



These docs are for Cribl Stream 4.0 and are no longer actively maintained.
See the latest version (4.17).
Event Breakers
Event Breakers help break incoming streams of data into discrete events. To see how Event Breakers interact with the rest of Cribl Stream’s data flow, see Event Processing Order.
You can use Cribl Edge to apply and author Event Breakers while exploring files - even files that you have not saved as sample files. This option includes remote files that are viewable only from Edge. See Exploring Cribl Edge on Linux or Exploring Cribl Edge on Windows.
Accessing Event Breakers
You access the Event Breakers management interface from Cribl Stream’s top nav under Processing > Knowledge > Event Breakers. On the resulting Event Breaker Rulesets page, you can edit, add, delete, search, and tag Event Breaker rules and rulesets, as necessary.
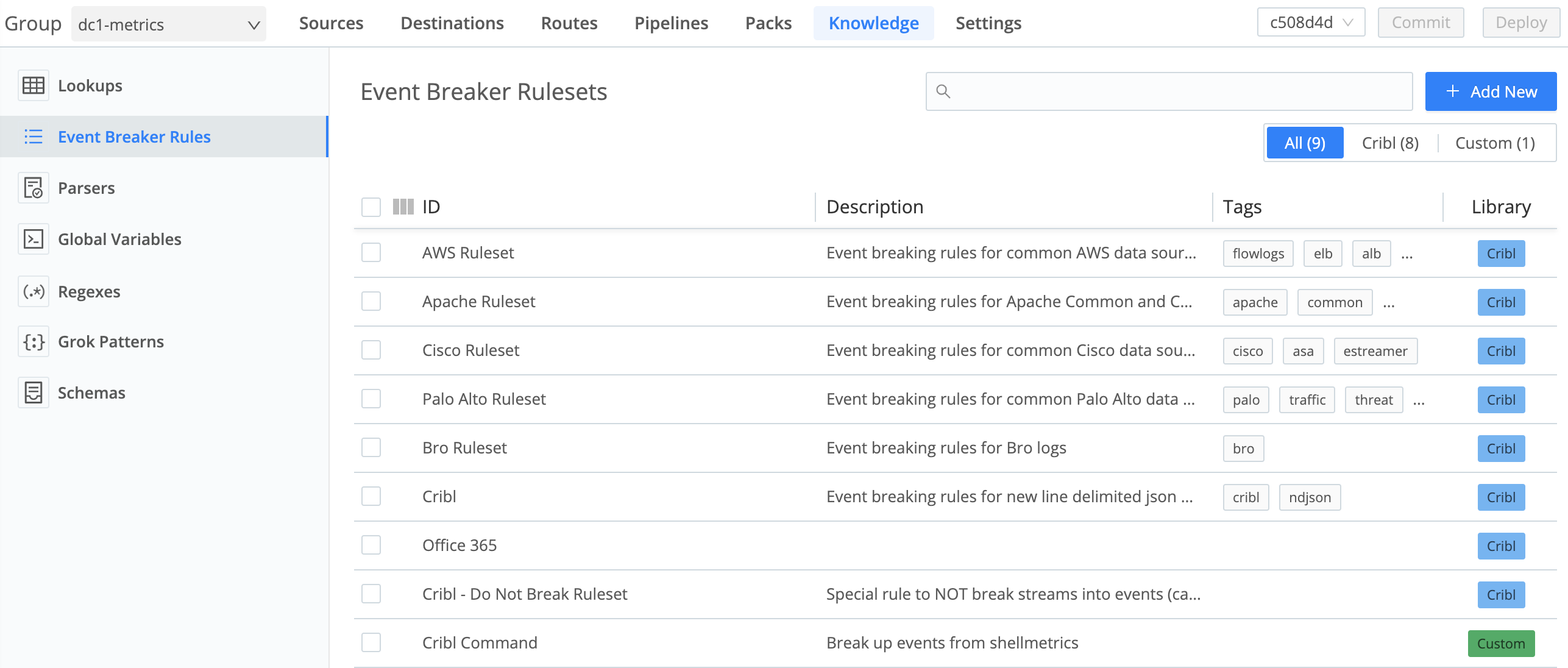
Limitations
Event Breakers are directly accessible only on Sources that require incoming events to be broken into a better-defined format. (Check individual Cribl Stream Sources’ documentation for Event Breaker support.) Also, Event Breakers are currently not supported in Packs.
However, you can instead use the Event Breaker Function in Pipelines that process data from unsupported Sources, and in Pipelines within Packs.
Event Breaker Rulesets
Rulesets are collections of Event Breaker rules that are associated with Sources. Rules define configurations needed to break down a stream of data into events.
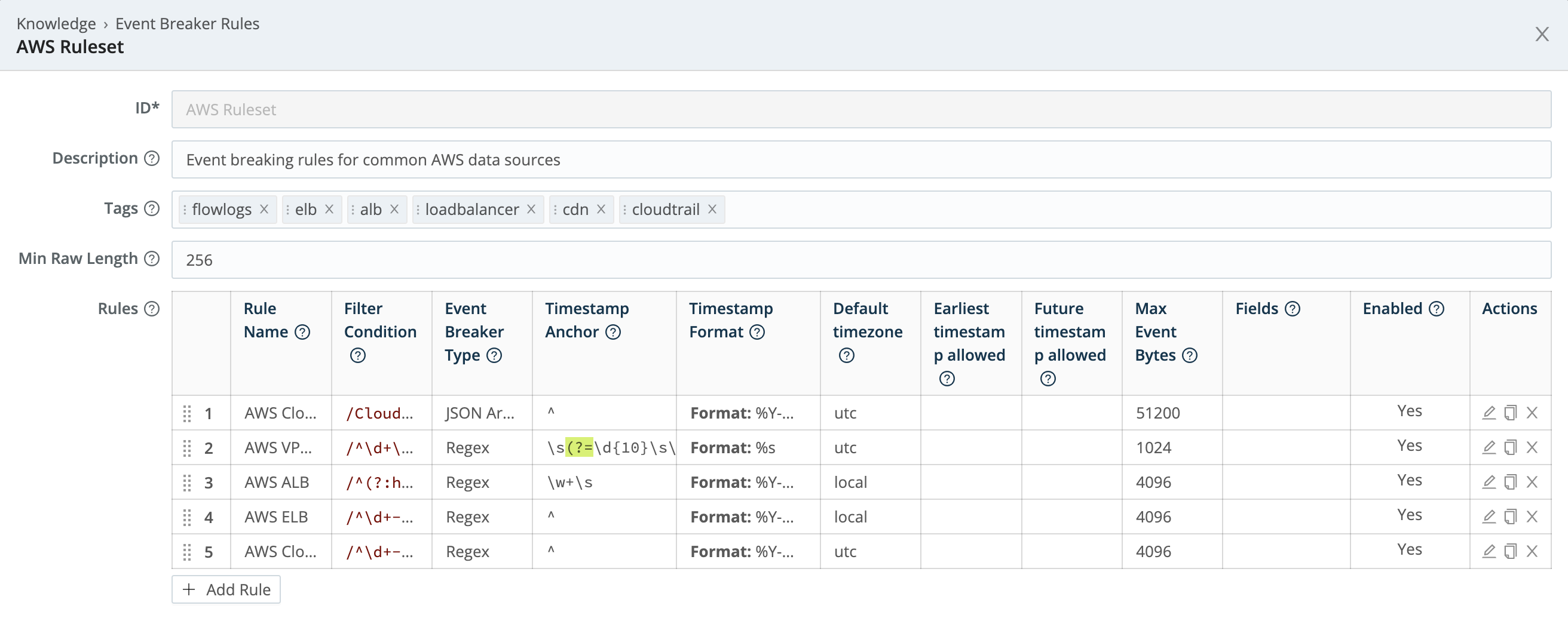
Rules within a ruleset are ordered and evaluated top->down. One or more rulesets can be associated with a Source, and these rulesets are also evaluated top->down. For a stream from a given Source, the first matching rule goes into effect.
Ruleset A
Rule 1
Rule 2
...
Rule n
...
Ruleset B
Rule Foo
Rule Bar
...
Rule FooBarAn example of multiple rulesets associated with a Source:
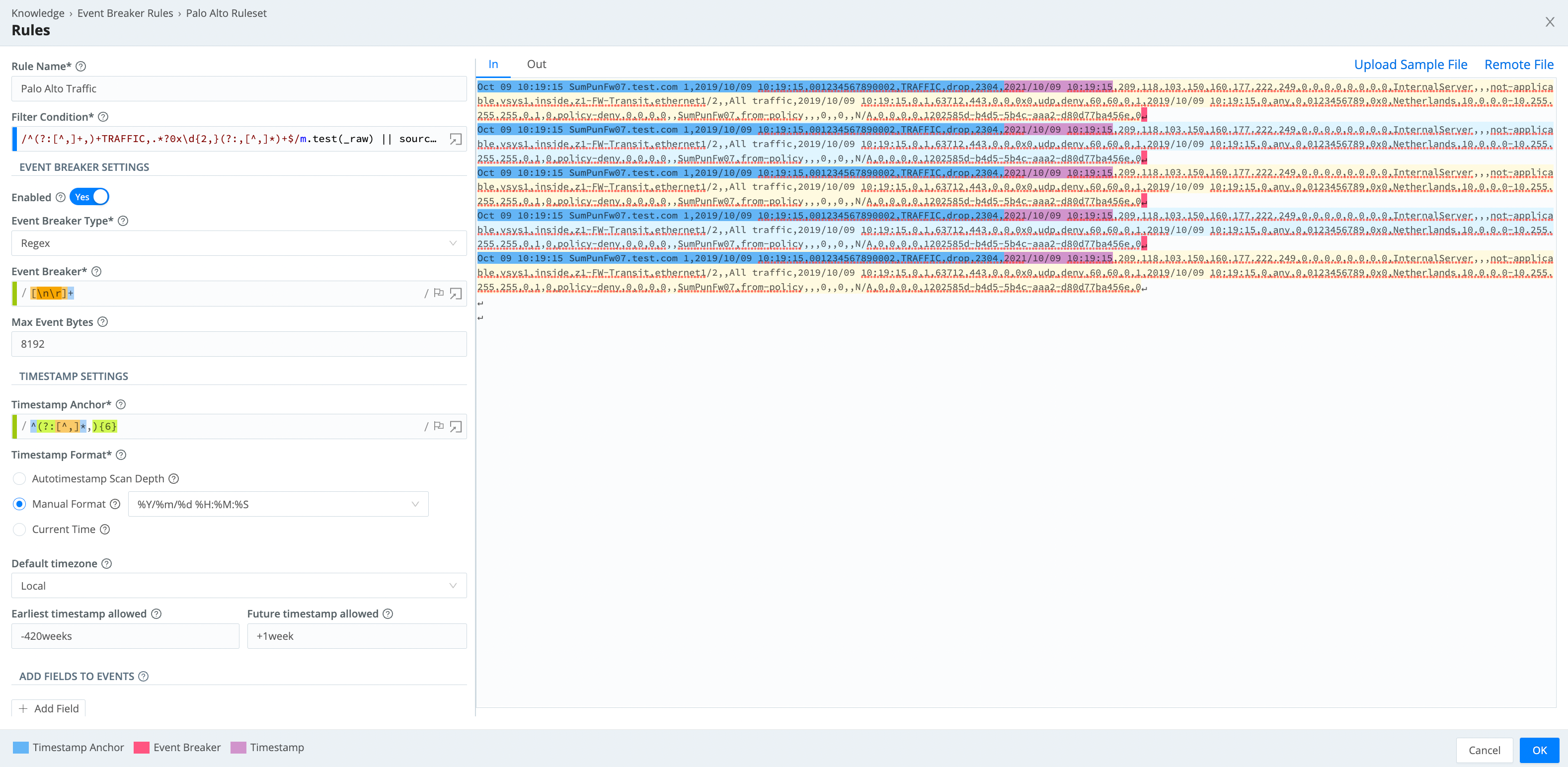
Rule Example
This rule breaks on newlines and uses Manual timestamping after the sixth comma, as indicated by this pattern: ^(?:[^,]*,){6}.
System Default Rule
The system default rule functionally sits at the bottom of the ruleset/rule hierarchy (but is built-in and not displayed on the Event Breakers page), and goes into effect if there are no matching rules:
- Filter Condition defaults to
true - Event Breaker to
[\n\r]+(?!\s) - Timestamp anchor to
^ - Timestamp format to
Autoand a scan depth of150bytes - Max Event Bytes to
51200 - Default Timezone to
Local
How Do Event Breakers Work
On the Event Breaker Rulesets page (see screenshot above), click + Add New to create a new Event Breaker ruleset. Click + Add Rule within a ruleset to add a new Event Breaker.
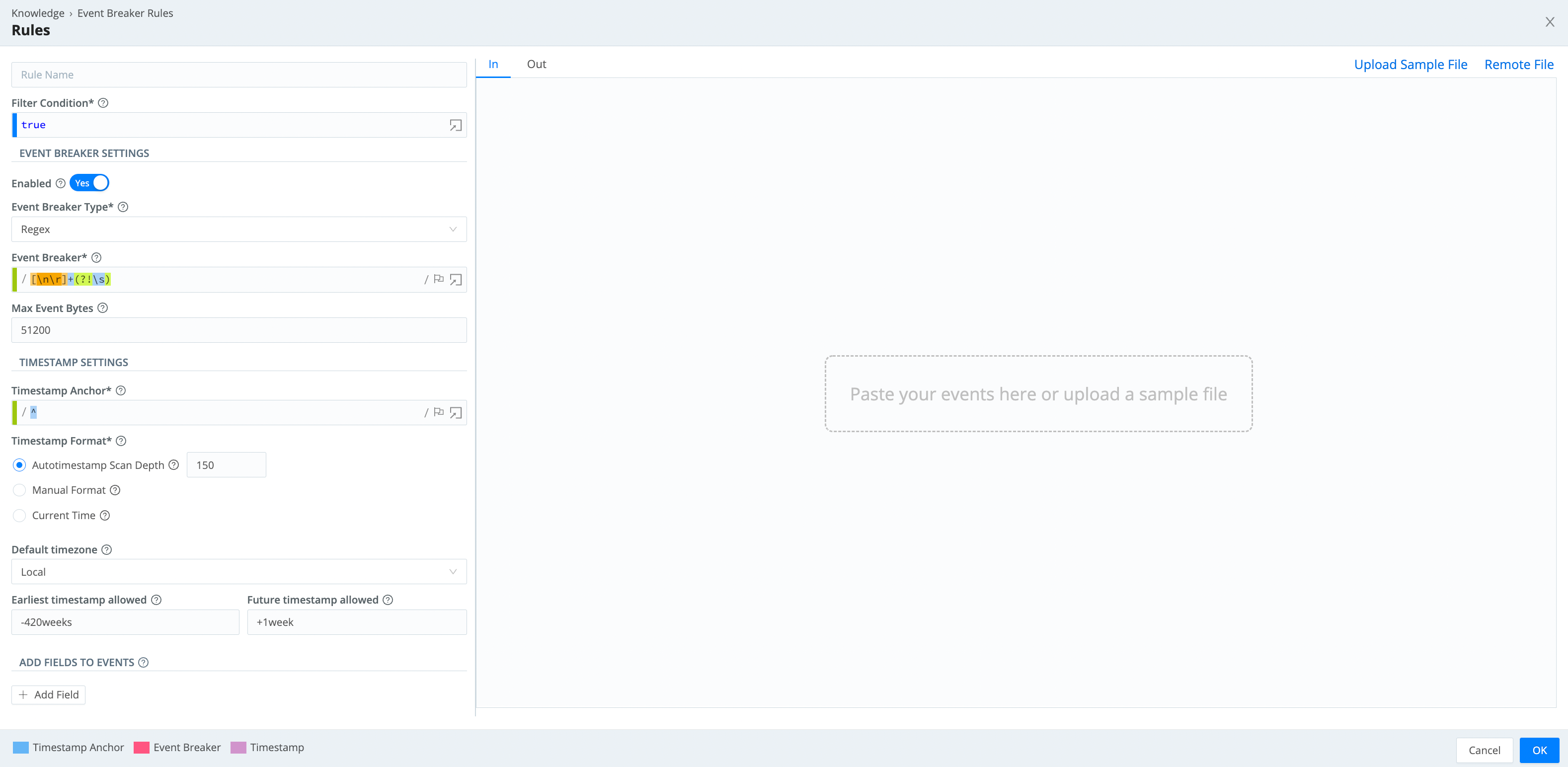
Each Event Breaker includes the following components, which you configure from top to bottom in the above Event Breaker Rule modal:
Filter Condition
When data enters the system, the engine checks it against each filter expression in sequence. If the expression evaluates to true, the rule configurations engage for the entire duration of that stream. Otherwise, the engine evaluates the next rule down the line. Different Source types define a “stream” differently:
- For TCP Sources, a stream equates to a single incoming TCP connection. The stream begins when the socket connection is established and ends when that connection closes.
- For HTTP Sources, a stream equates to a single HTTP request, with connections potentially being reused across different requests instead of corresponding to the entire connection lifecycle.
- For file-based sources like File Monitor or Journal Files, each ingested file is treated as a distinct and complete stream, evaluated independently against filters.
- For Sources that support multiplexed data (like Splunk S2S protocol), Cribl Stream demultiplexes based on channels. Each channel (typically representing a unique source+sourcetype+host combination in Splunk Sources) will have its own event breaker applied consistently throughout its lifecycle.
Event Breaker Type
After a breaker pattern has been selected, it will apply on the stream continuously. See below for specific information on different Event Breaker Types.
Timestamp Settings
After events are synthesized out of streams, Cribl Stream will attempt timestamping. First, a timestamp anchor will be located inside the event. Next, starting there, the engine will try to do one of the following:
- Scan up to a configurable depth into the event and autotimestamp, or
- Timestamp using a manually supplied
strptimeformat, or - Timestamp the event with the current time.
The closer an anchor is to the timestamp pattern, the better the performance and accuracy - especially if multiple timestamps exist within an event. For the manually supplied option, the anchor must lead the engine right before the timestamp pattern begins.

This timestamping executes the same basic algorithm as the Auto Timestamp Function and the C.Time.timestampFinder() native method.
Cribl Stream truncates timestamps to three-digit (milliseconds) resolution, omitting trailing zeros.
In Cribl Stream 3.4.2 and above, where an Event Breaker has set an event’s
_timeto the current time - rather than extracting the value from the event itself - it will mark this by adding the internal field__timestampExtracted: falseto the event.
Add Fields to Events
After events have been timestamped, one or more fields can be added here as key-value pairs. In each field’s Value Expression, you can fully evaluate the field value using JavaScript expressions.
Event Breakers always add the
cribl_breakerfield to output events. Its value is the name of the chosen ruleset. (Some examples below omit thecribl_breakerfield for brevity, but in real life the field is always added.)
Max Event Bytes
If an event’s final broken chunk reaches a matched rule’s Max event bytes length, it will be broken again.
The highest Max Event Bytes value that you can set is about 128 MB (
134217728bytes). Events exceeding that size will be split into separate events, but left unbroken. Cribl Stream will set these events’__isBrokeninternal field tofalse.
Event Breaker Types
Several types of Event Breaker can be applied to incoming data streams:
Regex
The Regex breaker uses regular expressions to find breaking points in data streams.
After a breaker regex pattern has been selected, it will apply on the stream continuously. Breaking will occur at the beginning of the match, and the matched content will be consumed/thrown away. If necessary, you can use a positive lookahead regex to keep the content - e.g.: (?=pattern)
Capturing groups are not allowed to be used anywhere in the Event Breaker pattern, as they will further break the stream - which is often undesirable. Breaking will also occur if the final broken event’s length reaches the rule’s Max event bytes.
Example
Break after a newline or carriage return, but only if followed by a timestamp pattern:
Event Breaker: [\n\r]+(?=\d+-\d+-\d+\s\d+:\d+:\d+)
--- input ---
2020-05-19 16:32:12 moen3628 ipsum[5213]: Use the mobile TCP feed, then you can program the auxiliary card!
Try to connect the FTP sensor, maybe it will connect the digital bus!
Try to navigate the AGP panel, maybe it will quantify the mobile alarm!
2020-05-19 16:32:12 moen3628 ipsum[5213]: Use the mobile TCP feed, then you can program the auxiliary card!
Try to connect the FTP sensor, maybe it will connect the digital bus!
Try to navigate the AGP panel, maybe it will quantify the mobile alarm!
--- output event 1 ---
{
"_raw": "2020-05-19 16:32:12 moen3628 ipsum[5213]: Use the mobile TCP feed, then you can program the auxiliary card! \n Try to connect the FTP sensor, maybe it will connect the digital bus!\n Try to navigate the AGP panel, maybe it will quantify the mobile alarm!",
"_time": 1589920332
}
--- output event 2 ---
{
"_raw": "2020-05-19 16:32:12 moen3628 ipsum[5213]: Use the mobile TCP feed, then you can program the auxiliary card!\n Try to connect the FTP sensor, maybe it will connect the digital bus!\n Try to navigate the AGP panel, maybe it will quantify the mobile alarm!",
"_time": 1589920332
}File Header
You can use the File Header breaker to break files with headers, such as IIS or Bro logs. This type of breaker relies on a header section that lists field names. The header section is typically present at the top of the file, and can be single-line or greater.
After the file has been broken into events, fields will also be extracted, as follows:
- Header Line: Regex matching a file header line. For example,
^#. - Field Delimiter: Field delimiter regex. For example,
\s+. - Field Regex: Regex with one capturing group, capturing all the fields to be broken by field delimiter. For example,
^#[Ff]ields[:]?\s+(.*) - Null Values: Representation of a null value. Null fields are not added to events.
- Clean Fields: Whether to clean up field names by replacing non
[a-zA-Z0-9]characters with_.
Example
Using the values above, let’s see how this sample file breaks up:
--- input ---
#fields ts uid id.orig_h id.orig_p id.resp_h id.resp_p proto
#types time string addr port addr port enum
1331904608.080000 - 192.168.204.59 137 192.168.204.255 137 udp
1331904609.190000 - 192.168.202.83 48516 192.168.207.4 53 udp
--- output event 1 ---
{
"_raw": "1331904608.080000 - 192.168.204.59 137 192.168.204.255 137 udp",
"ts": "1331904608.080000",
"id_orig_h": "192.168.204.59",
"id_orig_p": "137",
"id_resp_h": "192.168.204.255",
"id_resp_p": "137",
"proto": "udp",
"_time": 1331904608.08
}
--- output event 2 ---
{
"_raw": "1331904609.190000 - 192.168.202.83 48516 192.168.207.4 53 udp",
"ts": "1331904609.190000",
"id_orig_h": "192.168.202.83",
"id_orig_p": "48516",
"id_resp_h": "192.168.207.4",
"id_resp_p": "53",
"proto": "udp",
"_time": 1331904609.19
}JSON Array
You can use the JSON Array to extract events from an array in a JSON document (e.g., an Amazon CloudTrail file).
- Array Field: Optional path to array in a JSON event with records to extract. For example,
Records. - Timestamp Field: Optional path to timestamp field in extracted events. For example,
eventTimeorlevel1.level2.eventTime. - JSON Extract Fields: Enable this slider to auto-extract fields from JSON events. If disabled, only
_rawandtimewill be defined on extracted events. - Timestamp Format: If JSON Extract Fields is set to No, you must set this to Autotimestamp or Current Time. If JSON Extract Fields is set to Yes, you can select any option here.
Example
Using the values above, let’s see how this sample file breaks up:
--- input ---
{"Records":[{"eventVersion":"1.05","eventTime":"2020-04-08T01:35:55Z","eventSource":"ec2.amazonaws.com","eventName":"DescribeVolumes", "more_fields":"..."},
{"eventVersion":"1.05","eventTime":"2020-04-08T01:35:56Z","eventSource":"ec2.amazonaws.com","eventName":"DescribeInstanceAttribute", "more_fields":"..."}]}
--- output event 1 ---
{
"_raw": "{\"eventVersion\":\"1.05\",\"eventTime\":\"2020-04-08T01:35:55Z\",\"eventSource\":\"ec2.amazonaws.com\",\"eventName\":\"DescribeVolumes\", \"more_fields\":\"...\"}",
"_time": 1586309755,
"cribl_breaker": "j-array"
}
--- output event 2 ---
{
"_raw": "{\"eventVersion\":\"1.05\",\"eventTime\":\"2020-04-08T01:35:56Z\",\"eventSource\":\"ec2.amazonaws.com\",\"eventName\":\"DescribeInstanceAttribute\", \"more_fields\":\"...\"}",
"_time": 1586309756,
"cribl_breaker": "j-array"
}JSON New Line Delimited
You can use the JSON New Line Delimited breaker to break and extract fields in newline-delimited JSON streams.
Example
Using default values, let’s see how this sample stream breaks up:
--- input ---
{"time":"2020-05-25T18:00:54.201Z","cid":"w1","channel":"clustercomm","level":"info","message":"metric sender","total":720,"dropped":0}
{"time":"2020-05-25T18:00:54.246Z","cid":"w0","channel":"clustercomm","level":"info","message":"metric sender","total":720,"dropped":0}
--- output event 1 ---
{
"_raw": "{\"time\":\"2020-05-25T18:00:54.201Z\",\"cid\":\"w1\",\"channel\":\"clustercomm\",\"level\":\"info\",\"message\":\"metric sender\",\"total\":720,\"dropped\":0}",
"time": "2020-05-25T18:00:54.201Z",
"cid": "w1",
"channel": "clustercomm",
"level": "info",
"message": "metric sender",
"total": 720,
"dropped": 0,
"_time": 1590429654.201,
}
--- output event 2 ---
{
"_raw": "{\"time\":\"2020-05-25T18:00:54.246Z\",\"cid\":\"w0\",\"channel\":\"clustercomm\",\"level\":\"info\",\"message\":\"metric sender\",\"total\":720,\"dropped\":0}",
"time": "2020-05-25T18:00:54.246Z",
"cid": "w0",
"channel": "clustercomm",
"level": "info",
"message": "metric sender",
"total": 720,
"dropped": 0,
"_time": 1590429654.246,
}Timestamp
You can use the Timestamp breaker to break events at the beginning of any line in which Cribl Stream finds a timestamp. This type enables breaking on lines whose timestamp pattern is not known ahead of time.
Example
Using default values, let’s see how this sample stream breaks up:
--- input ---
{"level":"debug","ts":"2021-02-02T10:38:46.365Z","caller":"sdk/sync.go:42","msg":"Handle ENIConfig Add/Update: us-west-2a, [sg-426fdac8e5c22542], subnet-42658cf14a98b42"}
{"level":"debug","ts":"2021-02-02T10:38:56.365Z","caller":"sdk/sync.go:42","msg":"Handle ENIConfig Add/Update: us-west-2a, [sg-426fdac8e5c22542], subnet-42658cf14a98b42"}
--- output event 1 ---
{
"_raw": "{\"level\":\"debug\",\"ts\":\"2021-02-02T10:38:46.365Z\",\"caller\":\"sdk/sync.go:42\",\"msg\":\"Handle ENIConfig Add/Update: us-west-2a, [sg-426fdac8e5c22542], subnet-42658cf14a98b42\"}",
"_time": 1612262326.365
}
--- output event 2 ---
{
"_raw": "{\"level\":\"debug\",\"ts\":\"2021-02-02T10:38:56.365Z\",\"caller\":\"sdk/sync.go:42\",\"msg\":\"Handle ENIConfig Add/Update: us-west-2a, [sg-426fdac8e5c22542], subnet-42658cf14a98b42\"}",
"_time": 1612262336.365
}CSV
The CSV breaker extracts fields in CSV streams that include a header line. Selecting this type exposes these extra fields:
Delimiter: Delimiter character to use to split values. Defaults to:
,Quote Char: Character used to quote literal values. Defaults to:
"Escape Char: Character used to escape the quote character in field values. Defaults to:
"Example: Using default values, let’s see how this sample stream breaks up:
Example
Using default values, let’s see how this sample stream breaks up:
--- input ---
time,host,source,model,serial,bytes_in,bytes_out,cpu
1611768713,"myHost1","anet","cisco","ASN4204269",11430,43322,0.78
1611768714,"myHost2","anet","cisco","ASN420423",345062,143433,0.28
--- output event 1 ---
{
"_raw": "\"1611768713\",\"myHost1\",\"anet\",\"cisco\",\"ASN4204269\",\"11430\",\"43322\",\"0.78\"",
"time": "1611768713",
"host": "myHost1",
"source": "anet",
"model": "cisco",
"serial": "ASN4204269",
"bytes_in": "11430",
"bytes_out": "43322",
"cpu": "0.78",
"_time": 1611768713
}
--- output event 2 ---
{
"_raw": "\"1611768714\",\"myHost2\",\"anet\",\"cisco\",\"ASN420423\",\"345062\",\"143433\",\"0.28\"",
"time": "1611768714",
"host": "myHost2",
"source": "anet",
"model": "cisco",
"serial": "ASN420423",
"bytes_in": "345062",
"bytes_out": "143433",
"cpu": "0.28",
"_time": 1611768714
}With Type: CSV selected, an Event Breaker will properly add quotes around all values, regardless of their initial state.
Cribl versus Custom Rulesets
Event Breaker rulesets shipped by Cribl will be listed under the Cribl tag, while user-built rulesets will be listed under Custom. Over time, Cribl will ship more patterns, so this distinction allows for both sets to grow independently. In the case of an ID/Name conflict, the Custom pattern takes priority in listings and search.
Exporting and Importing Rulesets
You can export and import Custom (or Cribl) rulesets as JSON files. This facilitates sharing rulesets among Worker Groups or Cribl Stream deployments.
To export a ruleset:
Click to open an existing ruleset, or create a new ruleset.
In the resulting modal, click Advanced Mode to open the JSON editor.
You can now modify the ruleset directly in JSON, if you choose.
Click Export, select a destination path, and name the file.
To import any ruleset that has been exported as a valid JSON file:
Create a new ruleset.
In the resulting modal, click Advanced Mode to open the JSON editor.
Click Import, and choose the file you want.
Click OK to get back to the New Ruleset modal.
Click Save.
Every ruleset must have a unique value in its top
idkey. Importing a JSON file with a duplicateidvalue will fail at the final Save step, with a message that the ruleset already exists. You can remedy this by giving the file a uniqueidvalue.
Troubleshooting
If you notice fragmented events, check whether Cribl Stream has added a __timeoutFlush internal field to them. This diagnostic field’s presence indicates that the events were flushed because the Event Breaker buffer timed out while processing them. These timeouts can be due to large incoming events, backpressure, or other causes.
Specifying Minimum _raw Length
If you notice that the same Collector or Source is applying inconsistent Event Breakers to different datasets - e.g., intermittently falling back to the System Default Rule - you can address this by adjusting Breakers’ Min Raw Length setting.
When determining which Event Breaker to use, Cribl Stream creates a substring from the incoming _raw field, at the length set by rules’ Max Event Bytes parameters. If Cribl Stream does not get a match, it checks whether the substring of _raw has at least the threshold number of characters set by Min Raw Length. If so, Cribl Stream does not wait for more data.
You can tune this Min Raw Length threshold to account for varying numbers of inapplicable characters at the beginning of events. The default is 256 characters, but you can set this as low as 50, or as high as 100000 (100 KB).