



These docs are for Cribl Stream 4.10 and are no longer actively maintained.
See the latest version (4.17).
MinIO Destination
MinIO is a non-streaming Destination type, to which Cribl Stream can output objects.
Type: Non-Streaming | TLS Support: Configurable | PQ Support: No
Configure Cribl Stream to Output to MinIO Destinations
- On the top bar, select Products, and then select Cribl Stream. Under Worker Groups, select a Worker Group. Next, you have two options:
- To configure via QuickConnect, navigate to Routing > QuickConnect (Stream) or Collect (Edge). Select Add Destination and select the Destination you want from the list, choosing either Select Existing or Add New.
- To configure via the Routes, select Data > Destinations or More > Destinations (Edge). Select the Destination you want. Next, select Add Destination.
- In the New Destination modal, configure the following under General Settings:
Output ID: Enter a unique name to identify this MinIO definition. If you clone this Destination, Cribl Stream will add
-CLONEto the original Output ID.Description: Optionally, enter a description.
MinIO endpoint: MinIO service URL (for example, http://minioHost:9000).
MinIO bucket name:Name of the destination MinIO bucket. This value can be a constant, or a JavaScript expression that will be evaluated only at init time. For example, referencing a Global Variable:
myBucket-${C.vars.myVar}. Ensure that the bucket already exists, otherwise MinIO will generate “bucket does not exist” errors.Event-level variables are not available for JavaScript expressions. This is because the bucket name is evaluated only at Destination initialization. If you want to use event-level variables in file paths, Cribl recommends specifying them in the Partitioning Expression field (described below), because this is evaluated for each file.
Staging location: Filesystem location in which to locally buffer files before compressing and moving to final destination. Cribl recommends that this location be stable and high-performance.
The Staging location field is not displayed or available on Cribl.Cloud-managed Worker Nodes.
Data format: The output data format defaults to
JSON.RawandParquetare also available. SelectingParquet(supported only on Linux, not Windows) exposes a Parquet Settings left tab, where you must configure certain options in order to export data in Parquet format.
- Next, you can configure the following Optional Settings:
Key prefix: Root directory to prepend to path before uploading. Enter a constant, or a JS expression enclosed in single quotes, double quotes, or backticks. Prefix to apply to files/objects before uploading to the specified bucket. MinIO will display key prefixes as folders.
Partitioning expression: JavaScript expression that defines how files are partitioned and organized. Default is date-based. If blank, Cribl Stream will fall back to the event’s
__partitionfield value (if present); or otherwise to the root directory of the Output Location and Staging Location.Cribl Stream’s internal
__partitionfield can be populated in multiple ways. The precedence order is: explicit Partitioning expression value ->${host}/${sourcetype}(default) Partitioning expression value -> user-definedevent.__partition, set with an Eval Function (takes effect only where this Partitioning expression field is blank).Compress: Data compression format used before moving to final destination. Defaults to
gzip(recommended). This setting is not available when Data format is set toParquet.File name prefix expression: The output filename prefix. Must be a JavaScript expression (which can evaluate to a constant), enclosed in quotes or backticks. Defaults to
CriblOut.File name suffix expression: The output filename suffix. Must be a JavaScript expression (which can evaluate to a constant), enclosed in quotes or backticks. Defaults to
`.${C.env["CRIBL_WORKER_ID"]}.${__format}${__compression === "gzip" ? ".gz" : ""}`, where__formatcan bejsonorraw, and__compressioncan benoneorgzip.Backpressure behavior: Select whether to block or drop events when all receivers are exerting backpressure. (Causes might include an accumulation of too many files needing to be closed.) Defaults to
Block.Tags: Optionally, add tags that you can use to filter and group Destinations on the Destinations page. These tags aren’t added to processed events. Use a tab or hard return between (arbitrary) tag names.
- Optionally, you can adjust the Authentication, Processing, Parquet, and Advanced settings outlined in the sections below.
- Select Save, then Commit & Deploy.
How MinIO Composes File Names
The full path to a file consists of:
<bucket_name>/<keyprefix><partition_expression | __partition><file_name_prefix><filename>.<extension>
As an example, assume that the MinIO bucket name is bucket1, the Key prefix is aws, the Partitioning expression is `${host}/${sourcetype}`, the source is undefined, the File name prefix is the default CriblOut, and the Data format is json. Here, the full path as displayed in MinIO would have this form: /bucket1/aws/192.168.1.241/undefined/CriblOut-<randomstring>0.json
Although MinIO will display the Key prefix and Partitioning expression values as folders, both are actually just part of the overall key name, along with the file name.
Authentication
Use the Authentication Method drop-down to select one of these options:
Auto: This default option uses the AWS SDK for JavaScript to automatically obtain credentials in the following order of attempts:
- IAM Roles for Amazon EC2: Loaded from AWS Identity and Access Management (IAM) roles attached to an EC2 instance.
- Shared Credentials File: Loaded from the shared credentials file (
~/.aws/credentials). - Environment Variables: Loaded from environment variables
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEY. - JSON File on Disk: Loaded from a JSON file on disk.
- Other Credential-Provider Classes: Other credential-provider classes provided by the AWS SDK for JavaScript.
The Auto method works both when running on AWS and in other environments where the necessary credentials are available through one of the above methods.
SSO Providers
When using the auto authentication method, you can leverage SSO providers like SAML and Okta to issue temporary credentials. These credentials should be set in the environment variables
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEY. The AWS SDK will then use these environment variables to authenticate.
Manual: If not running on AWS, you can select this option to enter a static set of user-associated IAM credentials (your access key and secret key) directly or by reference. This is useful for Workers not in an AWS VPC, for example, those running a private cloud. The Manual option exposes these corresponding additional fields:
Access key: Enter your AWS access key. If not present, will fall back to the
env.AWS_ACCESS_KEY_IDenvironment variable, or to the metadata endpoint for IAM role credentials.Secret key: Enter your AWS secret key. If not present, will fall back to the
env.AWS_SECRET_ACCESS_KEYenvironment variable, or to the metadata endpoint for IAM credentials.
The values for Access key and Secret key can be a constant, or a JavaScript expression (such as ${C.env.MY_VAR}) enclosed in quotes or backticks, which allows configuration with environment variables.
Secret: If not running on AWS, you can select this option to supply a stored secret that references an AWS access key and secret key. This option exposes a Secret key pair drop-down, in which you can select a stored secret that references the set of user-associated IAM credentials described above. A Create link is available to store a new, reusable secret.
Processing Settings
Post-Processing
Pipeline: Pipeline or Pack to process data before sending the data out using this output.
System fields: A list of fields to automatically add to events that use this output. By default, includes cribl_pipe (identifying the Cribl Stream Pipeline that processed the event). Supports wildcards. Other options include:
cribl_host- Cribl Stream Node that processed the event.cribl_input- Cribl Stream Source that processed the event.cribl_output- Cribl Stream Destination that processed the event.cribl_route- Cribl Stream Route (or QuickConnect) that processed the event.cribl_wp- Cribl Stream Worker Process that processed the event.
Parquet Settings
To write out Parquet files, note that:
- On Linux, you can use the Cribl Stream CLI’s
parquetcommand to view a Parquet file, its metadata, or its schema. - Cribl Edge Workers support Parquet only when running on Linux, not on Windows.
- See Working with Parquet for pointers on how to avoid problems such as data mismatches.
Automatic schema: Toggle on to automatically generate a Parquet schema based on the events of each Parquet file that Cribl Stream writes. When toggled off (the default), exposes the following additional field:
- Parquet schema: Select a schema from the drop-down.
If you need to modify a schema or add a new one, follow the instructions in our Parquet Schemas topic. These steps will propagate the freshest schema back to this drop-down.
Parquet version: Determines which data types are supported, and how they are represented. Defaults to 2.6; 2.4 and 1.0 are also available.
Data page version: Serialization format for data pages. Defaults to V2. If your toolchain includes a Parquet reader that does not support V2, use V1.
Group row limit: The number of rows that every group will contain. The final group can contain a smaller number of rows. Defaults to 10000.
Page size: Set the target memory size for page segments. Generally, set lower values to improve reading speed, or set higher values to improve compression. Value must be a positive integer smaller than the Row group size value, with appropriate units. Defaults to 1 MB.
Log invalid rows: Toggle on to output up to 20 unique rows that were skipped due to data format mismatch. Log level must be set to debug for output to be visible.
Write statistics: Leave toggled on (the default) if you have Parquet tools configured to view statistics - these profile an entire file in terms of minimum/maximum values within data, numbers of nulls, etc.
Write page indexes: Leave toggled on (the default) if your Parquet reader uses statistics from Page Indexes to enable page skipping. One Page Index contains statistics for one data page.
Write page checksum: Toggle on if you have configured Parquet tools to verify data integrity using the checksums of Parquet pages.
Metadata (optional): The metadata of files the Destination writes will include the properties you add here as key-value pairs. For example, one way to tag events as belonging to the OCSF category for security findings would be to set Key to OCSF Event Class and Value to 2001.
Advanced Settings
Max file size (MB): Maximum uncompressed output file size. Files of this size will be closed and moved to final output location. Defaults to 32.
Max file open time (sec): Maximum amount of time to write to a file. Files open for longer than this limit will be closed and moved to final output location. Defaults to 300.
Max file idle time (sec): Maximum amount of time to keep inactive files open. Files open for longer than this limit will be closed and moved to final output location. Defaults to 30.
Max open files: Maximum number of files to keep open concurrently. When exceeded, the oldest open files will be closed and moved to final output location. Defaults to 100.
Cribl Stream will close files when either of the
Max file size (MB)or theMax file open time (sec)conditions is met.
Max concurrent file parts: Maximum number of parts to upload in parallel per file. A value of 1 tells the Destination to send the whole file at once. When set to 2 or above, IAM permissions must include those required for multipart uploads. Defaults to 4; highest allowed value is 10.
Disk space protection: Specifies whether to Block (default) or Drop incoming events when the disk space falls below the globally defined Min free disk space amount.
Add Output ID: When toggled on (default), adds the Output ID field’s value to the staging location’s file path. This ensures that each Destination’s logs will write to its own bucket.
For a Destination originally configured in a Cribl Stream version below 2.4.0, the Add Output ID behavior will be switched off on the backend, regardless of this toggle’s state. This is to avoid losing any files pending in the original staging directory, upon Cribl Stream upgrade and restart. To enable this option for such Destinations, Cribl’s recommended migration path is:
- Clone the Destination.
- Redirect the Routes referencing the original Destination to instead reference the new, cloned Destination.
This way, the original Destination will process pending files (after an idle timeout), and the new, cloned Destination will process newly arriving events with Add output ID enabled.
Remove staging dirs: Toggle this on to delete empty staging directories after moving files. This prevents the proliferation of orphaned empty directories. When enabled, exposes this additional option:
- Staging cleanup period: How often (in seconds) to delete empty directories when Remove staging dirs is enabled. Defaults to
300seconds (every 5 minutes). Minimum configurable interval is10seconds; maximum is86400seconds (every 24 hours).
Enable dead-lettering: Toggle this on to set a maximum number of retries, and to move files to a designated directory when write failures exceed that limit. This prevents data flow blockage and excessive error logging due to undeliverable files. When enabled, exposes two additional fields:
- Dead-letter location: Specify the storage location for undeliverable files. Defaults to
$CRIBL_HOME/state/outputs/dead-letter. - Maximum retry limit: Configure the retry limit for failed file deliveries. This setting defines how many times the system will attempt to move a file to its intended location before it is deemed undeliverable and placed in the dead-letter directory. Defaults to
20.
Region: Region where the MinIO service/cluster is located. Leave blank when using a containerized MinIO.
Object ACL: ACL (Access Control List) to assign to uploaded objects. Defaults to Private.
Storage class: Select a storage class for uploaded objects. Defaults to Standard.
Server-side encryption: Server side encryption type for uploaded objects. Defaults to none.
Signature version: Signature version to use for signing MinIO requests. Defaults to v4.
Reuse connections: Whether to reuse connections between requests. Toggling on (default) can improve performance.
Reject unauthorized certificates: Whether to accept certificates that cannot be verified against a valid Certificate Authority (for example, self-signed certificates). Defaults to toggled on.
Environment: If you’re using GitOps, optionally use this field to specify a single Git branch on which to enable this configuration. If empty, the config will be enabled everywhere.
IAM Permissions
The following permissions are always needed to write to an Amazon S3-compatible object store:
s3:ListBuckets3:GetBucketLocations3:PutObject
If your Destination needs to do multipart uploads to S3, two more permissions are needed:
kms:GenerateDataKeykms:Decrypt
See the AWS documentation.
Internal Fields
Cribl Stream uses a set of internal fields to assist in forwarding data to a Destination.
Field for this Destination:
__partition
Troubleshooting
The Destination’s configuration modal has helpful tabs for troubleshooting:
Live Data: Try capturing live data to see real-time events as they flow through the Destination. On the Live Data tab, click Start Capture to begin viewing real-time data.
Logs: Review and search the logs that provide detailed information about the delivery process, including any errors or warnings that may have occurred.
Test: Ensures that the Destination is correctly set up and reachable. Verify that sample events are sent correctly by clicking Run Test.
You can also view the Monitoring page that provides a comprehensive overview of data volume and rate, helping you identify delivery issues. Analyze the graphs showing events and bytes in/out over time.
Common Issues
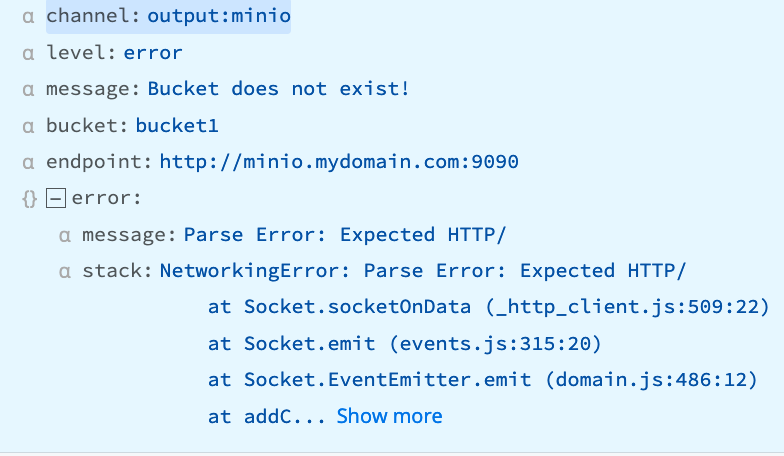
“Parse Error: Expected HTTP/”
The Worker is trying to use HTTP, but the server is expecting HTTPS.
“Bucket does not exist - self signed certificate”
Example Error Text:
message: Bucket does not exist - self signed certificate
stack: Error: self signed certificate
at TLSSocket.onConnectSecure (node:_tls_wrap_1535:34)
at TLSSocket.emit (node:events:513:28)
at TLSSocket.emit (node:events:489:12)
at TLSSocket._fini... Show more
tmpPath: /opt/cribl/s3_bucket/cribl/2023/03/28/CriblOut-XTNGh5.0.json.tmpCan occur when:
- the Destination uses a self-signed cert that has not yet been trusted by Cribl Stream.
- the user does not have appropriate permissions to view the bucket.
- the authentication token generated by your computer has a timestamp that is out of sync with the server’s time, resulting in an authentication failure.
Recommendation
Disable Advanced Settings > Reject unauthorized certificates or; get the sender’s cert and add it to the NODE_EXTRA_CA_CERTS path for validation; or verify that the user has appropriate permissions.