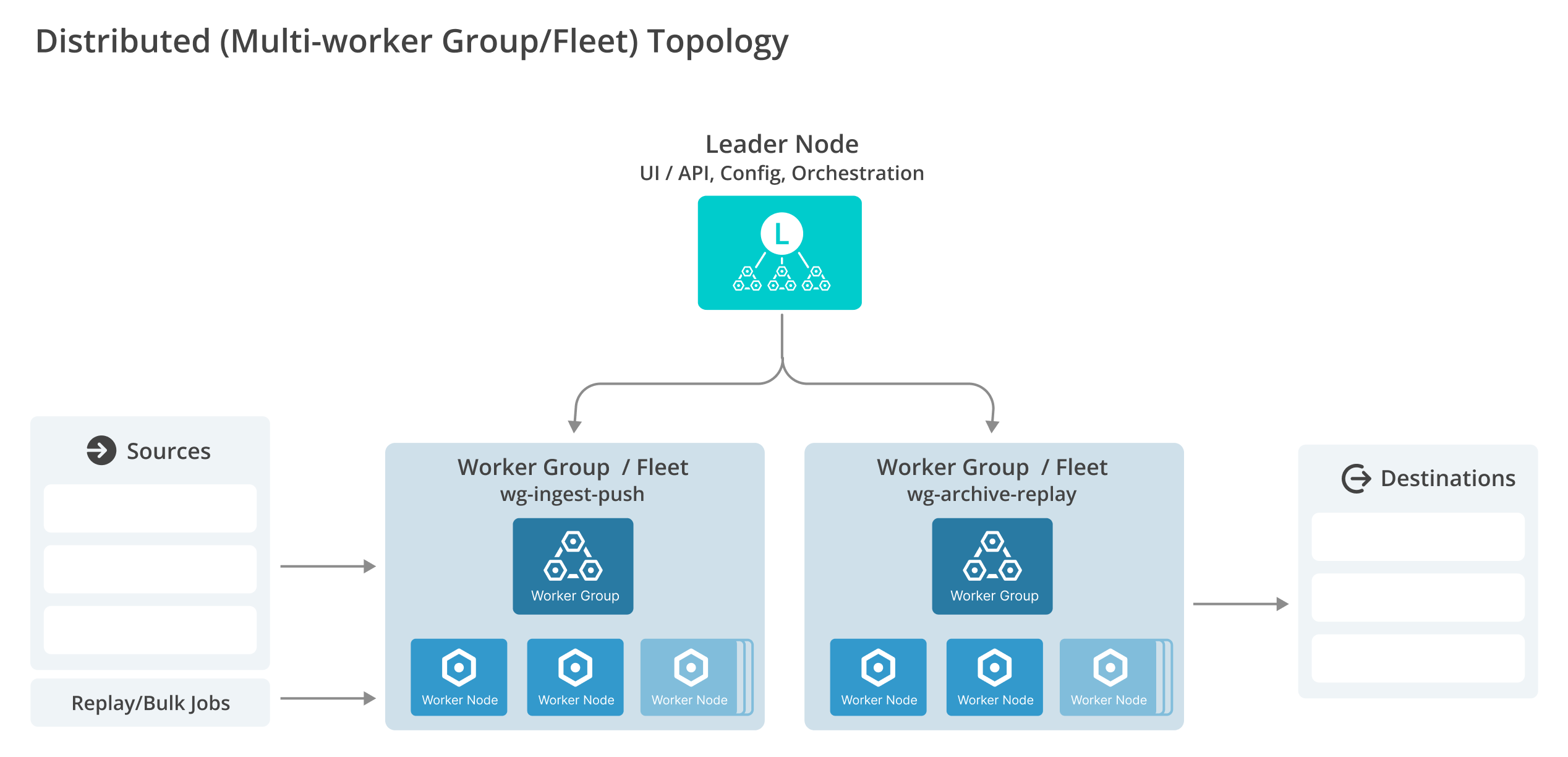
The diagram shows a Leader Node managing multiple Worker Groups, each containing multiple Worker Nodes for independent scaling and logical segregation.
When to Use This Topology
This foundational topology is necessary when your environment meets any of the following triggers, regardless of whether the division is functional or geographic:
- Boundary requirements: You need to enforce security, compliance, or multi-tenant boundaries that require physical or logical separation between different data streams or user domains.
- Workload interference: Diverse workloads (such as live ingest vs. bulk Replay) are competing for resources, necessitating dedicated, isolated groups to maintain service level objectives.
- Operational agility: Different teams or domains require independent change windows, separate configuration deployment schedules, or distinct operational ownership.
Design Guidelines
These guidelines focus on operational maturity and consistency that apply to any Multi-Worker Group/Fleet setup:
- Utilization monitoring: Implement accurate, per-Worker Group/Fleet utilization monitoring. Track critical metrics like CPU usage, memory consumption, queue depth, and connection counts. This is essential for determining precisely when and how to horizontally scale a specific Group/Fleet. For details, see Operational Monitoring.
- Consistency of event shape: Maintain a shared normalization layer across all Groups/Fleets. Use common Packs and Pipelines to ensure that event shape, field names, and timestamp formats are identical before the data reaches downstream Destinations, guaranteeing consistent quality.
- Document ownership: Clearly document the operational ownership and service level objectives for each Worker Group/Fleet. This aligns operational responsibility with specific performance targets (for example, “Security Team owns
wg-pci”). - Structured naming conventions: Use a structured naming convention for the Worker Groups/Fleets (such as
wg-ingest-push,wg-archive). This avoids names that are too vague and ensures the naming system is easily adaptable if a group’s function or location changes later. - Configuration consistency: While the configuration is separate, strive for consistency in platform-level settings across all Worker Groups/Fleets where possible (for example, standardizing Worker Process counts, licensing rules, and resource allocation profiles) unless a specific overlay requires specialization.
Key Benefits
- Logical segregation: This topology establishes separate management domains for the data plane. Configuration bundles, Pipelines, and Routes are distinct per Group/Fleet, allowing changes in one Group/Fleet to be isolated from others.
- Independent scaling: Each Worker Group/Fleet can be scaled horizontally by adding or removing Worker/Edge Nodes independently of other Groups/Fleets. This allows you to allocate resources based on the specific load requirements of each group’s assigned task.
- Layered overlays: While this topology defines the basic structure of multiple, separate groups, the actual criteria for dividing them–by function, geography, or security–are applied using overlays (such as Functional Split or Regional Split).