



These docs are for Cribl Stream 4.12 and are no longer actively maintained.
See the latest version (4.17).
S3 Collector
Cribl Stream supports collecting data from Amazon S3 stores, including optimized support for Splunk Dynamic Data Self Storage (DDSS) datasets. This page covers how to configure the Collector.
For a step-by-step tutorial on using Cribl Stream to replay data from an S3-compatible store, see our Data Collection & Replay sandbox. The sandbox takes about 30 minutes. It provides a hosted environment, with all inputs and outputs preconfigured for you.
Also see our Amazon S3 Better Practices and Using S3 Storage and Replay guides.
How the Collector Pulls Data
When you run an S3 Collector in Discovery mode, the first available Worker returns the list of available files to the Leader Node.
In Full Run mode, the Leader distributes the list of files to process across 1..N Workers, as evenly as possible, based on file size. Each Worker then streams the files from the S3 bucket/path to itself.
Compression
Cribl Stream can ingest compressed S3 files if they meet all the following conditions:
- Compressed with the
x-gzipMIME type. - End with the
.gzextension. - Can be uncompressed using the
zlib.gunzipalgorithm.
The job’s Total size displayed in the Job Inspector reflects the compressed file size reported by S3. Use this to optimize your path expression for more efficient data access.
Storage Class Compatibility
Cribl Stream does not support data preview, collection, or replay from S3 Glacier or S3 Deep Glacier storage classes, whose stated retrieval lags (variously minutes to 48 hours) cannot guarantee data availability when the Collector needs it.
Cribl Stream does support data preview, collection, and replay from S3 Glacier Instant Retrieval when you’re using the S3 Intelligent-Tiering storage class.
Configure an S3 Collector
Navigate to Products > Stream > Worker Groups. Select a Worker Group, then go to Data > Sources. Choose the Source and select Add Collector.
In the New Collector modal, configure the following under Collector Settings:
- Collector ID: Unique ID for this Collector. For example,
Attic42TreasureChest. If you clone this Collector, Cribl Stream will add-CLONEto the original Collector ID. - Description: Optionally, enter a description.
- Auto-populate from: Select a Destination with which to auto-populate Collector settings. Useful when replaying data.
- S3 bucket: Simple Storage Service bucket from which to collect data.
- Collector ID: Unique ID for this Collector. For example,
Under Authentication, select an Authentication method from the dropdown: Auto or Manual. For details, see Authentication Methods
Under the Assume Role accordian, configure the following.
Enable Assume Role: Toggle on to enable Assume Role behavior.
AssumeRole ARN: Amazon Resource Name (ARN) of the role to assume.
External ID: External ID to use when assuming role. Enter this if defined in your IAM policy’s trust relationship; otherwise, leave blank. (Usage example: AWS Cross-Account Data Collection.)
Duration (seconds): Duration of the Assumed Role’s session, in seconds. Minimum is 900 (15 minutes). Maximum is 43200 (12 hours). Defaults to 3600 (1 hour).
When using Assume Role to access resources in a different Region than Cribl Stream, you can target the AWS Security Token Service (STS) endpoint specific to that Region by using the
CRIBL_AWS_STS_REGIONenvironment variable on your Worker Node. Setting an invalid Region results in a fallback to the global STS endpoint.
Next, you can configure the following Optional Settings:
- Region: S3 Region from which to retrieve data.
You must grant your IAM role or user the
GetBucketLocationpermission to the S3 bucket when no Region is selected. See Amazon S3 Permissions for an example. - Path: Path, within the bucket, from which to collect data. See About Paths for details.
- Partitioning scheme: How data is organized within an S3 bucket. This is important for optimizing data retrieval and storage efficiency, especially when integrating with Cribl Search. Your options are:
- Defined in Path: Use the Path structure you specify.
- DDSS: Optimize for datasets extracted using Splunk Dynamic Data Self Storage (DDSS) tool. Cribl Stream assumes you’ve configured a DDSS root path in your Splunk environment. This root path typically points to the root directory of your self-storage bucket in S3.
- Path extractors: Extractors enable you to use template tokens as context for expressions that enrich discovery results. For usage details and examples, see Using Path Extractors.
- Endpoint: S3 service endpoint. If empty, Cribl Stream will automatically construct the endpoint from the AWS Region. To access the AWS S3 endpoints, use the path-style URL format. You don’t need to specify the bucket name in the URL, because Cribl Stream will automatically add it to the URL path. For details, see AWS’ Path-Style Requests topic.
- Signature version: Signature version to use for signing S3 requests. Defaults to
v4. - Max batch size (objects): Maximum number of metadata objects to batch before recording as results.
- Recursive: If toggled on (default), data collection will recurse through subdirectories. This option is available only when Partitioning scheme is set to
Defined in Path. - Reuse connections: Whether to reuse connections between requests. Toggling on (default) can improve performance.
- Reject unauthorized certificates: Whether to accept certificates that cannot be verified against a valid Certificate Authority, such as self-signed certificates. Defaults to toggled on.
- Verify bucket permissions: Toggle off if you can access files within the bucket, but not the bucket itself. This resolves errors of the form:
discover task initialization failed...error: Forbidden. - Disable time filter: Toggle on to bypass the collection job event timestamp filtering. By default, Collectors apply time filtering based on the configured time range. Events with timestamps outside this range are discarded. Enabling this setting disables timestamp-based filtering, allowing all returned events to be processed regardless of their timestamps. This is useful when the data source’s timestamps do not align with the configured time range, causing unexpected filtering, or when you need to process all data regardless of their timestamps. If you encounter zero results despite the data source returning events, disabling the time filter can help isolate whether timestamp filtering is the issue. For details, see No Discover or Collector Event Results.
- Encoding: Character encoding to use when parsing ingested data. If not set, Cribl Stream will default to UTF-8 but might incorrectly interpret multi-byte characters. This option is ignored for Parquet files. UTF-16LE and Latin-1 are also supported
- Tags: Optionally, add tags that you can use to filter and group Sources in Cribl Stream’s Manage Sources page. These tags aren’t added to processed events. Use a tab or hard return between (arbitrary) tag names.
- Region: S3 Region from which to retrieve data.
Optionally, configure any Result, Result Routing, and Advanced settings outlined in the sections below.
Select Save, then Commit & Deploy.
To verify that the Collector actually collects data, you can start a single run in the Preview mode.
The sections described below are spread across several tabs. Click the tab links at left to navigate among tabs.
Collector Sources currently cannot be selected or enabled in the QuickConnect UI.
About Paths
Templates and tokens are supported to provide flexibility and automation in defining the directory structure, allowing you to organize data efficiently based on various parameters. This value can be a constant or a JavaScript expression. More on templates and tokens here. If this S3 Collector will be used to round-trip data through our Destination and replay it in Cribl Stream, we have a recommended Path. See the Replay Collector for details.
- Templating allows for dynamic insertion of variables like host, year, and month. For example,
/myDir/${host}/${year}/${month}/). - Time-based tokens enable time-specific data organization. For example,
myOtherDir/${_time:%Y}/${_time:%m}/${_time:%d}/.
Result Settings
The Result Settings determine how Cribl Stream transforms and routes the collected data.
Custom Command
In this section, you can pass the data from this input to an external command for processing, before the data continues downstream.
- Enabled: Defaults to toggled off. Toggle on to enable the custom command.
- Command: Enter the command that will consume the data (via
stdin) and will process its output (viastdout). - Arguments: Click Add Argument to add each argument to the command. You can drag arguments vertically to resequence them.
Event Breakers
In this section, you can apply event breaking rules to convert data streams to discrete events.
- Event Breaker rulesets: A list of event breaking rulesets that will be applied, in order, to the input data stream. Defaults to
System Default Rule. - Event Breaker buffer timeout: How long (in milliseconds) the Event Breaker will wait for new data to be sent to a specific channel, before flushing out the data stream, as-is, to the Routes. Minimum
10ms, default10000(10 sec), maximum43200000(12 hours).
Fields
In this section, you can define new fields or modify existing ones using JavaScript expressions, similar to the Eval function.
- The Field Name can either be a new field (unique within the event) or an existing field name to modify its value.
- The Value is a JavaScript expression (enclosed in quotes or backticks) to compute the field’s value (can be a constant). Select this field’s advanced mode icon (far right) if you’d like to open a modal where you can work with sample data and iterate on results.
This flexibility means you can:
- Add new fields to enrich the event.
- Modify existing fields by overwriting their values.
- Compute logic or transformations using JavaScript expressions.
Result Routing
Send to Routes: Toggle on (default) if you want Cribl Stream to send events to normal routing and event processing. Toggle off to select a specific Pipeline/Destination combination. Toggling off exposes these two additional fields:
- Pipeline: Select a Pipeline to process results.
- Destination: Select a Destination to receive results.
Toggling on (default) exposes this field:
- Pre-processing Pipeline: Pipeline to process results before sending to Routes. Optional.
This field is always exposed:
- Throttling: Rate (in bytes per second) to throttle while writing to an output. Also takes values with multiple-byte units, such as
KB,MB,GB, etc. (Example:42 MB.) Default value of0indicates no throttling.
You might toggle Send to Routes off when configuring a Collector that will connect data from a specific Source to a specific Pipeline and Destination. This keeps the Collector’s configuration self-contained and separate from Cribl Stream’s routing table for live data - potentially simplifying the Routes structure.
Advanced Settings
Advanced Settings enable you to customize post-processing and administrative options.
- Environment: If you’re using GitOps, optionally use this field to specify a single Git branch on which to enable this configuration. If empty, the config will be enabled everywhere.
- Time to live: How long to keep the job’s artifacts on disk after job completion. This also affects how long a job is listed in Job Inspector. Defaults to
4h. - Remove Discover fields : List of fields to remove from the Discover results. This is useful when discovery returns sensitive fields that should not be exposed in the Jobs user interface. You can specify wildcards (such as
aws*). - Resume job on boot: Toggle on to resume ad hoc collection jobs if Cribl Stream restarts during the jobs’ execution.
Authentication Methods
The Authentication method dropdown give you a choice of two options.
The Auto option (default) will use environment variables AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY, or the attached IAM role. Will work only when running on AWS.
The Manual option exposes these fields:
- Access key: Enter your AWS access key. If not present, will fall back to the
env.AWS_ACCESS_KEY_IDenvironment variable, or to the metadata endpoint for IAM role credentials. This value can be a constant or a JavaScript expression. - Secret key: Enter your AWS secret key. if not present, will fall back to the
env.AWS_SECRET_ACCESS_KEYenvironment variable, or to the metadata endpoint for IAM credentials. Optional when running on AWS. This value can be a constant or a JavaScript expression.
The Secret option swaps in this drop-down:
- Secret key pair: Select a secret key pair that you’ve configured in Cribl Stream’s internal secrets manager or (if enabled) an external KMS. Follow the Create link if you need to configure a key pair.
The Manual option’s Access key and Secret key values override the Auto option. For any Workers that you want to associate with an AWS IAM role, using the Assume Role controls below ensure that the Manual option’s key fields are empty.
Using Path Extractors
Click Add Extractor to add each extractor as a key-value pair, mapping a Token name on the left (a substring of the Path) to a custom JavaScript Extractor expression on the right. Example {host: value.toLowerCase()}
Each expression accesses its corresponding token through its value variable, and evaluates the token to populate event fields.
You can define each token in only one Extractor expression per S3 Collector config.
Example #1
Here is a simple, complete example, using a single expression:
| Token | Extractor Expression | Matched Value | Extracted Result |
|---|---|---|---|
/var/log/${foobar} | {program: value.split('.')[0]} | /var/log/syslog.1 | {program: syslog, foobar: syslog.1} |
Example #2
Here is a multi-expression example. Assuming that your S3 bucket path supports the Collector’s configured Path, this shows how to extract each segment of this example Path, and transform it into a reformatted field:
First, the path:
/${index}/${_time:%Y}/${_time:%m}/${_time:%d}/${host}/${category}/${_time:%H}/${file}
Next, the tokens and extractor expressions:
| Token | Extractor Expression | Purpose |
|---|---|---|
index | {"indexUppercase" : value.toUpperCase()} | Uppercase the index |
host | {"hostUpperPrefix" : value.toUpperCase().replace(/(.+?)\..+/,'$1'), "domain" : value.match(/.+?\.(.+)/)[1]} | Use one token for two fields: hostUpperPrefix and domain |
category | {"categoryUpperFirstLetter" : `${value.substring(0,1).toUpperCase()}${value.substring(1)}`} | Uppercase the category string’s first letter |
file | {"fileCleanName" : value.replace(/ARCHIVE-/i,'').toUpperCase().split('.')[0], "CRIBL_WORKER_ID" : value.split('.')[1], "compression" : value.split('.')[2]} | Split the object (file name) into three fields |
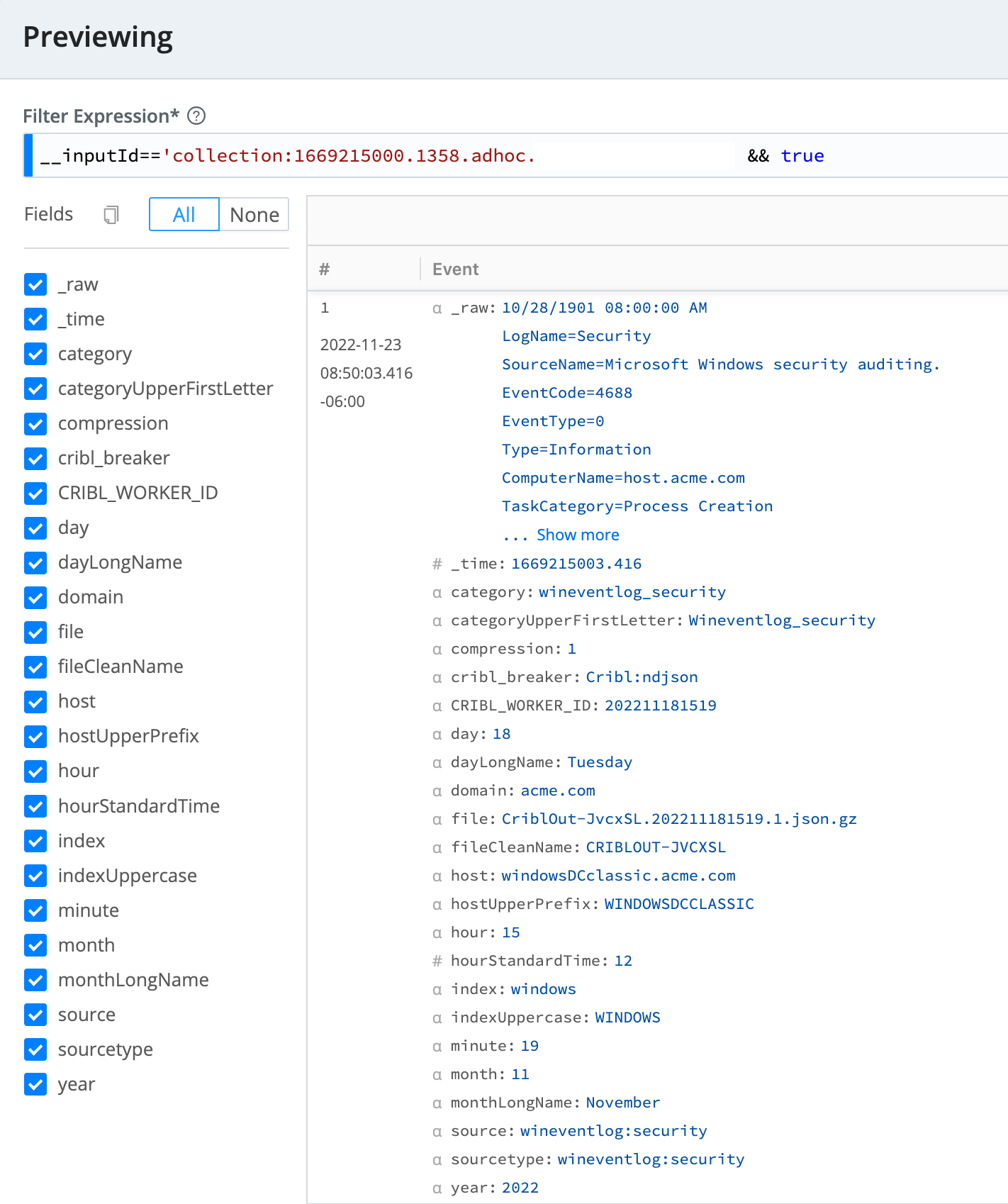
Here is a corresponding example event, as collected/replayed from S3. The metadata fields at the bottom show the results of the path extractor expressions:
S3 Permissions
The following permissions are required on the S3 bucket:
s3:GetObjects3:ListBuckets3:GetBucketLocation- Needed if Region is not configured.
Temporary Access via SSO Provider
You can use Okta or SAML to provide access to S3 buckets using temporary security credentials.
Troubleshooting
When permissions are correct on the object store, and events are reaching the Collector, the Preview pane will show events and the Job Inspector will show an Events collected count.
However, if previewing returns no events and throws no error, first check your Filter expression by previewing without it by simplifying the Filter expression to true. Then check the Job Inspector: If the Total size is greater than 0, and the Received size is NA or 0, make sure you have list and read permissions on the object store.
If you’re still not seeing events, try setting your S3 Collector’s Path expression to a /.
Encrypted Data
To collect encrypted data, such as CloudTrail logs, you’ll need to add access to the KMS resources in your KMS Key Policy. Add the IAM user or role to the Principal section of your Key Policy and provide the kms:Decrypt Action. See Amazon’s documentation on Key Policies for more information, including how to view and change your policy.
Proxying Requests
If you need to proxy HTTP/S requests, see System Proxy Configuration.
Internal Fields
Cribl Stream uses a set of internal fields to assist in data handling. These “meta” fields are not part of an event, but they are accessible, and you can use them in Functions to make processing decisions.
Relevant fields for this Collector:
__collectible- This object’s nested fields contain metadata about each collection job.collectorType: Indicates the type of Collector used for the job.collectorId: Represents the Collector ID of the Collector, as configured during setup.
__inputId- Uniquely identifies the origin of data for a collection job. Its format varies depending on whether the job is ad hoc or scheduled:- Ad hoc jobs are formatted as
collection:<timestamp>.<randomId>.adhoc.<Collector ID>.<timestamp>: The Unix timestamp when the job was initiated.<randomId>: A random identifier to ensure uniqueness.adhoc: Indicates the job was manually triggered.<Collector ID>: The ID of the Collector.
- Scheduled jobs are formatted as
collection:<Collector ID>.<Collector ID>: The ID of the Collector.
- Ad hoc jobs are formatted as