Dataset Acceleration (Deprecated)
Automatically prescan selected portions of your data to improve future search performance.
Deprecated Feature
Cribl has deprecated this feature and removed it from the product. We invite you to explore Lakehouses as a new option to speed up searches on designated Datasets.
Please continue to report issues through normal Cribl support channels, but assistance for this deprecated feature might be limited.
Although you can always point Cribl Search at any source and start searching immediately, you can also automatically prescan selected Datasets and fields beforehand, using Dataset Acceleration. This process lets Cribl Search generate relevant metadata to further optimize search performance, especially for very large Datasets.
You can use Dataset Acceleration with the following Dataset types:
- Cribl Lake
- Amazon S3
- Azure Blob Storage
- Google Cloud Storage
- Amazon Security Lake (only in the Quick mode)
Dataset Acceleration Costs
Dataset Acceleration runs periodic background searches that consume your Organization’s credits. However, it boosts performance and saves time, which can actually help you reduce long-term costs. To make an informed decision about each of your Datasets, check the performance gain that Dataset Acceleration provides in your case. The larger the Dataset, the more improvement you should see.
After the first prescan, Cribl Search will scan only the data modified since the last scan. This happens every five minutes (a frequency that might change in the future).
To keep Dataset Acceleration costs under control, you can:
- Choose which Datasets to accelerate.
- Specify the time range that you’re interested in.
- Select the exact fields that you want to prescan, using the Detailed scan mode.
- Measure the performance gain that the Acceleration provides.
- Disable Dataset Acceleration at any time.
Dataset Acceleration Scan Modes
You can decide how much metadata to generate for each Dataset, by selecting one of the two scan modes.
The Quick mode is a lightweight scan that lists the objects included in the Dataset, their paths, and the existing metadata.
The Detailed mode is a more thorough scan that also scans the objects themselves, collecting min/max statistics about the specific fields that you’re interested in. This scan takes longer.
| What Cribl Search does | Quick mode | Detailed mode |
|---|---|---|
| Lists all objects included in the Dataset, along with their paths. | ✓ | ✓ |
| Lists the existing metadata of all objects. | ✓ | ✓ |
| Scans selected objects to generate min/max statistics about the specified fields. | ✓ |
Find Out Which Datasets Are Accelerated
When you go to Data > Datasets, accelerated Datasets are marked with the lightning bolt icon
 .
.
When you’re running a search, look for the lightning bolt icon
below the query box:
 means that at least one of the queried Datasets is accelerated.
means that at least one of the queried Datasets is accelerated. means that none of the queried Datasets are accelerated.
means that none of the queried Datasets are accelerated.
Enable Dataset Acceleration
To enable Dataset Acceleration for a Dataset:
- In Cribl Search, select Data, then Datasets.
- Select the Dataset you’re interested in, and then Acceleration.
- Toggle Enable Acceleration to Yes.
- In Time Range, set a rolling time window that indicates how far back in time the metadata should be maintained.
Acceleration won’t apply to data generated before the start of this time range.
If you select All Time, Cribl Search will scan the data all the way back to 1 January 1970 (the Unix time), but most probably it’ll only happen once, because all subsequent scans will cover only the data modified since the last scan. - Select the scan mode that you want to use.
- In the Detailed scan mode, you need to enter the exact fields for which you want to generate
min/max statistics. Focus on the fields that you’ll search the most frequently.
Note that
_timeis included by default.
- In the Detailed scan mode, you need to enter the exact fields for which you want to generate
min/max statistics. Focus on the fields that you’ll search the most frequently.
Note that
- Select Save. Cribl Search will start scanning the data in the background. Depending on the Dataset size, the first prescan may take a while, so for very large Datasets, consider adjusting the Running time limit.
From now on, Cribl Search will periodically scan recently modified data in the background, to keep the metadata up to date.
To test Acceleration on the
cribl_search_sampleDataset, you need to clone it first. Select Data, then Datasets, then cribl_search_sample, then Clone Dataset.
Disable Dataset Acceleration
To disable Dataset Acceleration for a Dataset:
- In Cribl Search, select Data, then Datasets.
- Select the Dataset you’re interested in, and then Acceleration.
- Toggle Enable Acceleration to No.
- Select Save. Cribl Search will delete the metadata associated with the Dataset.
Check Dataset Acceleration Performance
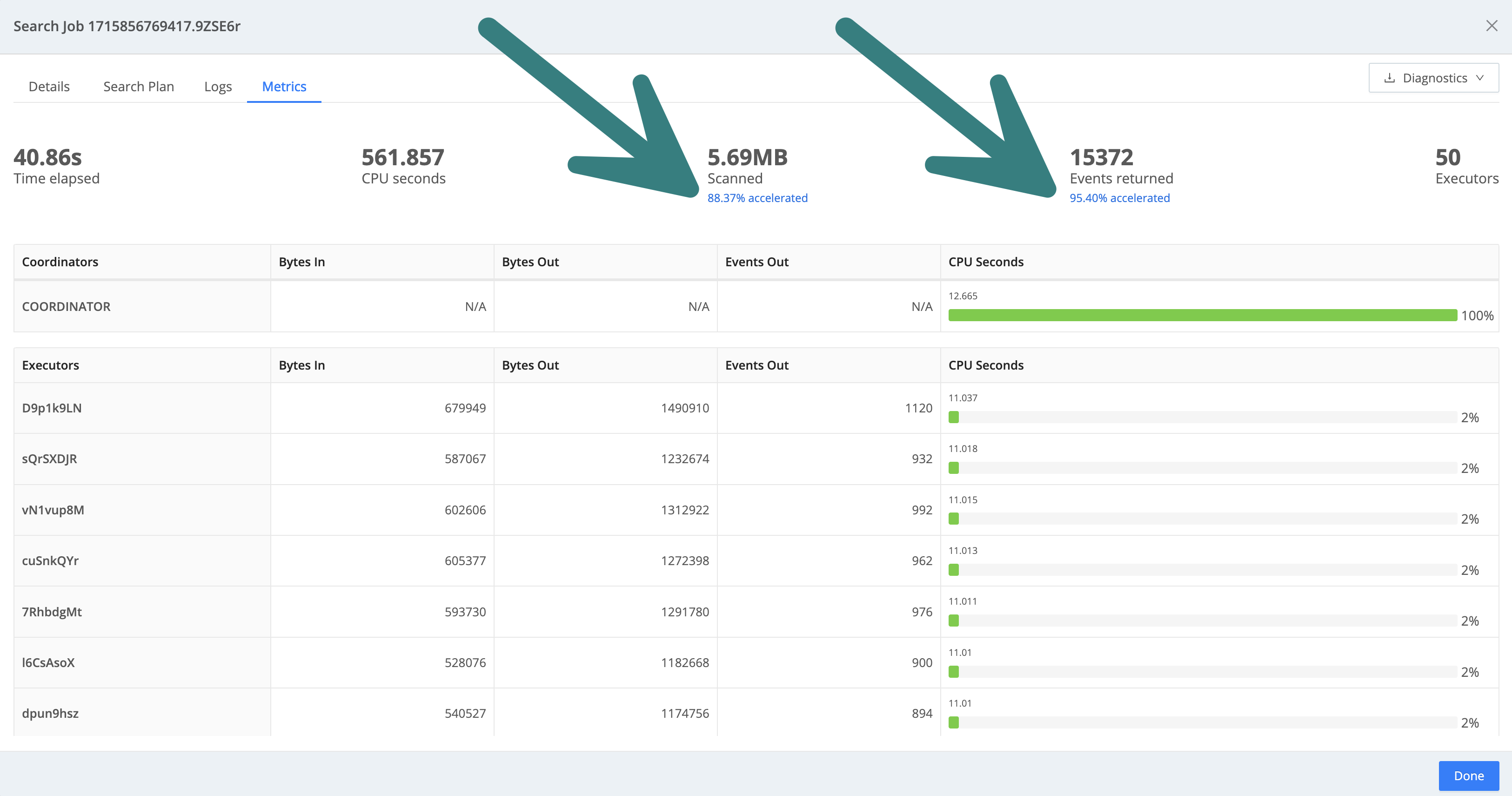
To check the exact performance gain from using Dataset Acceleration:
- Run a search on a Dataset that’s not accelerated yet. The
lightning bolt icon should display as
.
- Once the search starts running, select Details, then Metrics. Here, you can view the search’s performance metrics. Under Scanned and Events returned, you should see the Accelerate your Datasets link that takes you to the Dataset’s settings. This means that the queried Dataset is not accelerated.
- Close the window by selecting Done.
- Now, enable Acceleration for the Datasets you just searched. Make sure to select fields and time range that match the search you just ran.
- After Cribl Search finishes scanning the data, run the same query as before. The
lightning bolt icon should now display as
and the search should run faster than before.
- Compare the metrics with the previous search (if you still see the Accelerate your
Datasets links, Cribl Search didn’t finish prescanning the data yet).
- Under Scanned, the Accelerated metric shows what percentage of the scanned data is affected by Dataset Acceleration.
- Under Events returned, the Accelerated metric shows what percentage of the returned events contain accelerated fields.