



Connect Cribl Search to Cribl Lake
Configure Cribl Search to query your Cribl Lake or Lakehouse data.
Cribl Lake Datasets work as Cribl Search Datasets out-of-the-box, so you can instantly start searching them.
You can assign Lake Datasets to Lakehouses, for dramatically faster search responses and more-predictable billing.
Where you need direct ownership of your data, for compliance or other purposes, you can use Storage Locations to create Lake Datasets directly on Amazon S3 or Azure Blob Storage. You can choose the storage class or access tier that Cribl Lake uses when writing objects; S3 Datasets default to the Standard storage class, and Azure Datasets default to the Inferred access tier.
For more information on Lake and Lakehouses, see the Cribl Lake docs.
Federated Search: Dataset Types v1 and v2
Lake-backed Search uses Dataset Type v1 or v2 on a Federated Dataset tied to the Lake Dataset Provider
(cribl_lake or equivalent). Dataset Type v2 supports newline-delimited JSON and Parquet objects in Lake storage.
DDSS Lake Datasets require Dataset Type v1.
Use Dataset Type and filters for Lake Datasets for configuration steps. For limits and migration, see Federated Search v2.
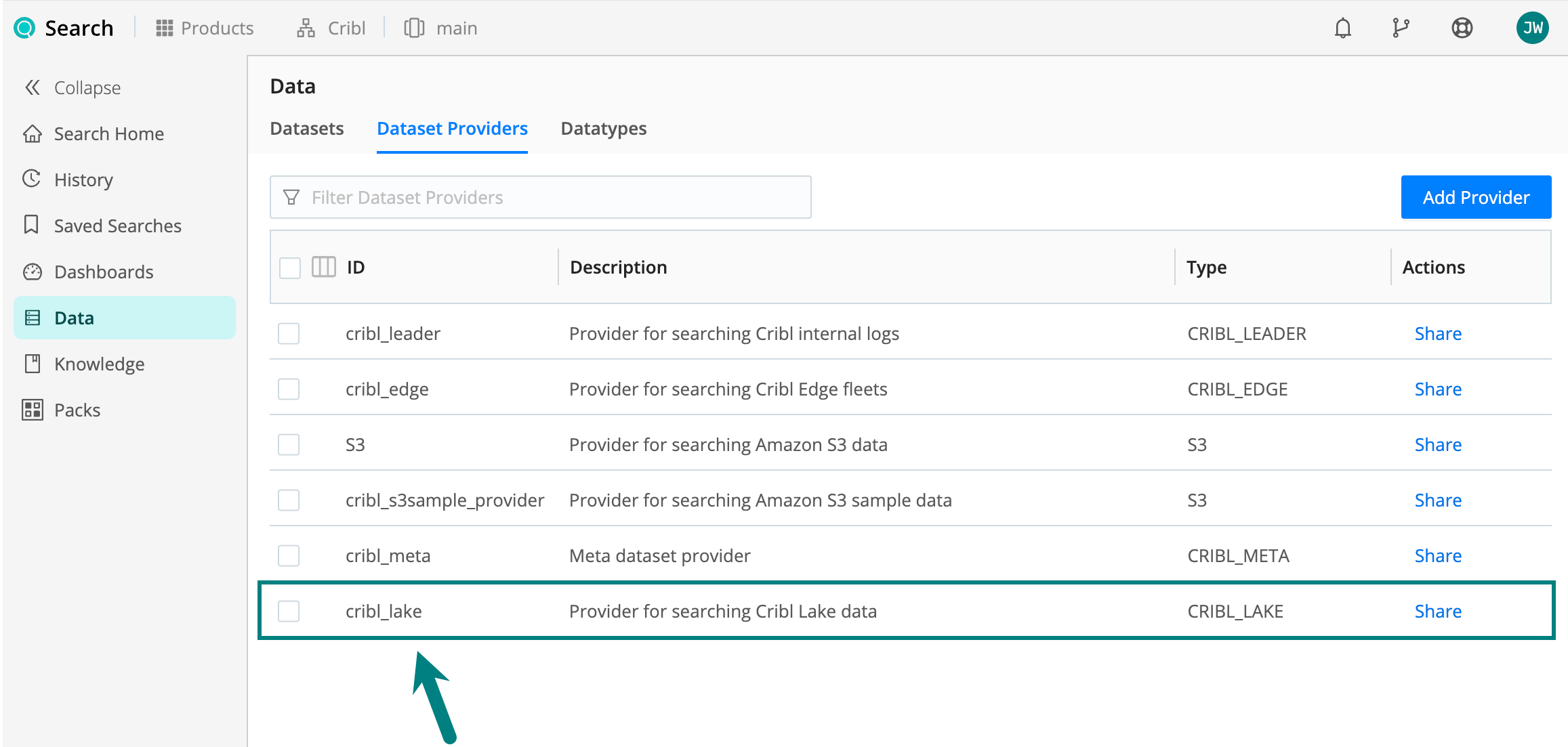
Add a Cribl Lake Dataset Provider
Cribl Search comes with a preconfigured Dataset Provider for Cribl Lake (called cribl_lake), so you don’t need to add
it explicitly.
You can see it by going to Products (on the top bar) > Search > Data > Dataset Providers.
Add a Cribl Lake Dataset
Create the Lake Dataset in the Cribl Lake UI first. See Create a New Lake Dataset.
In Cribl Search, add or select the matching Federated Dataset to set Dataset Type and Type v2 filters. See Dataset Type and filters for Lake Datasets.
Dataset Type and Filters for Lake Datasets
Add or Edit a Lake Dataset
- Select Products > Search > Data > Datasets.
- Select an existing Lake-backed Dataset, or select Add Dataset to create one.
- Under Dataset kind, select Federated Dataset (for data hosted in Cribl Lake).
- Set Dataset Provider to your Lake provider.
Set Dataset Type (v1 or v2)
- Set Type to v1 or v2.
To adopt Dataset Type v2 from an existing v1 Dataset, clone the Federated Dataset and set Type to v2 on the clone, then configure paths and filters. See Switch a Federated Dataset from v1 to v2.
Configure Paths and Filters for v2 Datasets
When you set Type to v2, you’ll configure fields that match other federated Type v2 Datasets (see v2 Dataset Configuration for Amazon S3 for shared concepts):
- Bucket path: Path to the Lake objects Cribl Search reads.
- Auto-detect region / Region: Select the region in which your Lake data is stored.
- Partitioning scheme: For example Defined in Path, consistent with your Lake layout.
- Filters: Add up to two rows for Lake. Each row sets:
- Filter: A glob over object paths (for example,
**with a JSON Lake Dataset for NDJSON, or**/*.parquetfor Parquet). - Datatype ID: For example,
generic_ndjsonfor newline-delimited JSON, orcribl_lake_parquetfor Parquet Lake objects.
- Filter: A glob over object paths (for example,
On a Parquet Lake Dataset, enabling Type v2 can auto-populate **/*.parquet → cribl_lake_parquet. For mixed
NDJSON and Parquet under one Lake Dataset, add two rows - Cribl Search routes each object using the matching glob. Put
more specific patterns before broad globs such as **, as described under Glob Patterns.
For Parquet-backed events, _time is read from the Parquet _time column; host, source, and sourcetype from
Parquet columns with those names.
Select Save.
Dataset Type v2 and DDSS
Do not use Dataset Type v2 for Lake Datasets whose storage format is DDSS. Keep Dataset Type v1. See Splunk Cloud Self Storage (DDSS) Direct Access.
Send Cribl Search Results to Cribl Lake
After you create a Dataset in Cribl Lake, you can send Cribl Search
results to it, using the export operator. Here is a simple example:
// export Cribl Search results to an existing Lake Dataset
dataset="cribl_search_sample"
| export to myLakeDataset(You can find more export examples here.)
Typically, you’re exporting data in which Cribl Search has already parsed field names and values. This makes the data compatible with Lakehouses. However, if you happen to send unparsed data, you won’t be able to search it at Lakehouse speed.
Search a Cribl Lake Dataset
You can query your Lake Datasets just like any other Search Datasets. See Searching Cribl Lake for some query examples.
Search a Lakehouse
Searching a Lake Dataset that’s linked to a Lakehouse is significantly faster, as long as your query’s time range falls within the configured Lakehouse retention period.
Queries that access older data (still stored in the Dataset, but aged out of the Lakehouse) will run at standard search speed.
To create a new Lakehouse, see the Cribl Lake docs: Add a New Lakehouse.
See how to:
- Find Out if a Dataset is Linked to a Lakehouse
- Verify Lakehouse Use
- Search Multiple Lakehouse Datasets
- Disable Lakehouse Use
See also: Cribl Search Differences with Lakehouse.
Find Out if a Dataset is Linked to a Lakehouse
To see if a Dataset you’re about to search is linked to a Lakehouse or not, look for the
 icon. For example, look at the list of available datasets in your Search
Home:
icon. For example, look at the list of available datasets in your Search
Home:
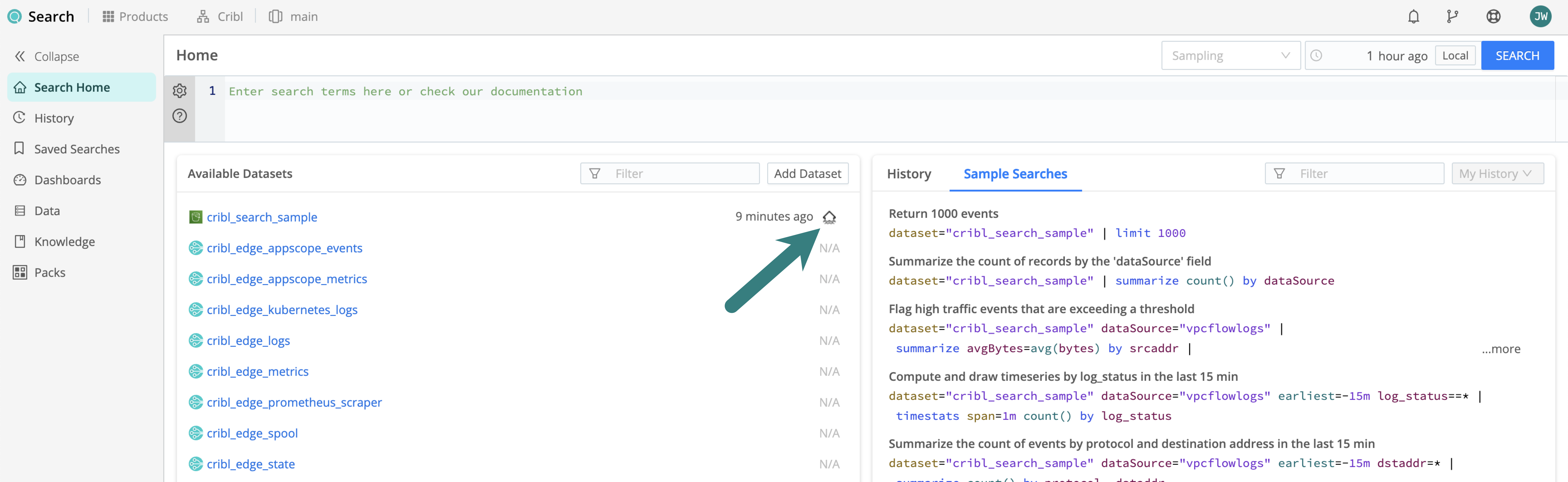
You can also go to Products (on the top bar) > Search > Data > Datasets and look at the Lakehouse column.
Verify Lakehouse Use
To find out whether a search successfully used a Lakehouse, take a look at the tracking bar.
If the search failed to use a Lakehouse, the bar presents information about potential reasons.
Search Multiple Lakehouse Datasets
You can run a single query against multiple Lakehouse-assigned Datasets. For the query to execute at Lakehouse speed, all Datasets in the query must be Lakehouse-assigned, and your query must also meet one of these conditions:
Include only operators from the following group:
cribl,centralize,extend,extract,foldkeys,limit,mv-expand,pivot,project,project-away,project-rename,search, andwhere.Or, if you use any other operators, insert the
centralizeorlimitoperator before them. (Result counts will be further constrained by usage group limits.)
If neither of the above conditions is met, or if your query includes non-Lakehouse Datasets, the query will run at standard speed.
Disable Lakehouse Use
You can use a set statement with the lakehouse option
to control whether a query can use a Lakehouse or not.
For example, to test how a Dataset linked to a Lakehouse performs without it:
set lakehouse="off" dataset="lakehouse_dataset"Cribl Search Differences with Lakehouse
Executing Cribl Search queries against a Lakehouse-assigned Dataset changes some behavior and results, compared to executing the same queries without Lakehouse caching. For details, see Lakehouse Search Differences.