



Distributed (Single Worker Group/Fleet) Topology
The Distributed (Single Worker Group/Fleet) topology is the default, foundational production archetype for a Cribl deployment.
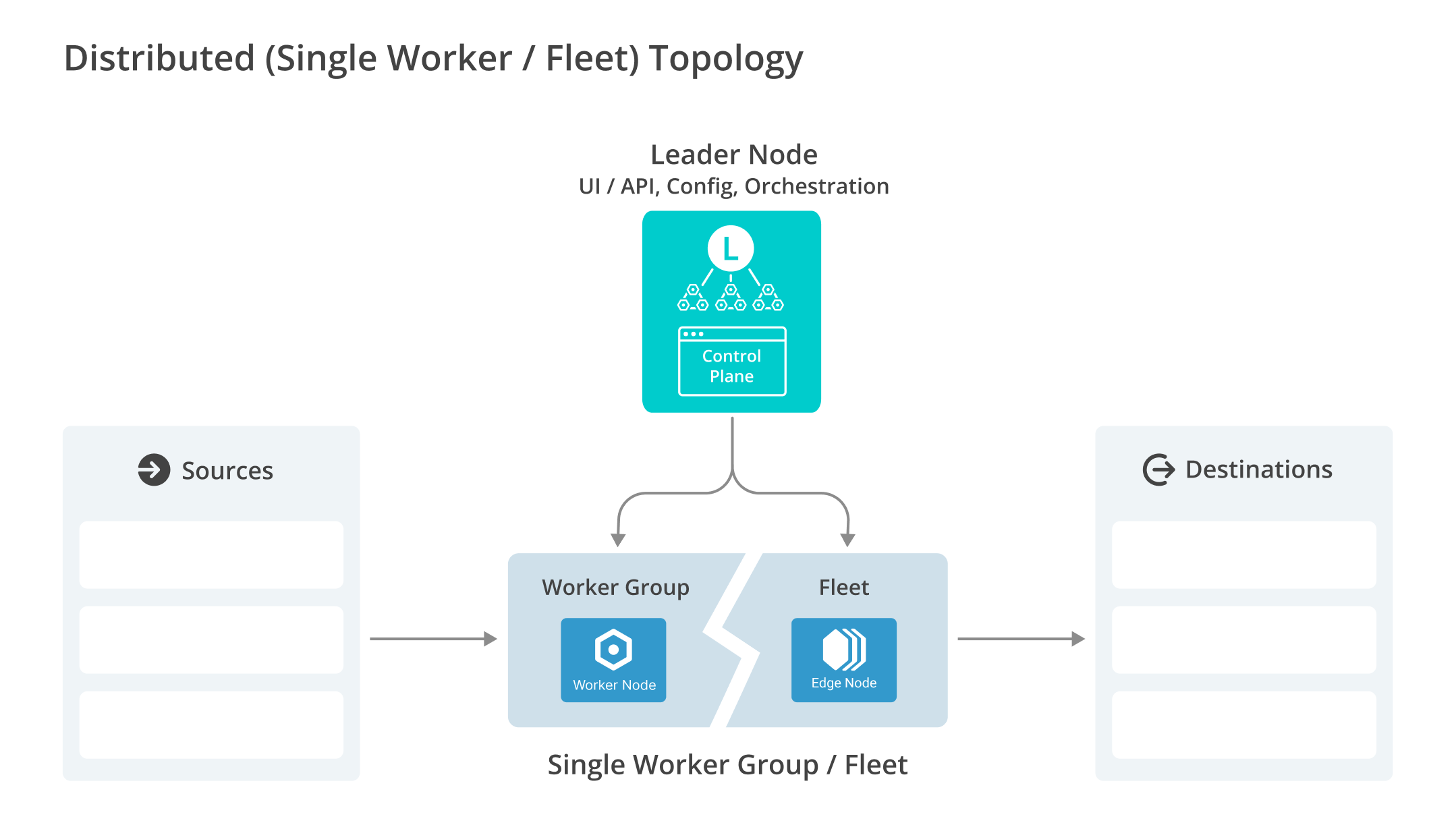
In this configuration, you have a Leader Node (or a high availability pair for resilience) providing centralized configuration, the UI/API, and orchestration.
All production processing is handled by a single Worker Group/Fleet that contains multiple Worker/Edge Nodes sized for N-1 capacity (designed to handle full load even if one Node fails). For details, see Best Practice: Scale for N+1 Redundancy.
All push-based Sources and Destinations map directly to this single “all-in-one Worker Group,” often accessed through one or more load balancers (LBs) or Virtual IPs (VIPs).
When to Use This Topology
This model is the ideal starting point when deployment needs are straightforward and contained:
- Default production: When your data primarily resides within a single region or data center.
- Simple requirements: When there are no strong requirements for data residency, sovereignty, or domain isolation that demand segregation.
- Contained volume: When the total data volume and Source count are well within the connection and throughput limits of a single Worker Group/Fleet, allowing for predictable scaling by simply adding more Worker Nodes over time.
Design Guidelines
If you intend for this single Worker Group to be part of a larger architecture later, adopt neutral naming conventions now (for example, wg-core, wg-main) so the Worker Group can easily transition without requiring a rename. Additionally, ensure you implement robust utilization monitoring (CPU, queue depth, connections) to accurately determine when a workload split is necessary. For details, see Operational Monitoring.
Limitations and Triggers for Multi-Worker Groups
This topology serves as an excellent base, but real-world complexity often requires layering in additional Worker Groups. You should consider migrating to a Multi-Worker Group topology (like Functional Split or Regional Groups) when any of the following triggers occur:
- Security/compliance boundaries: When you need distinct physical or logical segregation due to multi-tenant domains, different security zones (such as DMZ vs. Core), or strict regional boundaries (such as EU vs. US).
- Workload interference: When different types of workloads (such as live push ingest, pull-based collections, and heavy Replay jobs) start competing for resources, leading to latency spikes or data loss during bursts.
- Scaling thresholds: When the single Group approaches its practical operational limits regarding total open connections, Worker Processes per Node, or the maximum number of Workers that can be reasonably managed together.
- Operational agility: When different organizational teams require independent change windows, separate Git branches for configuration, or distinct deployment cadences.
Key Benefits
This topology offers the most streamlined operational experience:
- Simplest operational model: You only have one Worker Group /Fleet to size, monitor, and maintain.
- Centralized logic: Provides a single, central point for managing all Packs, schemas, Pipelines, and routing logic.
- Straightforward onboarding: New Sources and Destinations easily target the single, existing Worker Group/Fleet, minimizing topology choices for new teams.
- Predictable scaling: Scaling is primarily achieved by adding more Worker Nodes or increasing Worker Processes per Node until you approach the practical limits of connections or throughput for the Worker Group/Fleet.