



Investigative Searching
Optimize investigations with Cribl Search.
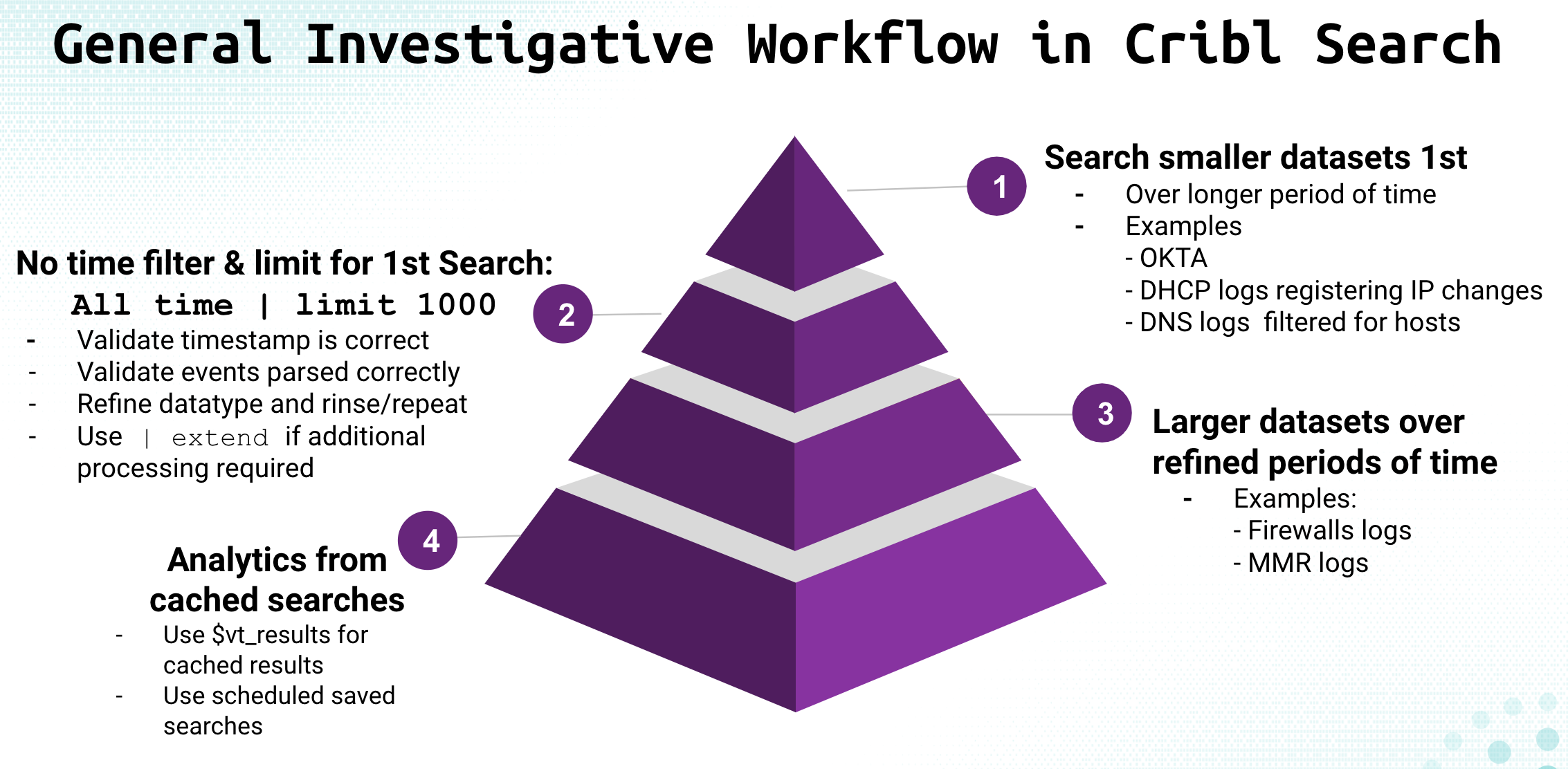
When performing investigations across multiple Datasets, an ideal workflow is:
Search the smallest Dataset first, across all time, with a limit of 1,000 events.
Alternatively, if your smallest Dataset has been searched before, search that Dataset first, for your time window of interest.
S3: Discover Unknown Bucket Directory Structure
You can investigate this in the AWS Management Console. Or, in Cribl Search:
Create a Dataset whose path is just the S3 bucket name.
Run this query:
.show objects ("<dataset_name>") | where name contains "<xxx>"
Specify Time Formats in Paths
If directories are partitioned as year, month, day, hour, second, use:
${_time:%<parameter>}For example:
. ${_time:%Y-%m-%d}Or:
<mybucket>/${_time:%Y}/${_time:%m}/${_time:%d}/...Or, if directories have earliest and latest in seconds, use those tokens:
<mybucket>/${__earliest/${__latest}/...If the path has multiple time ranges:
Use the most accurate field(s).
Name the other field conspicuously (examples.
time_from_dirorother_time).
Time Format Examples
If time in the directory format is:
<mybucket>/2024-128-19/xxx.gzThe path expression can be:
<mybucket>/prefix/${_time:%Y-%m-%d}If time in directory format is:
<mybucket>t/2024/08/19/The path expression can be:
<mybucket>/prefix/${_time:%Y}/${_time:%m}/${_time:%d}For the following example:
aws/12-17-2024/db_0507829470_1165276110_8475_4288F9E6-9A3A-43B4-CCE9-4247DB82FCF9.csv.gzThe path expression can be:
aws/${other_time}/db_${latest}_${earliest}_$(bucketid}_${suffix}.${extension}Specific Versus Parameterized Dataset Paths
With specific file paths, you avoid repository=* problems:
<bucket>/sophos/${_time:%m}-${_time:%d}-${_time:%Y}/
<bucket>/okta/${_time:%m}-${_time:%d}-${_time:%Y}/But to maximize search performance, parameterize your path structure, while specifying as many of the available parameterized fields as possible. Consider this structure:
<bucket>/${repository}/${_time:%m}-${_time:%d}-${_time:%Y}/A simple query term like this would retrieve files from all repositories:
dataset=cribl_lake_logsWhereas a specification like this - over the same timeframe - would filter for a much smaller subset of files. This would produce a faster and more efficient search:
dataset=cribl_lake_logs repository=okta