



Syslog to Cribl Stream Reference Architecture
The Cribl Syslog Source is Cribl’s most commonly used input type. Cribl Stream can act as your edge and/or central syslog server, giving you more capability while easing management tasks. Cribl Stream can scale to handle your syslog data volume, and can queue data to a disk buffer to help ensure its delivery.
This reference architecture starts with a syslog overview, then outlines tested practices for deploying Cribl Stream as a syslog server to collect syslog data from multiple geographic regions. It also covers tuning the server, along with broader guidance toward optimizing a high-performance syslog platform.
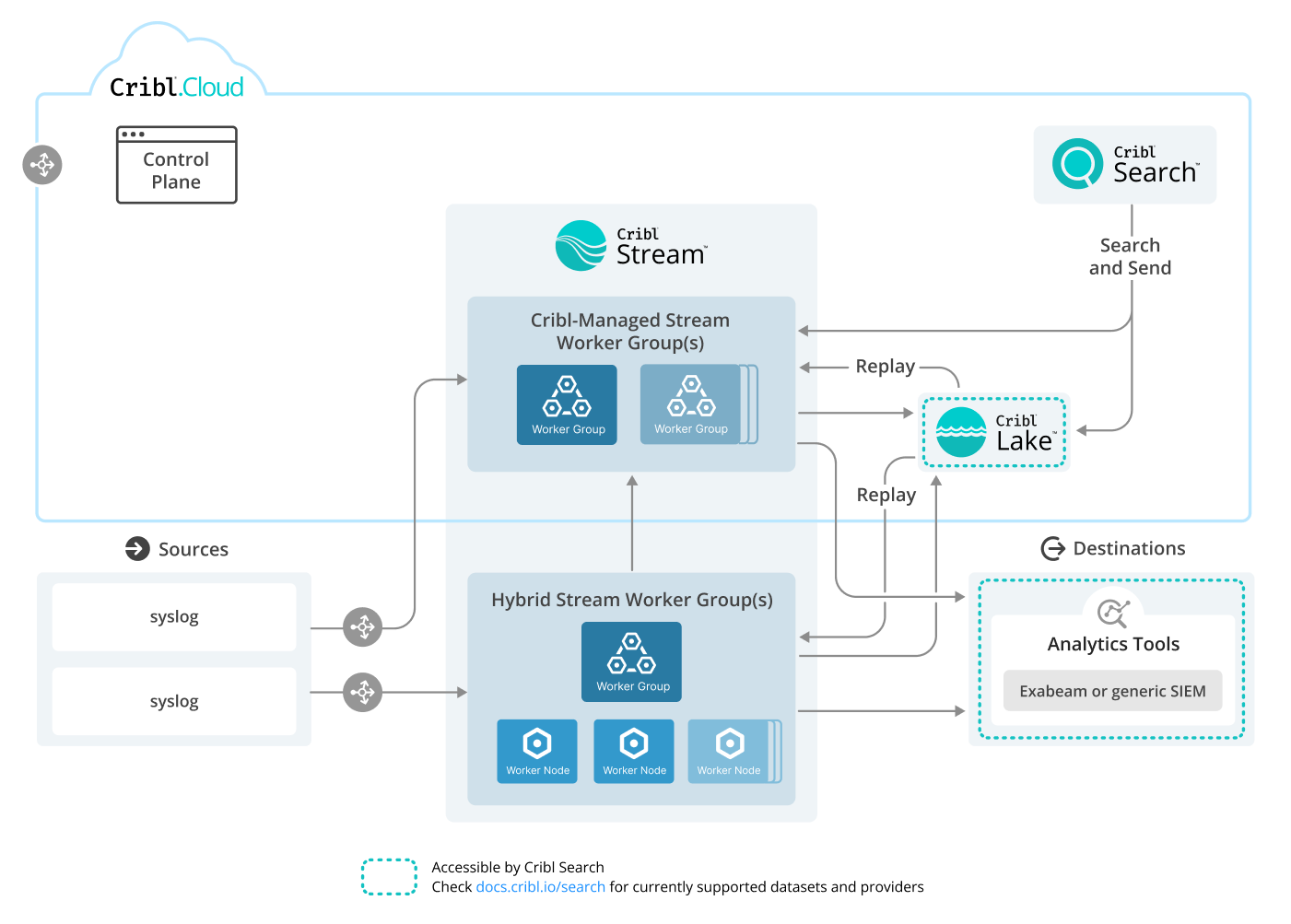
Download an editable version of this diagram in SVG or draw.io format. Download Cribl stencils here.
Syslog Overview
A widely used protocol, syslog is the de facto standard way to deliver log events. Many apps and systems offer syslog as a delivery option, and nearly every SIEM and search tool accepts syslog as an input. It’s the lowest common denominator for moving events around.
However, syslog has its quirks. Understanding and mitigating them should facilitate your syslog ingest.
A syslog event is normally a single line, starting with the priority (a combination of the facility and security, between < and > delimiters). This is followed by a timestamp, by several optional fields, and then by the message. The message also has a few expected tags, like application name and often a log level. The syslog payload should use UTF-8 encoding, as a standard that can represent the entire Unicode character set. (The syslog protocol does not have a way to convey alternate character-set information.)
Cribl Stream provides a Syslog Source (covered below), which supports syslog data defined by RFC 3164 and RFC 5424. This data can include the above fields plus additional message content for detailed analysis. The Syslog Source also processes optional message-length (octet-count) prefixes, specified in RFC 5425 and RFC 6587, which help ensure complete and accurate data transmission. Messages may either be octet-count-delimited or newline-delimited.
TCP or UDP Transport?
For any given syslog sender, you might need to choose between ingesting data using UDP versus TCP. Which transport is best depends on the characteristics of the sender. Here are some basic guidelines.
TCP Generally Preferred for Syslog
Cribl generally recommends using TCP with TLS encryption, for the most reliable and secure data delivery. Exceptions are where:
- Your sender doesn’t support TCP.
- Dropped events are acceptable.
- Your volume is too high for your hardware to handle with TCP.
If your use case matches one of these exceptions, use UDP.
TCP is vulnerable to connection pinning. See the Mitigate TCP Pinning and Scaling for High-Volume Syslog Senders sections for details.
Where UDP Is Preferred for Syslog
Beyond the TCP exceptions listed above: For single, high-volume senders (over 300GB/day), use UDP if possible. For both the sender and Cribl Stream, UDP imposes lower overhead than TCP. The stateless nature of UDP allows each log event to be directed to a different Worker Process than the previous event. This ensures maximum capacity utilization of Cribl Stream’s Worker Nodes.
Separating TCP and UDP Data
Although each Cribl Stream Syslog Source that you configure can ingest both TCP and UDP data, it’s a more-secure practice to isolate each protocol’s traffic in separate Sources.
Mitigate TCP Pinning
Cribl Stream’s Syslog Source offers a native TCP load balancing option, summarized below, which distributes traffic across Worker Processes on each Worker Node.
One problem that crops up with TCP load balancing involves “sticking” or “pinning” to a connection. This happens because most load balancers are not syslog-aware: They don’t know where one event ends and another begins. Once the syslog sender has a connection, it holds onto it and just keeps sending data into it. That prevents you from distributing your data across your resources effectively.
Cribl Stream’s native TCP load balancing option mitigates TCP pinning. This option dedicates one Worker Process on each Worker Node to receive TCP syslog data, and fans out the resulting events across all other Worker Processes on that Node. With a big enough instance, this solution will scale to ~100 MB/s of ingested syslog data per Worker Node. (Equivalent to ~8.6 TB/day.)
When (Not) to Enable TCP Load Balancing
Cribl recommends enabling native TCP load balancing only if you have a small number of “fat” connections, sending throughput greater than what one Stream Worker Process can handle. Conversely, where you have a large number of low-throughput connections, Cribl does not recommend enabling its built-in load balancing.
Accounting for the Cribl Stream TCP Load Balancer
Where you do enable the Cribl Stream TCP load balancing, be sure to account for the extra Worker Process reserved for receiving and distributing the syslog events.
Example: You have a 16-core system running with the default -2 Process count setting for the Group. That means you have 14 processes that could handle processing, and 2 reserved for system overhead.
Without the internal load balancer active, you risk the syslog sender’s “pinning” to a single process, so you’re not balanced across them all. This will limit your throughput to that of a single process. We can correct this.
With the internal load balancer active, an extra process is fired up, dedicated to receiving the syslog traffic. This process does one thing: Spray events evenly across all the available Worker Processes on the same Worker Node.
Now your throughput limit is equivalent to 14 cores. But we’ve taken one of those 2 reserved cores (
-2). So we must change the reserve* *to-3, and possibly add more cores to compensate (if 13 processing cores isn’t enough).
Alternative Sources for Malformed Syslog
Cribl’s Syslog Source is generally the ideal way to ingest syslog data into Cribl Stream, but not always. It’s optimized for well-formed syslog data. By design, this Source has no Event Breakers configured. The protocol defines what an event is.
If you have a “syslog” sender that causes events to be broken improperly, you should consider using a Raw TCP or Raw UDP Source, with a custom Event Breaker that you configure. See this video for a TCP example, and see our Event Breakers topic.
TLS Configuration
Cribl aims to support Transport Layer Security (TLS) everywhere, and always recommends enabling TLS when possible. Cribl Stream’s Syslog Source supports TLS when you use the TCP transport.
By default, Cloud Worker Groups have TLS syslog on port 6514. With self-hosted or hybrid Cribl Workers, you can use any open port you want, although ports under 1024 will need special permissions.
Palo Alto Networks’ Panorama service requires TLS to be active on the receiving end, and not in a standard manner. For details, see our Palo Alto Syslog to Cribl.Cloud topic.
Optimizing Hybrid and On-Prem Syslog Ingest
When deploying Cribl Stream on infrastructure that you manage, Cribl always recommends establishing Cribl Stream Worker Groups as close as possible to your syslog senders over the wire. Especially with UDP, this is vital since there is no guarantee of delivery. But even when using TCP, with relatively long communication channels and more places to bottleneck, it’s best to get the logs into Stream as quickly as possible, where they are safe and sound.
Furthermore, most syslog senders do not have queuing capabilities. If the downstream receiver doesn’t respond quickly enough, events could be lost. (See Persistent Queues, later in this topic, to remedy this.)
Set Up Cribl Stream as a Syslog Server
For basic configuration in Cribl Stream, see our Syslog Source topic. By default, Cribl Stream will handle parsing the basic syslog structure. You are then able to use Cribl’s Functions to route, transform, filter, reshape, aggregate, and re-deliver the data in any way you please.
Network Load Balancing
The vast majority of syslog-producing apps and appliances have no concept of load balancing. You give them a hostname or IP, and a port, and they blast data at it. So the job of spreading those events over multiple hosts will be up to you.
With customer-managed (on-prem or hybrid) Worker Groups, balancing traffic across Worker Nodes requires a load balancing service or appliance in front of Cribl Stream. Examples of such load balancers are HAProxy, nginx, F5, Cisco, AWS ELB, or plenty of others.
To ensure even distribution of traffic across all Cribl Stream Worker Nodes, you must configure your network load balancer with “stickiness” or “session persistence” disabled. This setting prevents the load balancer from consistently routing traffic from the same Source to the same Worker Node, allowing for optimal load balancing and performance. For load balancer configuration examples, see Configure Third-Party Load Balancers.
Distinguishing IP Addresses
A side effect introduced by external load balancers is the connection IP address. All connections will appear to come from the load balancer’s IP address, instead of from the original log sender. Depending on your load balancer type, you might work around this mismatch by selecting the Syslog Source’s Enable proxy protocol support, which will provide the original IP to Cribl Stream.
Scaling for High-Volume Syslog Senders
Keep in mind these general sizing considerations:
The general sizing guideline from Cribl is to plan for a maximum of 200 GB/day in+out per vCPU when hyperthreading is enabled (2 vCPUs per physical core on Intel/AMD). At its simplest, this can equate to 100 GB/day in, 100 GB/day out when sending full-fidelity data to a single Destination.
Throughput is In + Out volume. For example, if you have 100 GB/day inbound volume sending 50 GB/day to a downstream analytics tool and 100 GB/day to a low-cost data lake, you should size for 250 GB/day overall throughput
If a single syslog sender is sending more than 100 GB/day over TCP, enable TCP load balancing, summarized below, on the Cribl Stream Syslog Source. Also, size an additional CPU to host a Worker Process dedicated to load balancing.
Size conservatively. Ideally, deploy enough Workers to handle up to 50% bursts in traffic, and to maintain high availability when one Worker goes down.
Sources that use long-lived TCP connections should be converted to UDP, or to protocols that batch data in different TCP sessions. (Examples are most HTTP Push Sources.) Sources that send over long-lived TCP connections are subject to TCP pinning. They can send up to 200 GB/day (if the Stream Worker is built on CPU cores).
To apply these guidelines, consider your data’s typical event size, and zoom down to consider throughput in maximum MB/second. For example: If you assume you have an average event size of 500 bytes, then 200 GB/day is approximately 5.7 MB/second. If you have regular daily peaks of 10 MB/second, then size for these peaks to avoid backlogs and ensure optimal performance.
System Tuning for UDP Syslog
Linux systems typically allocate a buffer that is too small to handle sizable syslog traffic over UDP. For details on checking and increasing your system’s buffer, see UDP Tuning.
Dividing Traffic by Ports
Syslog events are very simple. The message doesn’t always obviously identify what kind of data you have. However, usually you can set up some pattern-matching or host-matching to ID, and filter to route which events are which types. You could do this by adding fields on the Source’s Fields tab, or in a pre-processing Pipeline.
Alternatively, you can use different ports for each type of data. For example, set Cisco ASA to use port 9514, while NX Log sends to 9515. But you can combine this approach with using the Fields config to label the syslog data type, as outlined below.
Dynamic Labels (Fields)
For lighter loads (think less than ~200 GB/day), Cribl’s preference is to use a single port for all types. Then you can use the Fields config, or a pre-processing Pipeline, to qualify the data types and label them appropriately. You can qualify via host lookups, patterns, or other factors.
For heavier loads, or special cases that require a dedicated port, set up the ports but still use the Fields config to set the same label. This helps to keep your routing table sane, as shown in the screen captures below.
Dedicated Worker Groups
For extra large senders, you might want to consider an entirely isolated Worker Group. For example, syslog (or a particular syslog sender) might be 90% of inbound data volume in a Worker Group that is processing other data types.
In these cases, consider dedicating a Worker Group just for syslog, and scaling that Group appropriately to optimize syslog delivery. For details, see our Sizing and Scaling topic.
Pros of using a single Worker Group:
Commit and deploy only once per change.
Manage all syslog configuration in one Group.
Cons of using a single Worker Group:
- Additional filtering required if your data needs to be sent to diverse Destinations.
Other considerations:
- A Worker Group can also process other data (such as from Filebeat source, Splunk forwarders, or HTTP listeners). However, if the agent count reaches the thousands, a dedicated Worker Group per data type is better.
Other Scaling Recommendations
For HA (high-availability) reasons, don’t drop below two, or preferably three, Worker Nodes in a Worker Group. Size these Nodes so they can handle running at least one Node short.
If you’re at or below eight or even 16 cores per Worker Node, scale up (adding cores) before scaling out (adding Worker Nodes).
Handling Unvalidated Data
Syslog can be prone to receiving unwanted logs. Cribl recommends validating the host sending the logs, or possibly even the content. If the validation fails, dump the data to Cribl Lake or to another object store for (short!) retention only. Periodically check your resulting dead-letter Dataset for valuable logs that have fallen through unintentionally.
This validation tip extends beyond syslog. Cribl always encourages actively validating which logs end up in your analysis tier. You can also use Cribl’s Schemas Library for validation.
Timestamps and Timezones: UTC
Many syslog senders do not include a timezone in their timestamps. RFC 5424 requires TZ identification in the string, but RFC 3164 specifically disallows a TZ, permitting only Mmm dd hh:mm:ss format for the timestamp.
A timestamp without an explicit offset risks being misinterpreted, which can place events in the future, or in the past. Fortunately, Cribl Stream provides you with the tools to easily fix most such misattributions, so you can normalize your time.
Option A: Use the Cribl Syslog Pre-Processing Pack, or borrow the idea from it: Use lookup files to align particular hosts to the correct timezone, and use Cribl Stream’s Auto Timestamp Function to adjust event time accordingly.
Option B: Do future you a huge favor and promote UTC for all servers and appliances. Even if you choose Option A above, pursue this option long-term. UTC is the ideal way to log event time. (Let the analysis and reporting tiers convert from UTC to local zones when, and if, they need to.)
Persistent Queues for Data Reliability
Being ready for unexpected downtime is crucial, especially when it comes to syslog. Most syslog senders do not buffer data, and no UDP syslog senders buffer data if the receiving side is down or blocking. There are a few resulting scenarios in which Cribl’s Syslog Source is at risk of losing events:
- The receiver downstream from Cribl Stream is down or rejecting data.
- The receiver downstream from Cribl Stream is so slow that Stream can’t move events to it fast enough.
- Cribl Stream itself is overwhelmed by processing events, and is not able to receive new data.
To handle these situations, Cribl Stream offers persistent queuing (PQ). In most situations, Cribl recommends enabling Source-side PQ in Always On mode. For Cribl-managed Worker Group (with an appropriate Cribl.Cloud plan), it’s a simple flag to enable this. For hybrid and on-prem Workers’ configs and sizing considerations, see our persistent queue guides:
- About Persistent Queues
- Optimize Source Persistent Queues (sPQ) (not available in Cribl Edge)
- Optimize Destination Persistent Queues (dPQ)
- Destination Backpressure Triggers
Tuning Persistent Queues with UDP
When you enable Source-side persistent queue (sPQ) for a UDP Syslog Source, Cribl Stream bypasses the Source’s Advanced Settings > Max buffer size (events) and uses only the persistent queue’s own buffering controls. In Stream 4.10 and newer, the Max buffer size (events) field is hidden and ignored whenever Source sPQ is enabled for UDP-based Sources, so you no longer need to set it to 0 manually.
On Cribl-managed Cloud Worker Groups, persistent queue behavior (mode, buffer behavior, and queue size) is managed by Cribl. The UI exposes only the Enable persistent queue toggle; you can’t tune individual Source PQ settings such as Max buffer size, Max file size, or Max queue size. For environments where you need to tune these settings, use a customer-managed (hybrid or on-prem) Worker Group and follow the guidance in Optimize Source Persistent Queues.
Optimizing PQ Storage
Use dedicated and fast storage to host your PQ files. Dedicated because you don’t want PQ to affect other parts of your running system if the PQ fills up. Fast because you don’t want to hold up processing when writing to, or reading from, the queued storage.
Conclusion
Cribl Stream offers a performant, flexible, and complete syslog service. Configuring Cribl Stream according to the architectural principles above should smooth your syslog data’s path to all your intended destinations.
Disclaimers
All product names, logos, brands, trademarks, registered trademarks, and other marks listed in this document are the property of their respective owners. All such marks are provided for identification and informational purposes only. The use of these marks does not indicate affiliation, endorsement, or ownership of the marks or their respective owners.
This document is provided “as is” with NO EXPRESS OR IMPLIED WARRANTIES OR REPRESENTATIONS. It is intended to aid users in displaying system architecture, but might not be applicable or appropriate in all circumstances. You should not act on any information provided until you have formed your own opinion through investigation and research. Cribl is not responsible for any use of this document or the information provided herein.