



Connect Cribl Search to Azure Blob Storage
Configure Cribl Search to query your Azure Blob Storage data, including v2 Datasets and Private Link connectivity.
Azure Blob Storage enables users to store large amounts of unstructured data on Microsoft’s data storage platform. Blobs are binary large objects, including images and multimedia.
In this guide, you’ll set up a Dataset Provider and a Dataset to search objects in Azure Blob Storage. You can route all data traffic over Azure Private Link or the public internet.
Data transfer costs and other charges might apply. For details, see Data Transfer Charges below.
Add an Azure Blob Storage Dataset Provider
A Dataset Provider tells Cribl Search where to query and contains access credentials. Here, you will add an Azure Blob Dataset Provider.
To add a new Dataset Provider, select Data, then Dataset Providers, then Add Provider.
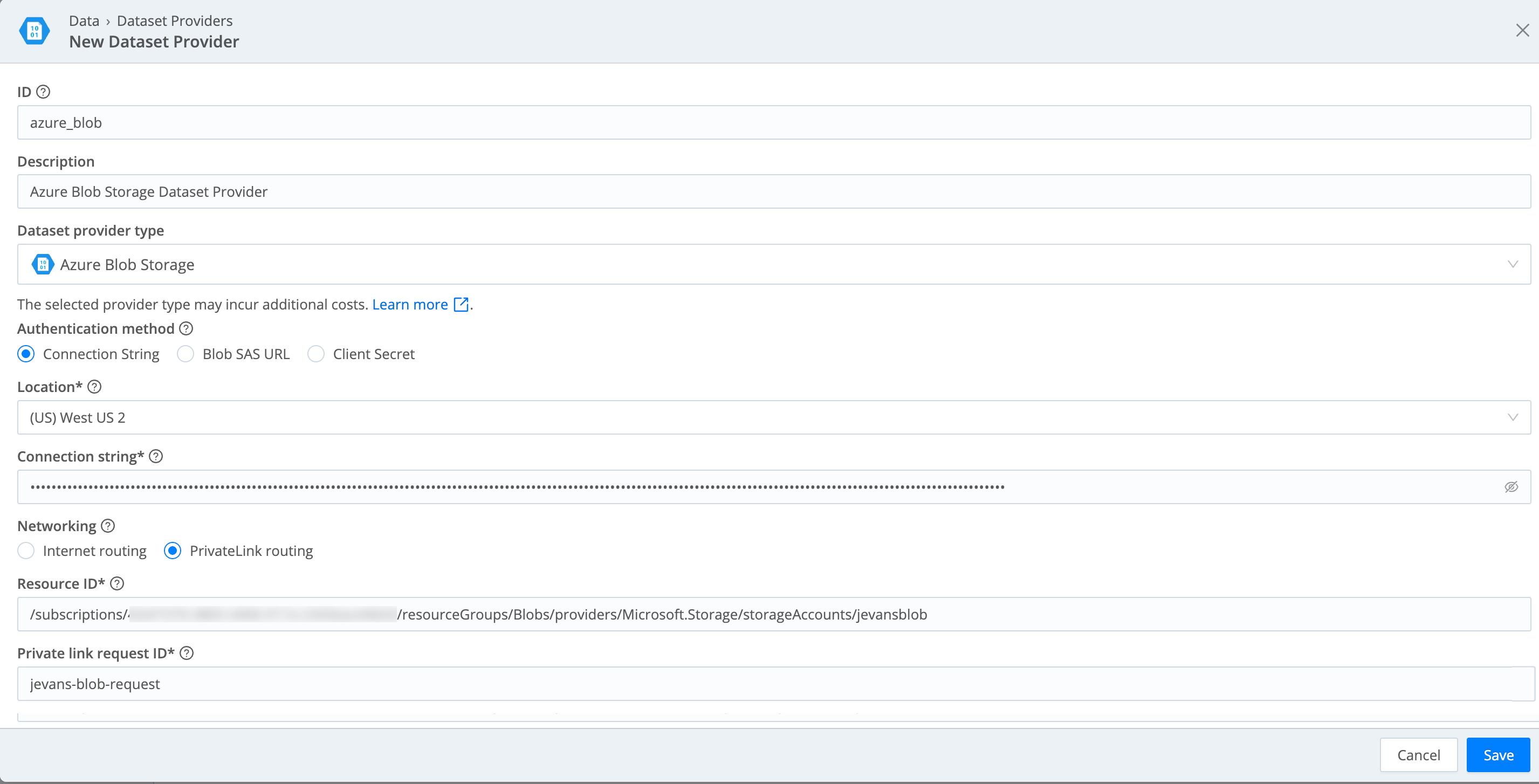
Configure the New Dataset Provider modal as follows:
- ID is a unique identifier for the Dataset Provider. This is how you’ll reference it when assigning Datasets to
it. Start the ID with a letter; the rest of the ID can use letters, numbers, and underscores (for example,
my_dataset_provider_1). - Description is optional. Here, you can enter a summary that will clarify this Dataset Provider’s purpose to other users.
- Set the Dataset Provider Type to
Azure Blob. - Authentication method provides three options, Connection String, Blob SAS URL, and Client Secret. For details on each option, see the next section.
- Optionally, configure Private Link connectivity in the Networking section. See Configure Private Link below.
- Select Save when finished.
Azure Blob Storage Authentication
Your Azure Blob Storage access policy should include the Read and List permissions.
In the Cribl Search New Dataset Provider modal, use the Authentication method buttons to select one of these options:
Connection String
The Connection String gives admin-level access to Search. This includes the authorization information required to access data in your Azure Storage account at runtime using Shared Key authorization. See the Azure Blob Storage documentation for more details. To view and copy your storage account connection string from the Azure portal:
- In the Azure portal, go to your storage account.
- Under Security + networking, select Access keys. Your account access keys appear, as well as the complete connection string for each key.
- Select Show keys to show your access keys and connection strings and to enable buttons to copy the values.
- Copy the entire Connection string of the key you want to use.
In the Cribl Search New Dataset Provider modal, enter the following information under Authentication method.
- Location is your Azure account region, for example,
East US. This can be found on the Azure portal Overview page. See the Azure Blob Storage documentation for more details. - Connection String is where you paste the Connection string of the key you want to use.
- Select Save when finished.
Blob SAS URL
Blob SAS URL provides a more-restrictive access token called a “Shared Access Signature”, which allows the user to specify which resources to grant access to. For details see, Create SAS tokens for your storage containers. To create SAS tokens for your storage containers:
- In the Azure portal, navigate to your container.
- Right-click the container or file and select Generate SAS from the drop-down menu.
- Specify the permission levels, allowed IP addresses, and allowed protocols.
- Review and then select Generate SAS token and URL.
- The Blob SAS token query string and Blob SAS URL are displayed in the lower area of the window.
- Copy and paste the Blob SAS token and URL values in a secure location. They’ll only be displayed once and cannot be retrieved once the window is closed.
In the Cribl Search New Dataset Provider modal, enter the following information under Authentication method.
- Location is your Azure account region, for example,
East US. This can be found on the Azure portal Overview page. See the Azure Blob Storage documentation for more details. - Select Add configurations to specify the container(s).
- Container Name is the name of the Azure Blob Storage container.
- Blob SAS URL is where you paste the container-specific Blob SAS URL.
- Select Save when finished.
Client Secret
The Client Secret is a type of authentication available for a service principal of your Microsoft Entra (formerly Azure Active Directory) application. To use this authentication method, first do the following in your Azure account:
- Create and register a service principal for your Microsoft Entra application. To find out how, see Register a Microsoft Entra app and create a service principal from Microsoft.
- Grant the service principal access to your data. To find out how, see Authorize access to blobs using Microsoft Entra ID.
In the Cribl Search New Dataset Provider modal, enter the following information under Authentication method.
- Location is your Azure account region, for example,
East US. - Storage account name is the name of your Azure storage account.
- Tenant ID is your Microsoft Entra tenant ID. To find it, see How to find your Microsoft Entra tenant ID.
- Client ID is the client ID of the Azure service principal. To find it, see Sign in to the application.
- Client secret is the secret to use when connecting to your Microsoft Entra application. To get it, see Create a new client secret.
Configure Private Link
Before you begin, make sure you have an Azure subscription with a storage account that contains your data, and permission to approve Private Endpoint connections on that storage account.
Required Azure permissions:
- Microsoft.Storage/storageAccounts/privateEndpointConnections/read
- Microsoft.Storage/storageAccounts/privateEndpointConnections/write
Or have one of the built in Azure roles:
- Owner
- Contributor
- Storage Account Contributor
Use the Networking section of the New Dataset Provider modal to configure Private Link connectivity:
- Resource ID is the Azure Resource Manager resource ID for your storage account.
- Private link request ID is a free-form string of your choice with a 50-character limit. It appears as the description of the pending
Private Endpoint connection in your Azure account. Choose a value that lets you identify this specific connection
later when you go to approve it – for example,
cribl-search-prod.
To find the Resource ID in your Azure account:
- Navigate to your Azure Blob storage account.
- On the Overview page, in the Essentials section, select JSON View.
- The resource ID for the storage account appears at the top of the Resource JSON page.
For more details, see Get the resource ID for a storage account in the Azure documentation.
Add an Azure Blob Storage Dataset
Now you’ll add a Dataset that tells Cribl Search what data to search from the Dataset Provider.
To add a new Dataset, select Data, then Datasets, then Add Dataset.
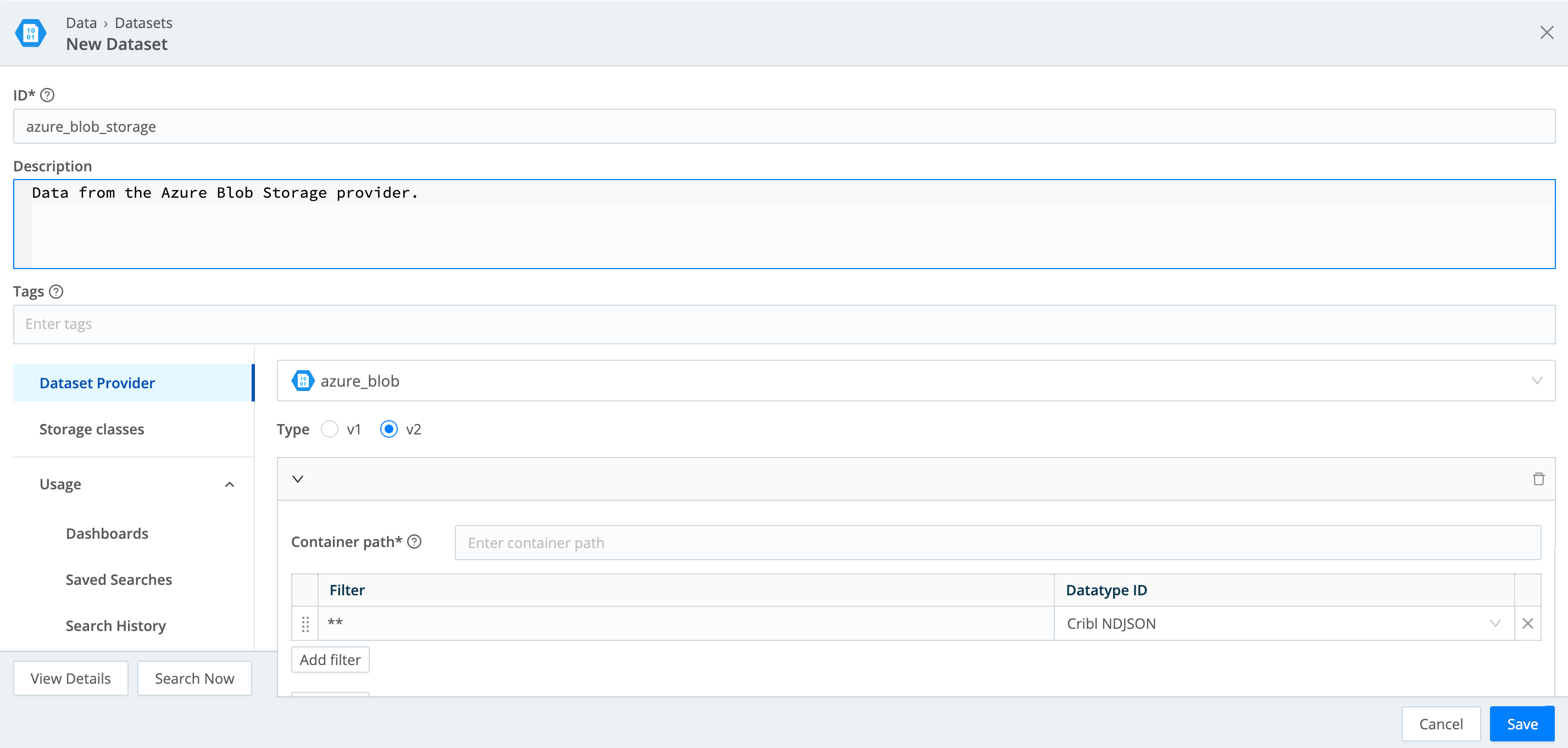
Configure the New Dataset modal as follows.
Identify the Dataset
Use the first few fields to uniquely identify this Dataset and specify its type:
- ID is an identifier unique for both Cribl Search and Cribl Lake. Start the ID with a letter; the rest of the ID can use letters, numbers, and underscores (for example,
my_dataset_1). You’ll use this to specify the Dataset in a query’s scope, telling Cribl Search to search the Dataset (for example,dataset=my_dataset_1). - Description is optional. Here, you can enter a summary that will clarify this Dataset’s purpose to other users.
- Set Dataset Provider to the ID of an Azure Blob Dataset Provider.
- Set Type to v1 (standard, the default) or v2. v2 Datasets support faster search and Private Link connectivity but require NDJSON or delimited text format. If you select v2, see v2 Dataset Configuration for the remaining steps.
v2 Dataset Configuration for Azure Blob
If you’re switching from v1 to v2, first see Federated Search v2 to see what’s currently supported.
For v2 Datasets, configure the following fields:
- Container path is the path to the Azure Blob Storage container that holds your data. Supports templating. See the Azure Blob Storage documentation for details.
- Filters narrow the search to specific objects and map them to a Datatype. Add one or more filter rows. Each row
has:
- Filter: A glob expression (for example,
**for all objects, or**/*.ndjsonfor NDJSON files). - Datatype ID: The Datatype for matching files. Use Cribl NDJSON (
generic_ndjson) or a delimited-text Datatype. v2 supports only NDJSON and delimited formats.
- Filter: A glob expression (for example,
- Select Save when finished.
Glob Patterns
The path filter supports using glob patterns when indicating the path. The following glob patterns are available.
| Pattern | Matches |
|---|---|
* | Matches one path segment (any sequence of characters except /). |
? | Matches any single character except /. |
** | Matches any sequence of characters except { and }, but including /. Can match multiple segments, but not brace syntax. |
{a,b,c} | Matches one of the comma-separated alternatives provided in the braces. Alternatives must not contain {, }, *, or ,. |
{M..N} | Matches a numeric range of non-negative integers. Examples: {0..9}, {10..99}. Leading zeros are supported (for example: {001..099}). |
Negations
You can negate brace content by using !, for example:
!{a,b,c}– path must not match any of the alternatives.!{0..9}– path must not match the numeric range.!{foo}– path must not match the literalfoo.*!{...}- path matches anything that does not match the provided suffix.
Escaping
\ (backslash) is the escape character for glob patterns.
\!{ matches a literal !{ in the path (for example, a directory named !{temp}).
Set Up Paths, Regions, Partitioning
For v1 Datasets, define at least one path, region, and partitioning configuration:
- Skip event time filter is optional. Toggle this on only if you’re sure you want to set the time range of your searches by partition time-boundaries rather than events’ timestamps
- Container path is the Azure Blob Storage container with your data. Start the path with the container name, and then add partitioning details. Tokens and key-value pairs are supported (see Azure Blob Storage Container Paths).
- Path filter is a JavaScript filter expression that is evaluated against the container. Defaults to
true, which matches all data, but you can customize this value. - The Partitioning scheme defaults to
Defined in Path. For Splunk-specific alternatives, see Azure Blob Storage Partitioning Scheme.
Multiple Path Configs
Select Add container/path to define as many other path configurations as you want for this Dataset. Each path can have its own filter and partitioning scheme.
As with parallel Datasets, each partitioning scheme applies per path. When searching a Dataset, Cribl Search will search all its configured paths. However: a failed search on any of a Dataset’s paths will fail the whole search.
Set Up Datatypes and Storage Classes
On the Processing left tab, you specify Datatypes to break data down into discrete events and define fields so they’re ready to search.
Use the drop-down to set the first rule to AWS Datatypes. Optionally, click Add Datatype Ruleset to select more
rulesets - each of which contains rules applied to the data searched in your Dataset. For details, see
Datatypes.
On the Storage classes left tab, select the access tiers that you want this Dataset to search against. You can minimize retrieval costs by selecting only warmer tiers. You must select at least one tier. For details, see Storage Classes.
Use v2 Datatype for Azure Blob Datasets when your data is NDJSON or Delimited Text. For other formats, use v1 Datatypes. For details, see Datatypes.
Save the Configuration
Bypass the Usage left tabs for now, and select Save when your configuration is complete.
Approve the Private Endpoint in Azure
After you save a Dataset Provider configured for Private Link, Cribl Search submits a Private Endpoint connection request to the Azure storage account identified by the Resource ID. You must approve this request before searches can run. This requirement occurs once per storage account.
To approve the connection:
- In the Azure portal, navigate to the storage account you specified in the provider’s Resource ID.
- Under Security + networking, select Networking.
- Select the Private endpoint connections tab.
- Find the pending connection whose Description matches the Private link request ID you entered in Cribl Search.
- Select the connection and choose Approve.
- Confirm the approval when prompted.
The connection status changes from Pending to Approved. Allow a few moments for the change to propagate before running a search.
Path/Partitioning Considerations
This section offers details and guidance on configuring search paths, filters, and partitioning schemes. For best practices covering path design across all object stores, see Optimize Paths.
Azure Blob Storage Container Paths
Each Container path specifies a separate blob of data within the Dataset. It defines the scope of this data, to narrow down what data is in the Dataset. This field supports tokens and key-value pairs. For example:
mycontainer/data- wheredatabecomes a field for all events of that Dataset.mycontainer/${data}/${*}- equivalent, the wildcarded path is skipped.mycontainer/<key=value>/<someVarOfInterest>- see Hive-Style Paths just below.mycontainer/<path>/${_time:%Y}/${_time:%m}/${_time:%d}/${_time:%H}/- time-based partitioning.
Hive-Style Paths
To search paths of the form my-bucket/<key=value>/<someVarOfInterest>, your expression should place the wildcard {*}
in the ordinal position, to ignore the hive (K-V) segment:
my-bucket/${*}/${someVarOfInterest}
This will allow Cribl Search to find the wildcarded subdirectory automatically.
Basic Tokens
Basic tokens’ syntax follows that of JS template literals: ${token_name} - where token_name is the field (name) of interest.
For example, if the path was set to /var/log/${hostname}/${dataSource}/, you could use a filter such as hostname=='myHost' && dataSource=='mydataSource' to specify data only from the /var/log/myHost/mydataSource/ subdirectory.
Time-Based Tokens
Paths with time notation can be referenced with tokens, having a direct effect on the earliest and latest boundaries. The supported time fields are:
_timeis the raw event’s timestamp.__earliestis the search start time.__latestis the search end time.
Time-based tokens are processed as follows:
- For each path, times must be notated in descending order. So Year/Month/Day order is supported, but Day/Month/Year is not.
- Paths may contain more than one time component. For example,
/my/path/2020-04/20/. - In a given path, each time component can be used only once. So
/my/path/${_time:%Y}/${_time:%m}/${_time:%d}/...is a valid expression format, but/my/path/${_time:%Y}/${_time:%m}/${host}/${_time:%Y}/...(with a repeatedY) is not supported. - For each path, all extracted dates/times are considered in UTC.
Cribl recommends that your path always include and tokenize the largest available time fields, proceeding down to the smallest desired time fields. Otherwise, your searches might yield unexpected results, because Cribl Search will default the omitted fields to their earliest allowed value.
The following strptime format components are allowed:
Y,yfor yearsm,B,b,efor monthsd,jfor daysH,Ifor hoursMfor minutesSfor secondssfor Unix time (seconds since 1/1/1970)
Time-based token syntax follows that of a slightly modified JS template literal:
${_time: some_strptime_format_component}. Examples:
| Path | Matches |
|---|---|
/path/${_time:%Y}/${_time:%m}/${_time:%d}/... | /path/2020/04/20/... |
/path/${_time:year=%Y}/${_time:month=%m}/${_time:day=%d}/... | /path/year=2020/month=05/day=20/... |
/path/${_time:%Y-%m-%d}/... | /path/2020-05-20/... |
Set Query Time Range by Partition
If your data is partitioned by time (so your paths probably use time-based tokens), you can tell Cribl Search to ignore events’ timestamps, and instead set the time range using the partition time-boundaries.
For example, an event with the timestamp of 2025-07-01T23:59:00.000 might be stored in the July 2 partition. Queries
for July 1 or July 2 might not find it: the first due to wrong partition, the second due to wrong _time. Using
partition time for the query range avoids this issue.
To search by partition time range, toggle on Skip event time filter when setting up your paths. Then, any
time range you set (in the Cribl Search UI or with earliest/latest in the query text) will use partition time
instead of event time.
If you toggle on the Skip event time filter option, Cribl Search will ignore the
_timefield in your events. Do not enable this option if your paths don’t use time-based tokens.
Azure Blob Storage Path Filter
Each Path filter is a JavaScript expression that Cribl Search evaluates against the corresponding
Container path. The Path filter field’s value defaults to true, which matches all data. However, you can
customize this value almost arbitrarily.
For example, if a Dataset has this Path filter:source.endsWith('.log') || source.endsWith('.txt')
…this configuration will search only files/objects with .log or .txt extensions.
At the Path filter field’s right edge are a Copy button and an Expand button that opens a validation modal.
With DDSS or SmartStore partitioning, you can provide the index name as Path filter, for example:
index=="index_y".
Azure Blob Storage Partitioning Scheme
Each Partitioning scheme drop-down offers alternative options for partitioning inbound data from Splunk. You can
choose between Splunk DDSS and
Splunk SmartStore.
With either option, in the corresponding Container path field, provide the path where indexes are stored (that is, your index’s parent folder).
For Splunk DDSS, the full path takes the form:<parent_folder>/<indexName>/db/db_<latestTime>_<earliestTime>_<bucketId>/rawdata/journal.gz|lz4|zst
…or:<parent_folder>/<indexName>/db_<latestTime>_<earliestTime>_<bucketId>/rawdata/journal.gz|lz4|zst
For SmartStore, the full path takes the form:<parent_folder>/<indexName>/db/<2-letter-hash>/<2-letter-hash>/<bucket_id_number-origin_guid>/<"guidSplunk"-uploader_guid>/
With either option, if you organize your container using this default file path, Cribl Search will automatically discover its content.
Search Azure Blob Storage
Now that you have a Dataset Provider and Dataset, you’re ready to start searching.
It can take a few minutes for a search to start returning results.
Data Transfer Charges
Cribl Search uses both Read and Iterative Read Operations in Azure Blob Storage. To understand the fees associated with these operations, refer to Azure Blob Storage’s Operation and data transfer.
Additionally, retrieval fees may apply depending on the storage tier used. For details, see Microsoft’s Retrieval Fees topic.
Using Cribl Search to read data from the Azure data centers might also result in Data transfer charges for egress. For detailed information, refer to Microsoft’s Data Transfer pricing.