



Single-Instance Topology
The Single-Instance deployment represents the simplest non-distributed architecture for running Cribl. In this setup, the Leader (control plane) and the Worker/Edge Node (data plane) are collapsed into a single process on one host.
This means all functions configuration management, UI/API, data ingestion, processing, and delivery run entirely within this one instance. Because it lacks dedicated Worker Groups/Fleets, there is no horizontal scaling or explicit separation of duties.
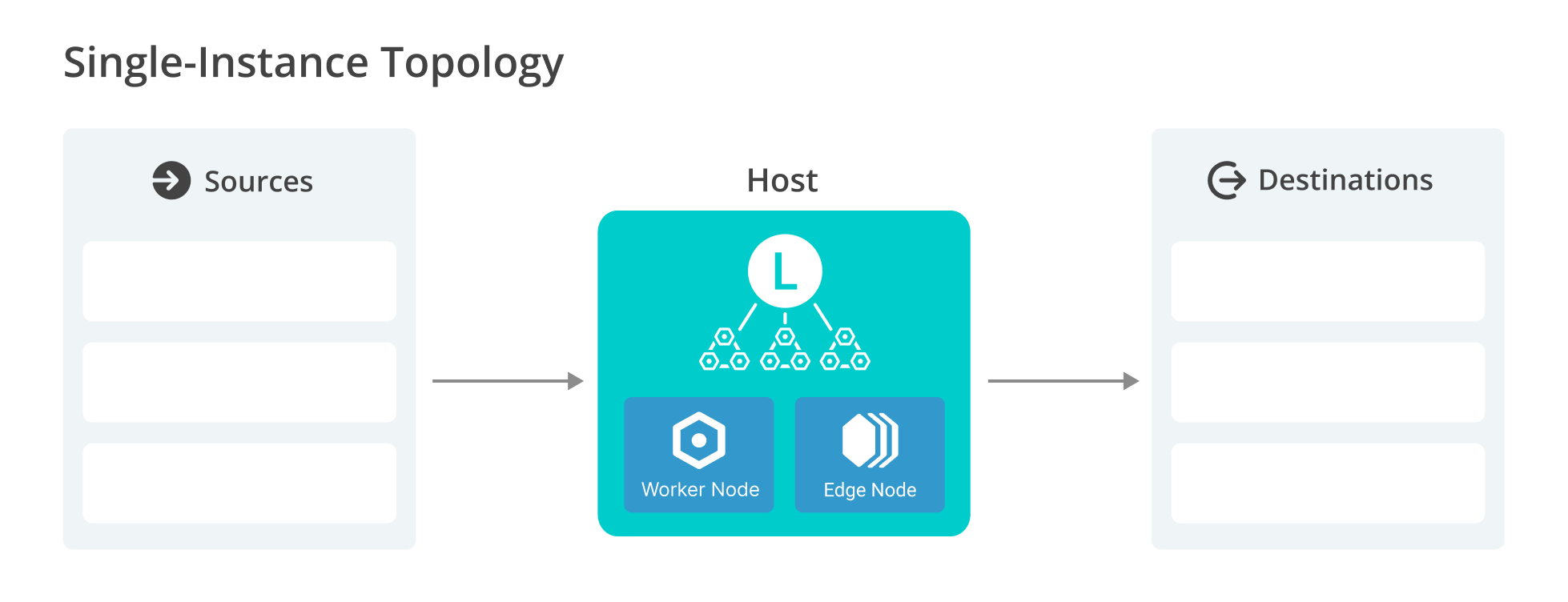
The diagram shows a Leader and Worker/Edge Node combined into a single process on one host.
When to Use This Topology
This topology is intentionally ephemeral and is not suitable for production environments. Use it specifically for environments where resilience, horizontal scaling, and High Availability (HA) are not critical requirements:
- Personal lab/sandbox: Ideal for self-paced learning, personal exploration, and initial experimentation with Cribl features.
- Short-lived proofs of concept (PoCs): Suitable for quick functional validation where the primary goal is demonstrating a capability, not validating scalability or durability.
- Small dev/test environments: Appropriate for low-volume development or testing environments where occasional downtime, planned restarts, and potential data loss are acceptable trade-offs for simplicity.
Design Guidelines
The Single-Instance topology is strictly a non-production environment intended for personal labs and temporary sandboxes, where its inherent lack of resilience, scalability, and High Availability (HA) makes occasional restarts and data loss acceptable. It must not be used as a “small production” or “pre-production” environment.
If you decide to use this topology as a temporary stepping stone and plan to migrate the configuration to a full distributed deployment later, you must proactively design your environment to be portable:
- Plan for distribution: Design your Routes and Pipelines as if they will eventually run on separate Worker Nodes. Avoid hard-coding local hostnames or file paths that would break once the Worker Nodes move off the Leader host.
- Use logical naming: Use clear, logical naming conventions for Sources, Destinations, and Routes that can be easily mapped to future Worker Groups.
- Preserve configuration: There is a supported path to promote a Single-Instance deployment to a Distributed one. To prepare, ensure you keep the
CRIBL_HOMEdirectory on storage that can be easily reused when setting up the new Leader. - Externalize secrets: Externalize any integration secrets (like tokens or passwords) to simplify the process of porting them to the new Distributed Leader.
The key takeaway is that the Single-Instance topology is a practical and easy way to start but should never be mistaken for a “small production” topology.