



Storage Classes
Control your costs by selectively enabling which object storage classes (access tiers) you want each Dataset to search.
For each Dataset that targets Amazon S3, Azure Blob Storage, or Google Cloud Storage, you can specify which storage classes the Dataset should search. (Azure refers to storage classes as access tiers.) This configuration option offers two advantages:
You can control costs by skipping over “colder” classes that are expensive to read.
You can avoid errors, because Cribl Search automatically skips over the classes that it cannot read on demand.
How Storage Classes (Access Tiers) Work
When you create a new Dataset on an object store Dataset Provider, the configuration modal’s Storage classes tab will default to a single class that offers rapid retrieval at low cost. As shown below, you can enable other storage classes that you want the Dataset to search.
By design, this tab omits classes that Cribl Search cannot search on the corresponding Dataset Provider. Objects in these classes can’t be read on demand, because they must first be rehydrated to a warmer class. (See also Handling Automatically Aged Objects below.)
At least one storage class must be selected, before you can save or resave the Dataset’s configuration.
Default Storage Classes
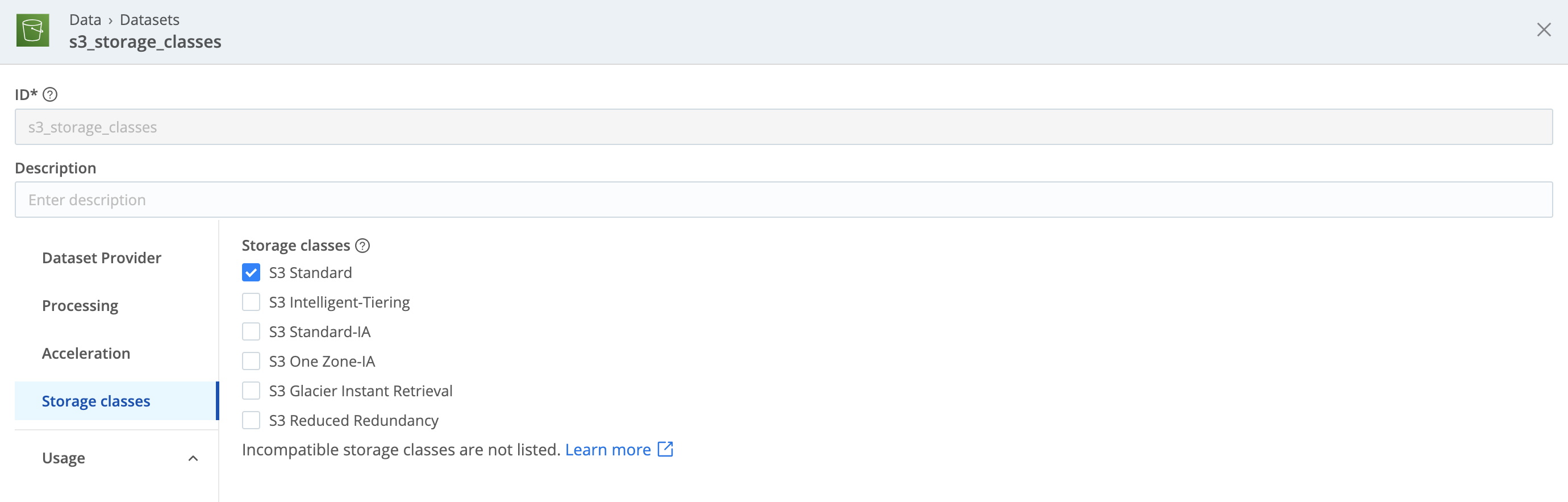
On Amazon S3 Datasets, the default storage class is S3 Standard. The tab omits unsupported tiers.
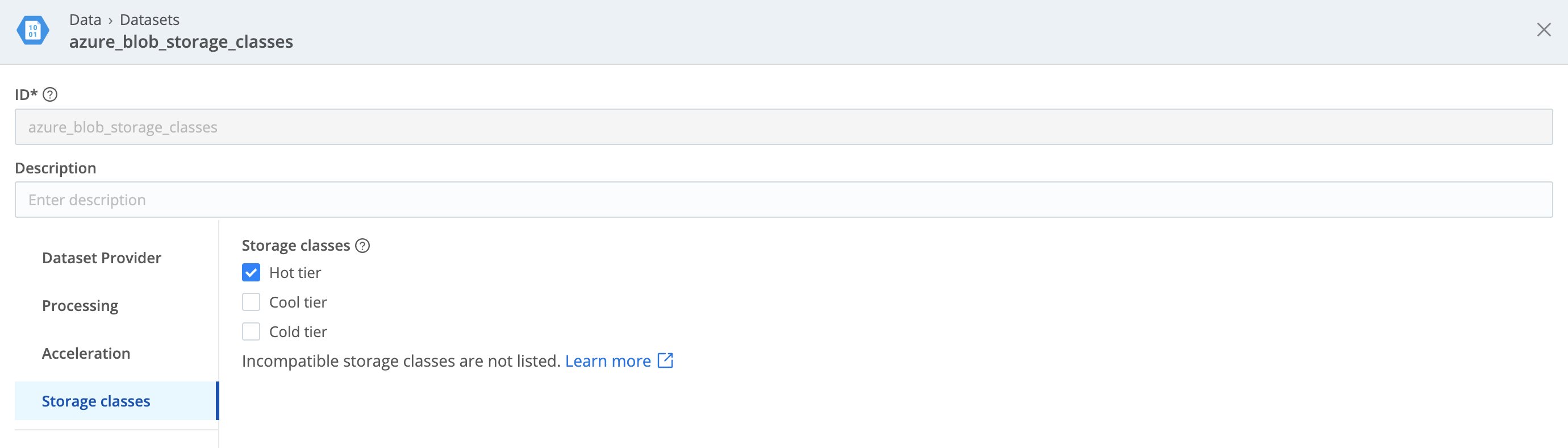
On Azure Blob Storage Datasets, the default storage class is Hot tier. The tab omits the unsupported archive tier.
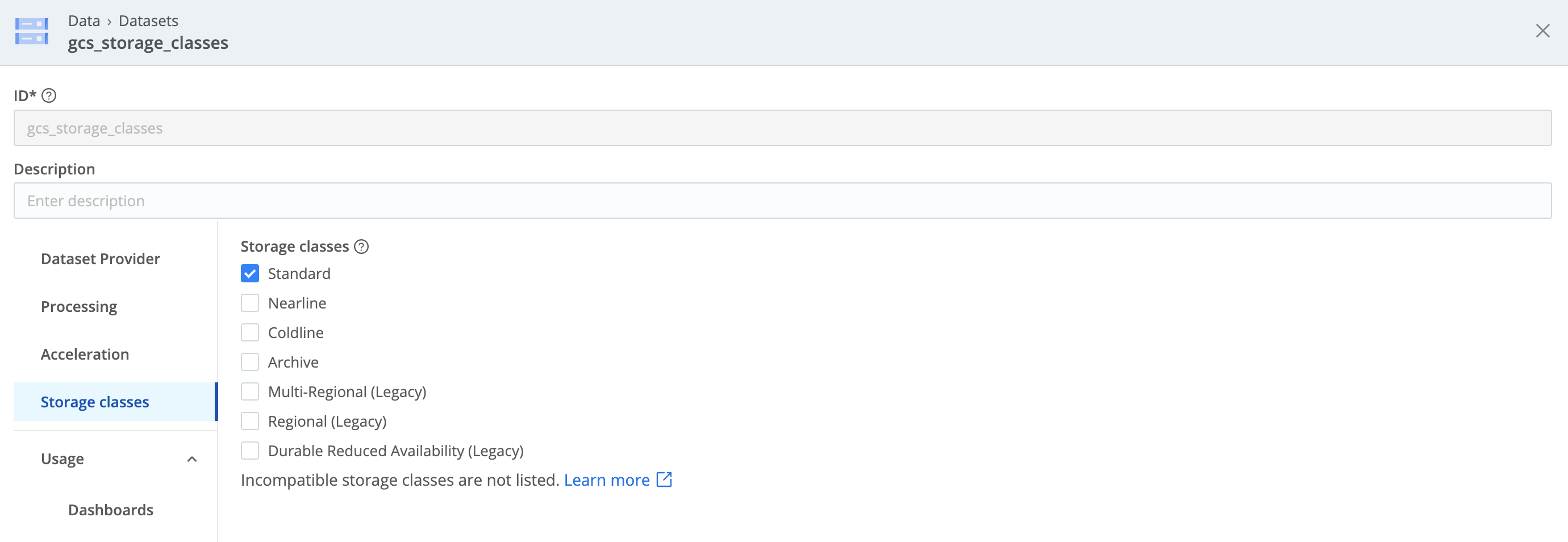
On Google Cloud Storage Datasets, the default storage class is Standard.
Storage Classes on Existing Datasets
On Datasets that were configured before Cribl Search added storage class selection, all supported storage classes are initially enabled. This is to avoid disruption to searches that you’ve scheduled, or that you explicitly rerun.
However, you can optimize your future costs by using the above options to deselect classes that have higher retrieval costs. As we’ll see next, these classes typically store older data that you’ll consider less relevant to your current searches.
Handling Automatically Aged Objects
On Amazon S3 Datasets, S3 Intelligent-Tiering is a storage class that you can enable, but objects will gradually age into archive tiers that effectively behave like Cribl Search’s unsupported Glacier tiers. On Datasets where you’ve enabled S3 Intelligent-Tiering, Cribl Search will try to read these objects, will gracefully skip them when reading fails, and will log a warning.
On Azure Blob Storage, enabling automatic lifecycle management, with a permissive policy, can similarly cause your blobs to age onto the archive tier. Blobs on this tier cannot be retrieved unless you rehydrate them into a warmer tier. Here, Cribl Search will similarly skip reading these blobs, and will log warnings. You can avoid the issue (and retain the option to make your data searchable) by configuring a lifecycle management policy that excludes the archive tier.
On Google Cloud Storage, enabling Autoclass behavior can similarly cause your blobs to age onto cooler tiers that you haven’t enabled your Dataset to search. Google Cloud Storage throws no warnings or errors, and will retrieve these objects at fast STANDARD speed (but with added retrieval costs). Therefore, be aware that enabling Autoclass can increase your costs.