



Cribl Reference Architecture, Full-Suite
To guide you in designing and optimizing your Cribl implementation, this page outlines topology and connections for the full suite of Cribl products. You’ll find details about the components of the management, control, and data planes, and about the communication protocols that Cribl products use to interoperate.
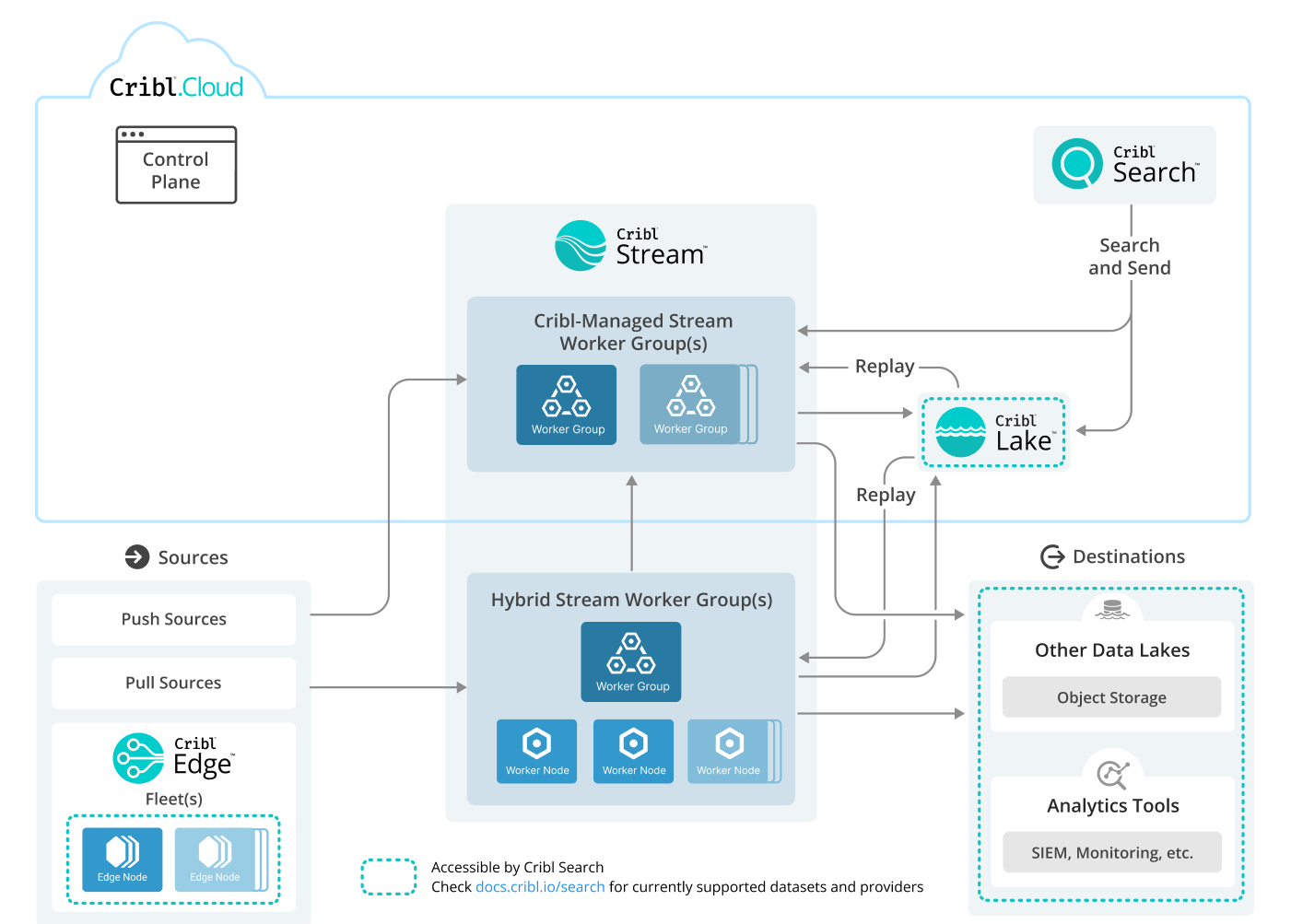
High-Level Example Architecture
This diagram summarizes possible relationships and connections among all Cribl products. To foreground Cribl Search and Cribl Lake options, it assumes a Cribl.Cloud Leader as the control plane.
The hybrid Stream Worker Groups represent zero to many customer-managed Groups, deployed on-prem or in private clouds.
Download an editable version of this diagram in SVG or draw.io format. Download Cribl stencils here.
Notes About the Diagram
This is an abstract, example architecture incorporating several Cribl components. Arrows indicate the flow of events, logs, metrics, and/or traces. A teal dashed outline indicates a resource type that Cribl Search can access as a Dataset or Dataset Provider.
The Cribl data plane can be operated as a fully SaaS service (Cribl-managed), or as a hybrid service (customer-managed instances, connected to Cribl control planes). If you plan to send data to the same cloud provider from which it originated, consider using hybrid Workers to minimize costs.
The Cribl data plane can be configured to send data between multiple products. For details, see Product Suite Interoperation and Interoperation Protocols later in this topic.
The following sections provide detailed descriptions of each plane of Cribl architecture. For practical sizing options, see Sizing Your Deployment later in this topic.
Components of the Cribl Data Engine
You can think of Cribl products as operating on three planes: a management plane, control plane, and data plane.
Management Plane
Exclusive to Cribl.Cloud, the management plane includes the services required to:
- Create new Organizations (the account boundary for unique customers in Cribl.Cloud).
- Provide access-control and authorization services.
- Provision and manage Workspaces (unique VPC containers, each isolating an instance of the Cribl Product Suite).
- Manage billing, metering, and cost controls.
The management plane is largely independent of individual products and services.
Control Plane
The control plane, or Cribl Leader, is the collection of services that provide configuration management for each product in the Cribl Product Suite. The control plane provides the central UI and API experience for operating Cribl Stream, Edge, Search, and Lake.
The control plane coordinates configuration pushes for updating products and their components (such as Worker Groups and Fleets), based on user changes.
In Cribl Stream pull-based data collection, the control plane coordinates Collection jobs’ state and dispatching. In Cribl Search, the control plane coordinates operators for querying and returning data at rest.
Data Plane
The data plane identifies where Cribl products collect, process, query, and store data. The components here handle most of the activity across Cribl products.
Cribl Stream Data Plane
In Cribl Stream, the data plane is made up of the Workers. Workers ingest data (on Push- or Pull-based Sources); process it (enrich, transform, reduce, mask); route it (multiple single feeds for distribution; and distribute it (by sending data to external Destinations).
Cribl Stream Workers support logs, metrics, traces, and security events (SNMP), as well as custom data sources retrieved through REST-based data collection. Cribl Stream Workers are designed to handle several TB of data per day per Worker, through distributed, shared-nothing processing.
Distributed Processing
Cribl Workers distribute events across available Worker Processes (CPUs) available on each Worker. This architecture enables high-scale parallel processing of data, with high levels of availability and resilience. You can group Workers into Worker Groups with shared configurations. This allows for both vertical and horizontal scaling of common workloads.
Cribl Edge Data Plane
In Cribl Edge, the data plane is the Edge Node - a lightweight package of Cribl Edge core components, designed to be run on customer endpoints. These endpoints can be servers, cloud or datacenter VMs, or container nodes (such as ECS instances or Kubernetes nodes).
The Edge Node is an agent that collects data from the local filesystem, local APIs, and local system state. Edge offers processing, routing, and distribution capabilities similar to those in Cribl Stream, at lower overall volume (per endpoint scale), and with much lower resource requirements.
In general, Cribl Edge Nodes use less than one CPU/vCPU for data collection, processing, routing, and distribution.
Cribl Search Data Plane
In Cribl Search, the data plane consists of on-demand compute resources called operators. The Cribl control plane coordinates and dispatches operators based on the search query that the user runs. The dispatched operators scale dynamically, based on the query and Datasets being queried.
Operators return results to the Cribl control plane for analysis and visualization. Cribl operators can be dispatched to a variety of different Dataset Providers, including Amazon S3 cloud storage, APIs, structured data stores, the Cribl control plane, and Cribl Edge Nodes.
Cribl Lake Data Plane
In Cribl Lake, the data plane consists of the backing storage buckets for storing, querying, and replaying data. Cribl Lake uses open formats, backed by a variety of cloud storage providers.
Cribl Lake is composed of Datasets, which are unique partitions within a storage bucket. Partitions define the folder structure of the data, for ease of querying and organization. Cribl Lake Datasets define both the partition and the data’s retention period.
Cribl.Cloud Data Isolation
Each Cribl.Cloud account provisions a Cribl Leader in a separate AWS account. By default, your Cribl-managed instances of Cribl Stream, Cribl Search, and Cribl Lake are deployed inside a Virtual Private Cloud (VPC) in this AWS account. However, you have the option to host Cribl-managed Stream Worker Groups in Cribl.Cloud on Azure, in an equivalent Virtual Network (VNet). Each account has isolated infrastructure, ingress domain, ingress IPs, and egress IPs.
If you configure multiple Workspaces within a Cribl.Cloud Organization, each Workspace and its associated components reside in a different VPC within the same AWS account. Each Workspace has its own Leader, with a distinct DNS name. Any Cribl-managed Stream Worker Groups will reside in that Workspace’s VPC.
If you provision any of the Organization’s Cribl-managed Stream Groups on Azure, these will also map to an isolated Azure account. No two Cribl.Cloud Organizations share the same Azure account ID.
Cribl is certified for SOC 2 (Service Organization Control 2) Type II security compliance.
Product Suite Interoperation
Cribl products are designed to operate independently, but these products have compounding value when working together. This section describes the most common interoperability scenarios. The shared management and control planes provide you with the facilities to easily coordinate integration and security across all products.
Data Transfer
Cribl products are designed to send data between different data planes without incurring duplicate charges.
Transferring Data in Motion
Cribl Edge and Cribl Stream pricing is based on the data they collect or receive. A common data transfer pattern is to collect data at the endpoint with Cribl Edge, then distribute that data to Cribl Stream for additional processing and last-mile distribution.
This architecture allows you to aggregate data centrally from distributed endpoints. A key advantage is that it provides a single distribution point, making it more secure and easier for receivers to secure data reception. This architecture also provides last-mile queuing for resilience in the case of destination outages.
When different Cribl products are connected to the same control plane (called a Leader), they use one of two specialized protocols to send data to each other: Cribl HTTP or Cribl TCP.
These Cribl-specific protocols (Cribl HTTP and Cribl TCP) also enable data transfer between Workers that are not connected to the same Leader. This is common in hybrid cloud deployments or when transferring data between different Cribl.Cloud Workspaces or on-prem environments. Cribl only counts data towards your usage on the Worker where it’s initially received or collected.
Using these Cribl-specific protocols, you can send data on to these recipients at no additional cost:
One or more additional Edge Nodes.
One or more additional Worker Groups.
Another Cribl.Cloud Workspace on a billing plan or Organization with a paid on-prem license. This includes scenarios where the sending and receiving environments do not share a Leader, but have the same on-prem license key installed or are within the same Cribl.Cloud Organization. See Transfer Data Between Workspaces or Environments for more details.
For details about these protocols’ implementation, see Interoperation Protocols later in this topic.
Transferring Data to/from Cribl Lake
Cribl Stream has built-in Destinations and Sources for Cribl Lake, which can respectively send data to, and collect data from, specified Cribl Lake Datasets. Configuring these Destinations and Sources requires the Editor or higher Permission at the Cribl Stream product level, or the Editor or Higher Permission on an individual Worker Group. Once these integrations are configured, transferring data to and from Cribl Lake requires no Permission settings on Cribl Lake.
Transferring Data to/from Cribl Search
Cribl Search results can be either routed to Cribl Stream for additional processing, or stored directly in Cribl Lake, using Cribl Search commands for each product. Routing to Cribl Stream will send the data (at no additional cost) through the Cribl Stream processing, routing, and distribution workflow, for subsequent routing to other tools like a SIEM or IT Ops analytics tool.
Of course, the primary (and more interesting) aspect of Cribl Search is directly querying and analyzing data.
Querying Data in Cribl Search
Cribl Search is designed to work out-of-the-box with other parts of the Cribl Product Suite.
Cribl Search can query data on endpoints using Cribl Edge. Data can be buffered at the edge using source-based buffers or a dedicated buffer destination. Cribl Search can dispatch operators to Edge Nodes managed by a shared Leader.
Cribl Search also has built-in Dataset Providers for Cribl Stream. These providers access Cribl Stream internal operational logs, which you can use to facilitate troubleshooting and analysis of Cribl Stream internal operations.
By design, Cribl Search does not search data that Cribl Stream is actually processing, because doing so would impose a performance penalty on the streaming data, leading to higher latency and slower processing times.
Cribl Search has tight integration with Cribl Lake, which is a default Dataset Provider. Also, any new Dataset created in Cribl Lake can be queried immediately by teams who have been granted access to that Dataset. No additional configuration is required, and all products with a shared control plane also have a unified RBAC model to ensure secure access by users authorized on each of the different products.
Interoperation Protocols
This section provides details on the protocols by which Cribl products and planes communicate with each other. All protocols described in this section can be secured using TLS.
To send data between Worker Nodes and/or Edge Nodes without duplicate charges, use either the HTTP or TCP protocol, as outlined in the following subsections.
Note that each of these protocols is designed to be used as a paired Source and Destination. For example, you might send data from a Cribl HTTP Destination in Cribl Edge to a Cribl HTTP Source in Cribl Stream. A similar pairing would be a Cribl TCP Destination to a Cribl TCP Source. And to send data between Worker Groups, Cribl Stream exposes its own version of the Cribl HTTP Destination and Cribl TCP Destination, which have exactly the same configuration options as their Edge counterparts.
Cribl HTTP
For most use cases, Cribl HTTP is the preferable protocol, because it allows for a more even distribution across Worker Processes. It is preferable for use cases involving Network Load Balancers (NLBs) and proxies. HTTP is also more performant, and easier to set up and use.
Furthermore, Cribl HTTP enables you to place a load balancer in front of multiple Workers, to ensure even more consistent distribution of events across Worker Processes. By default, in Cribl.Cloud-managed data planes, all HTTP data is distributed using an NLB.
Cribl TCP
Cribl TCP is built to send to multithreaded receivers. Its current limitation is vulnerability to “pinning” on persistent connections.
Setting up Cribl TCP is more involved than Cribl HTTP setup, and the difficulty increases as the network topology becomes more complex. Cribl Edge-to-Stream forwarding is one example of such a complex scenario.
Leader Communication with Groups and Fleets
The communication path between the Stream/Edge data plane and the control plane is secured on port 4200 using TCP. The Workers and Edge Nodes must be able to communicate/connect to the Leader on this port, using this protocol.
Sizing Your Deployment
Cribl handles the management, control, and data planes for Cribl Search and Cribl Lake by default, including their supporting infrastructure.
You determine the sizing of Cribl Stream Worker Groups (data planes). Cribl Stream supports both Cribl-managed (Cribl.Cloud) and customer-managed (hybrid) Worker Groups. Depending on which you choose, you will need to consider different sizing approaches.
Sizing Cribl-Managed Worker Groups
In Cribl-managed Stream Worker Groups, Cribl provisions Workers, as needed, to support the Anticipated data ingest rate that you specify. You can change this specification at any time - specifying higher throughput to provision more infrastructure, or specifying lower throughput to shut down Workers and reduce costs. For details, see Cribl.Cloud Worker Groups.
Sizing Customer-Managed Worker Groups
For background information on sizing, see Cribl Stream Deployment Planning and adjacent topics. For details about infrastructure requirements for Worker Nodes, see Single-Instance/Basic Deployment.
Sizing Cribl Edge Fleets
Each Leader can manage up to 250,000 Edge Nodes set to send Minimal metrics, or up to 100,000 Edge Nodes sending Basic metrics. For details about these options, see Controlling Metrics in Cribl Edge.
For extensive details about planning , see Deployment Planning, Fleet Management, and adjacent Cribl Edge topics.
Sizing Customer-Managed Leaders
If you choose to manage your Cribl Leader on your own resources, see the Cribl Stream Distributed Deployment topic for basic requirements, and the Cribl Edge Recommended Leader Configuration topic for additional requirements corresponding to your Fleet scaling.
Sizing and Distributing Cribl Stream Workloads
Here some common scenarios by data type:
Are you running many dispatched Collection jobs? Some customers manage this variable capacity using Amazon Auto Scaling groups.
Are you ingesting constant streaming data from Push Sources? You will want to isolate these senders into separate Worker Groups from your Collection workloads. To optimize data delivery, see Persistent Queues and adjacent topics.
Disclaimers
All product names, logos, brands, trademarks, registered trademarks, and other marks listed in this document are the property of their respective owners. All such marks are provided for identification and informational purposes only. The use of these marks does not indicate affiliation, endorsement, or ownership of the marks or their respective owners.
This document is provided “as is” with NO EXPRESS OR IMPLIED WARRANTIES OR REPRESENTATIONS. It is intended to aid users in displaying system architecture, but might not be applicable or appropriate in all circumstances. You should not act on any information provided until you have formed your own opinion through investigation and research. Cribl is not responsible for any use of this document or the information provided herein.