



Searching Multiple Providers
Set up and search multiple Dataset Providers.
Cribl Search supports searching across multiple providers. In this example, we will illustrate how to configure and search logs across all three major object stores (Amazon S3, Azure Blob, and Google Cloud Storage).
Why would you want to search multiple providers, you might ask? Here are a few reasons:
- Investigate the same data across multiple providers more quickly (for example, by flowing logs across all three main providers).
- Ensure conformance across all object stores - Eventually you’re going to have to search data across multiple object stores; to make sure they all follow the same standard, use Cribl Search to run conformance-based searches.
- Give users access to the data - Analytics systems can be expensive. What if those infrequent or ad hoc users could access your data through Cribl Search without incurring additional downstream licensing or cloud egress costs?
- Analyze historical data before replaying to your analysis system - We often need to review historical data for investigations, capacity exercises, or other reasons. Instead of replaying or rehydrating all the data for a given time, Cribl Search allows you to find the relevant data PRIOR to rehydrating.
- And more!
So now that you know searching across multiple providers can be useful, let’s connect your object stores and start searching.
Connecting the Providers
This example searches Virtual Private Cloud (VPC) flow logs stored in Amazon S3, Azure Blob, and Google Cloud Storage.
Configuring and Routing VPC Flow Logs
VPC flow logs enable you to capture information about the IP traffic going to and from network interfaces in your VPC. For details on how you can configure the flow logs to be routed to each provider’s storage object, see:
- Amazon S3: Publish flow logs to Amazon S3
- Azure Blob: Create a flow log and traffic analytics workspace
- Google Cloud Storage: Route logs with the Log Router
To process your VPC flow logs faster, use the AWS VPC Flow Log event breaker.
Configuring Cribl Search Data Providers
Once you have flow logs available in the respective object stores, you can set up data providers in Cribl Search to access the logs.
To give all three Datasets a uniform naming convention, append each Dataset ID with _flowlogs. This option allows
us to use a wildcard in the query. For details, see the section below on
Running a Search Across Multiple Dataset Providers.
Additionally, you can combine data from different Datasets in a single query by specifying each Dataset’s ID. For
example: dataset=myAWSFlowlogs or dataset=myGCSFlowlogs or dataset=myAzureFlowlogs. For details, see
Syntax.
Amazon S3
Let’s get started by setting up your Amazon S3 Dataset Provider and Dataset in Cribl Search.
Google Cloud Storage (GCS)
In Cribl Search, create a Google Cloud Storage Dataset Provider and Dataset.
Azure Blob
In Cribl Search, create an Azure Blob Dataset Provider and Dataset.
Running a Search Across Multiple Dataset Providers
We now have all three providers configured within Cribl Search. It’s time to run some searches.
Since we appended the Dataset IDs with _flowlogs, this allows us to run the first search and combine data from all
three Datasets:
dataset="*_flowlogs"
| limit 1000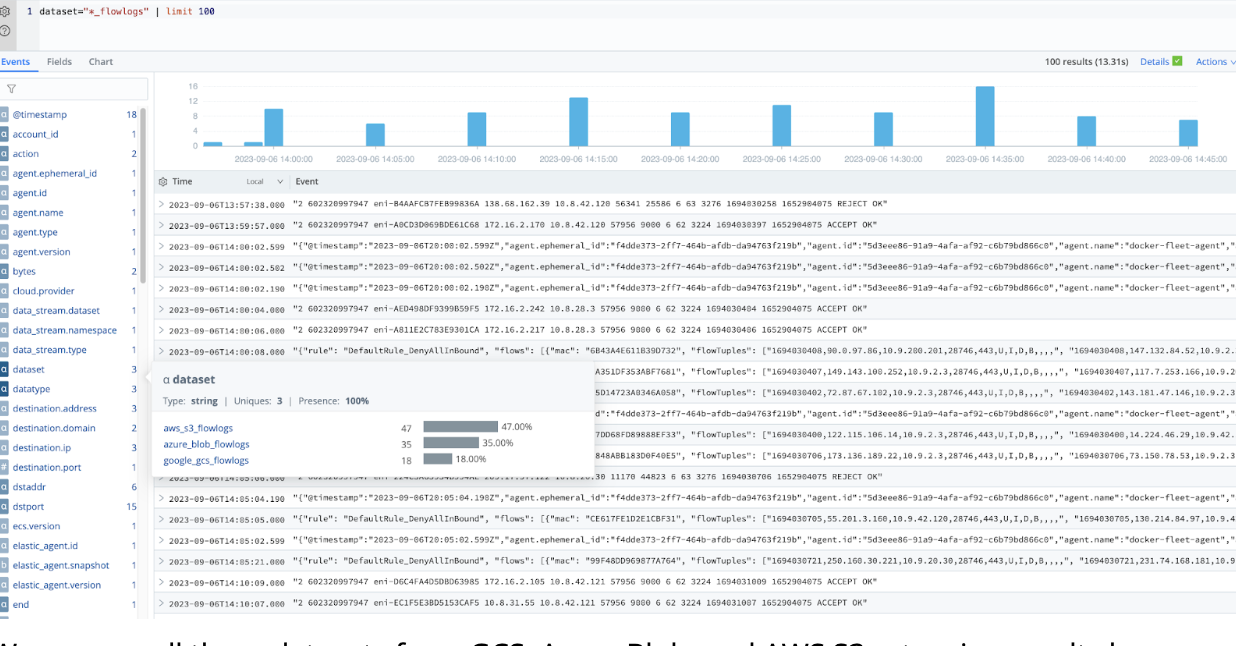
We can see all three Datasets from GCS, Azure Blob, and Amazon S3 returning results here. With Cribl Search, you can easily gather all your flow logs from your multi-cloud environments for analysis.
Let’s take that search and turn it into a Bar Chart with counts of each Dataset’s flow log. Flow log volumes can be visualized for each provider to identify anomalies.
dataset="*_flowlogs"
| summarize flowcount=count() by Dataset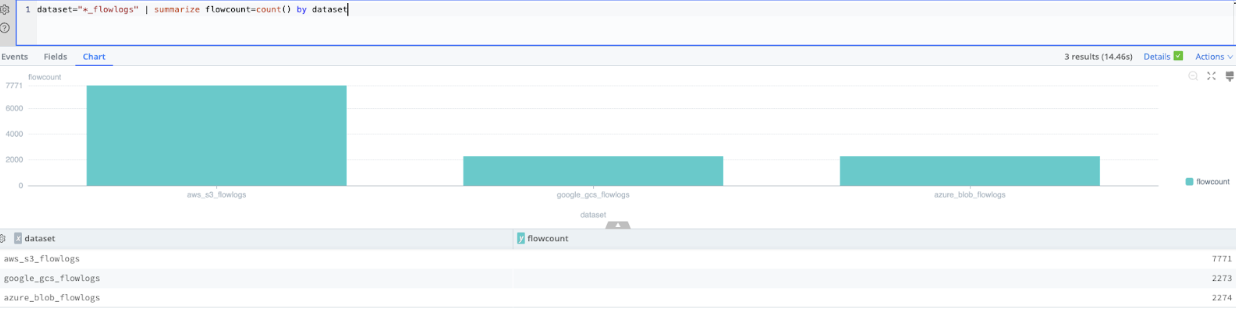
It’s likely that the three providers will also share fields. They are, however, not normalized. For our Amazon S3 flow
logs, we already have a dstport; however, Azure organizes flow logs into tuples from which we must extract the
destination port.
As part of the next search, we try to accomplish just that, and then go one step further by using the
coalesce function to create a normalized field, Destination_Port, across our Azure and Amazon S3 flows.
It’s also possible to create Datatypes with normalized fields for each Dataset. For details, see v1 Datatypes.
Now that we’ve normalized fields, we can analyze data across all three providers agnostically.
dataset="*_flowlogs"
| limit 1000
| extract type=regex regex=@"\d+,([^,]*,){3}(?<dst_port>\d+)"
| extend Destination_Port= coalesce(dst_port, dstport)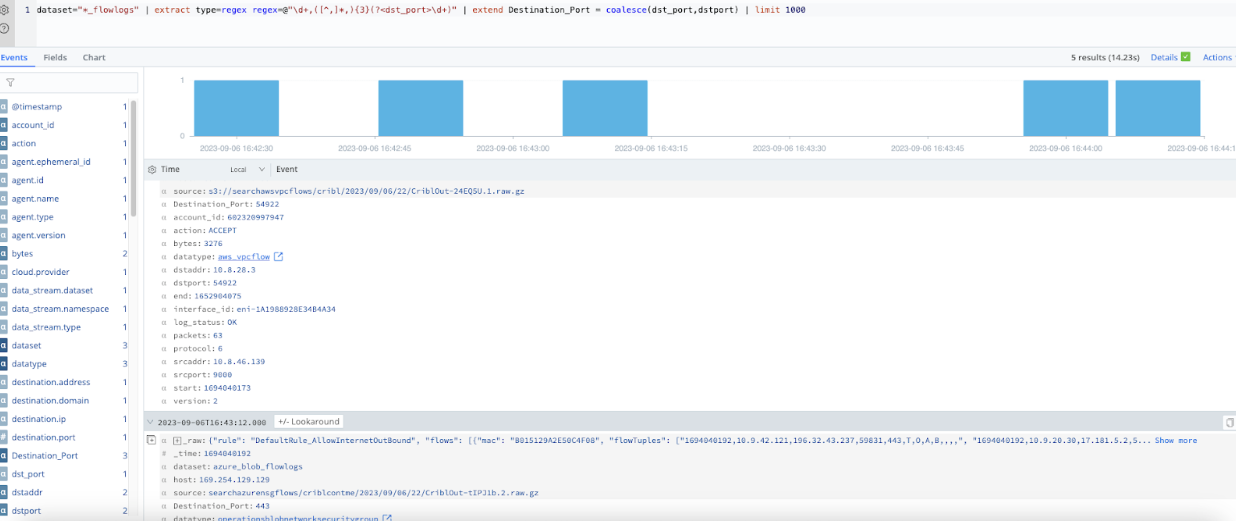
Conclusion
Multi-cloud environments and object stores continue to grow in popularity, and Cribl Search allows you to bring all of those Datasets together, normalize them, and generate insights across all platforms at once rather than keeping them separated.