



These docs are for Cribl Stream 4.6 and are no longer actively maintained.
See the latest version (4.17).
CrowdStream
CrowdStream is a special Cloud-hosted version of Cribl Stream, available through CrowdStrike Falcon LogScale. This collaboration is tailored to forward data from a wide range of sources into LogScale for XDR analysis and log management.
En route, you can process events using all of Stream’s options for aggregating, sampling, redacting, cloning, and otherwise shaping and directing your data. CrowdStream provides parallel options to route data to cost-effective Amazon S3 storage, and to S3 data lakes, for later replay and analysis.
Getting Started
These steps assume that you’ve set up your CrowdStrike Falcon LogScale account, obtained your corresponding API token, and logged into LogScale.
- On the CrowdStream tile at right, click the Set up Cribl link.
- On the resulting Organization settings page, click Log in.

- This brings you to the CrowdStream home page. Click Manage on the CrowdStream tile at left.
On CrowdStream’s Worker Groups page, click the default Group’s tile at the upper left.
(A Worker Group is a collection of processing instances that share the same configuration. For details, see Cribl Stream’s Distributed Deployment topic.)
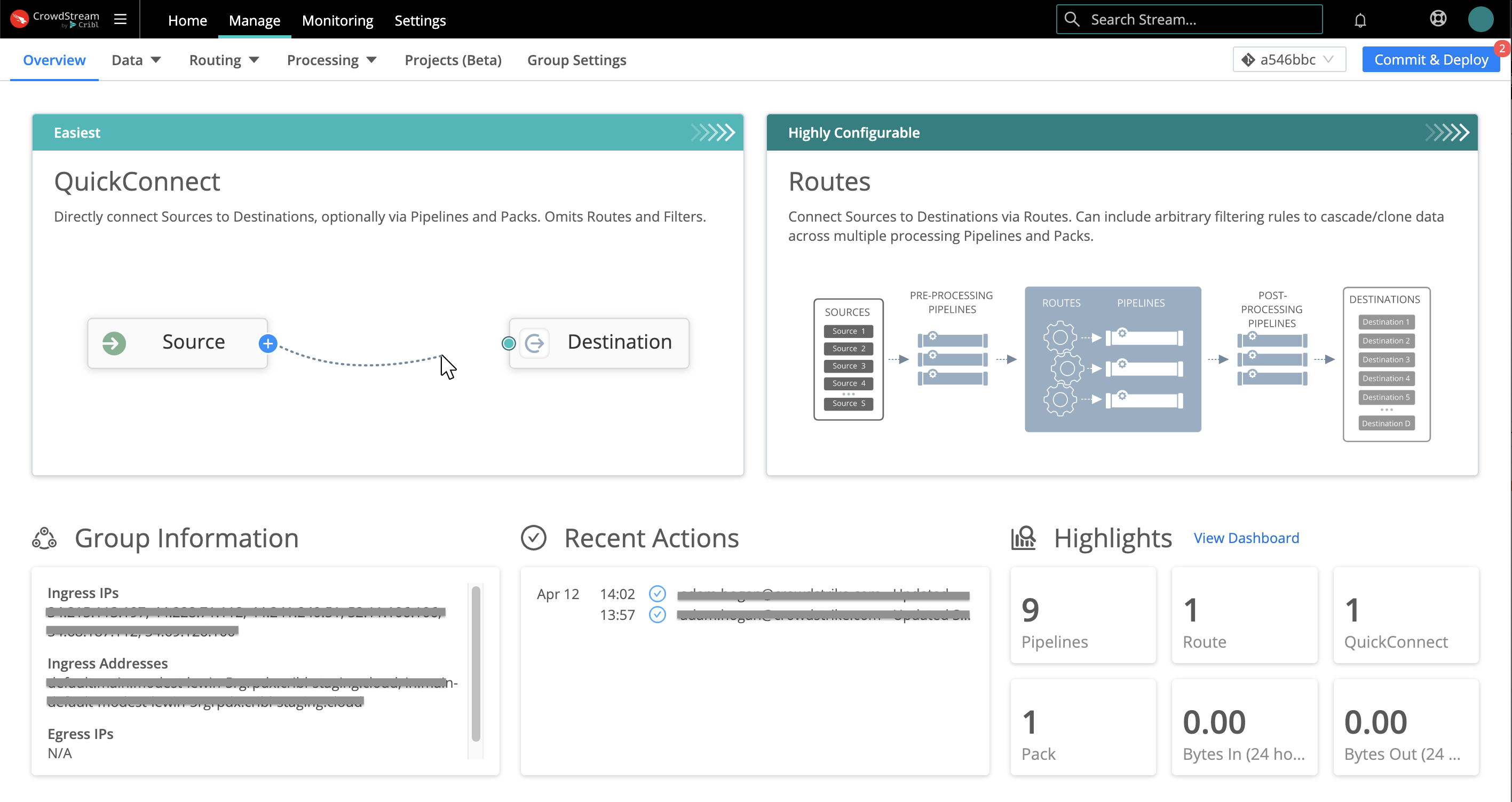
This brings you to the Manage page of CrowdStream’s top nav, and to the Overview tab of this Group’s submenu.
To begin configuring this Group, you now have a two-up choice of QuickConnect or Routes tiles. How to choose? See the next section.
For More Information
Simple or Complex Routing?
Your first choice is how simply or intricately you want to configure data flow from the first data Source you set up. CrowdStream offers two user interfaces:
QuickConnect (the left tile shown above) provides a simple visual UI. You drag and drop connections from Sources on the left to Destinations on the right. Each connection can include as much or as little intermediate processing as you like. To remove a connection, just drag it off the Destination (you’ll get a confirmation modal). The only practical limitation here is that data flow through every Source -> Destination connection must be parallel and independent.
Data Routing (the right tile shown above) provides fine-grained control, via a more traditional UI that you configure across separate modals and pages. You build a Routing table with conditional processing. This can cascade and clone data across multiple processing Routs, according to the arbitrary filtering rules and sequence that you define.
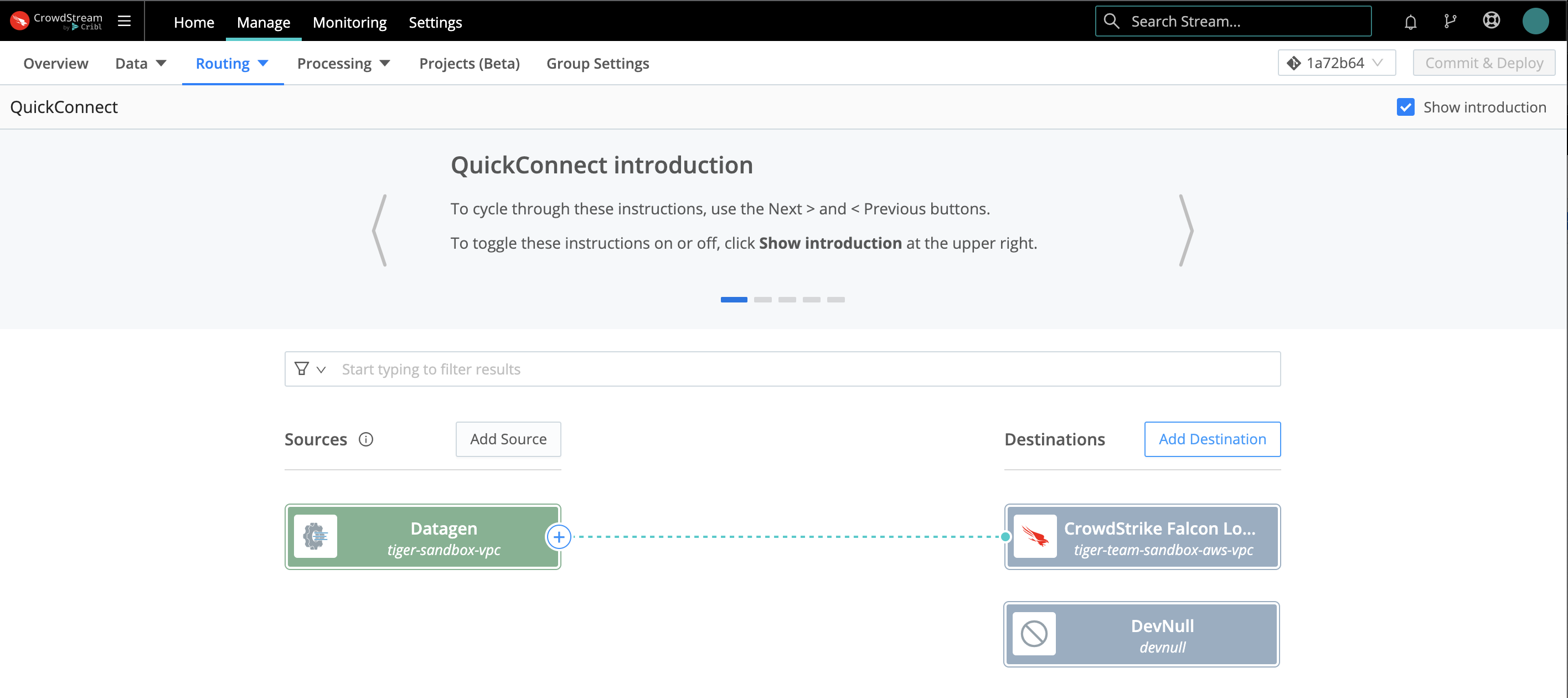
So the trade-off between these two options is ease of use versus flexibility. These two options are separate, but not mutually exclusive: You can set up simultaneous data flows through QuickConnect and Data Routes.
You can also move Sources, and their connections to Destinations, between the two UIs. So one obvious option is to configure your first data flow in QuickConnect, and then move to the Routing UI as your familiarity and needs expand.
Here is a lightning-fast (one-minute) preview of all the configuration steps below, in QuickConnect:
Navigate Between User Interfaces
To work in QuickConnect, click the left tile shown above, or select Routing > QuickConnect.
To work in the Routing UI, click the right tile shown above, or select Routing > Data Routes.
You can always switch between the two environments from a Group’s Manage > Overview tab, by using the Routing submenu.

Configure a Source
A CrowdStream Source is a model of an upstream service sending data into the system. In this model, you configure authentication and/or other needed parameters.
You can configure multiple instances of a given Source type, each with different parameters. You can also attach processing that’s specific to each instance. CrowdStream provides the Datagen Source type to generate sample inbound events for development and testing.
Using QuickConnect
In QuickConnect, click the Add Source button on the left (Sources) side. In the resulting left drawer, search for and click your desired Source type to begin configuring a new instance of that Source.
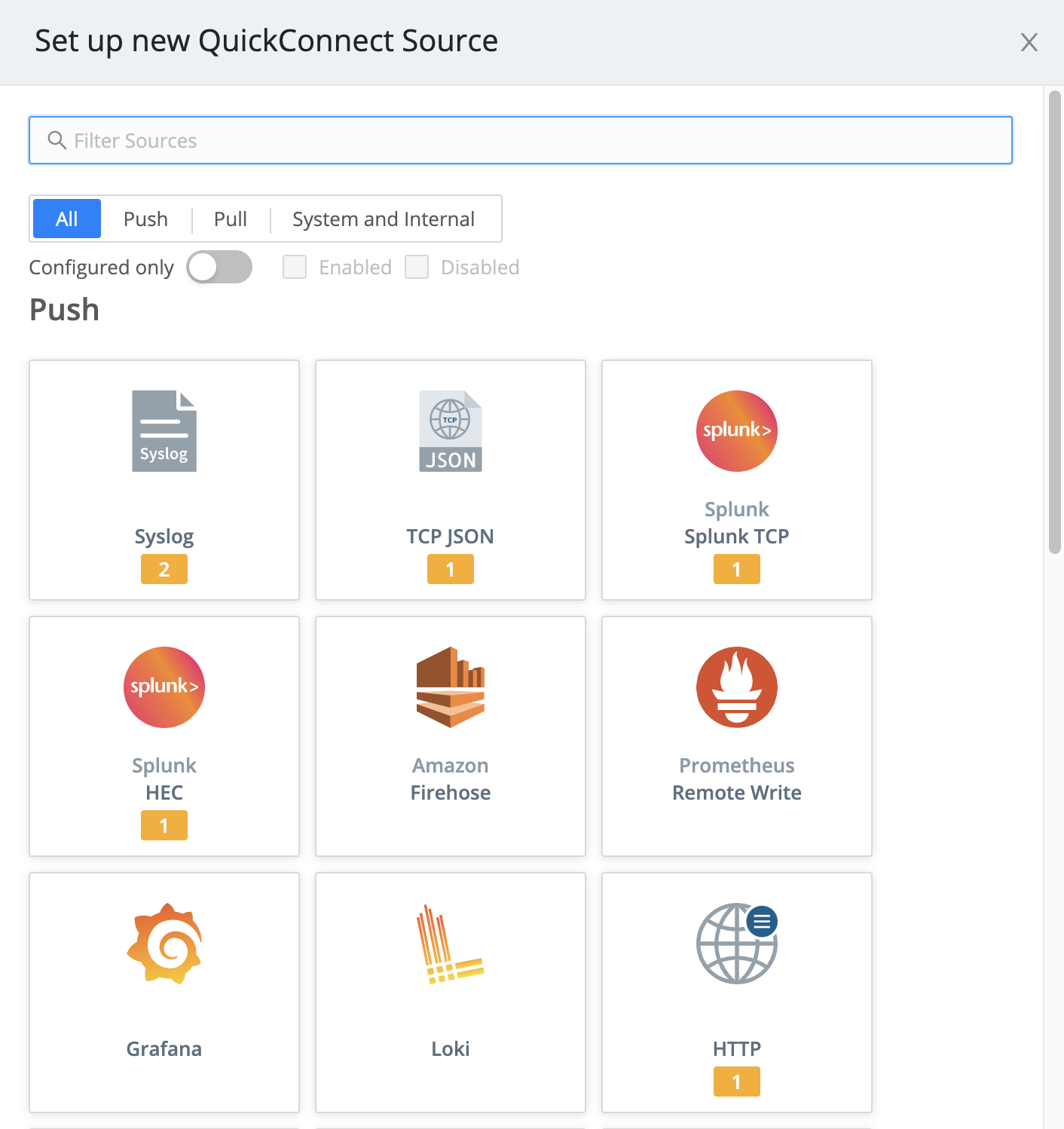
To configure (or reconfigure) a Source that’s already present in QuickConnect, hover over its tile and click the ⚙️ Configure button. Note that for multiple Sources of the same type, tiles will display stacked until you hover over the stack.
Using Data Routes
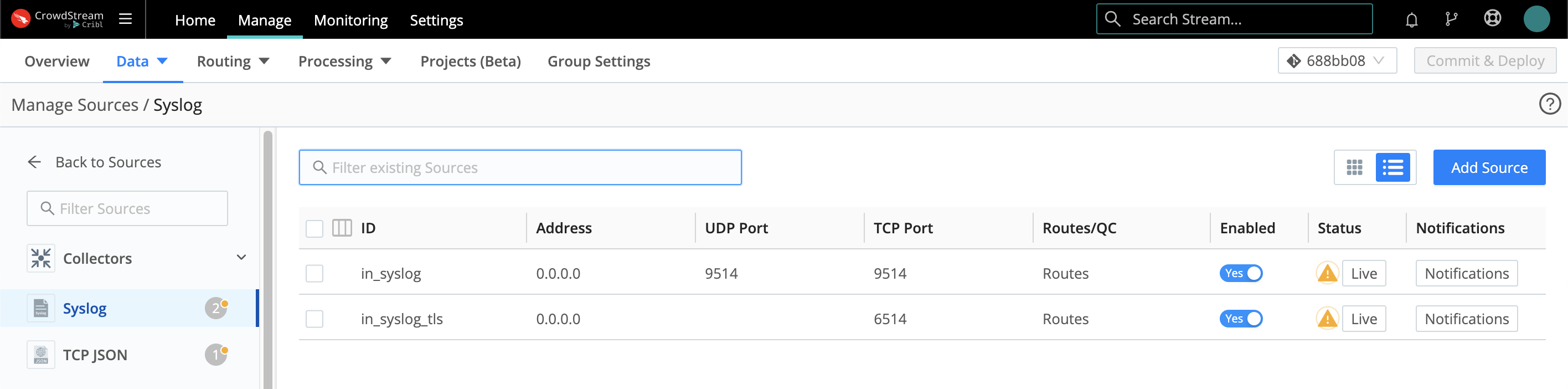
In the Routing UI, first click Data > Sources.
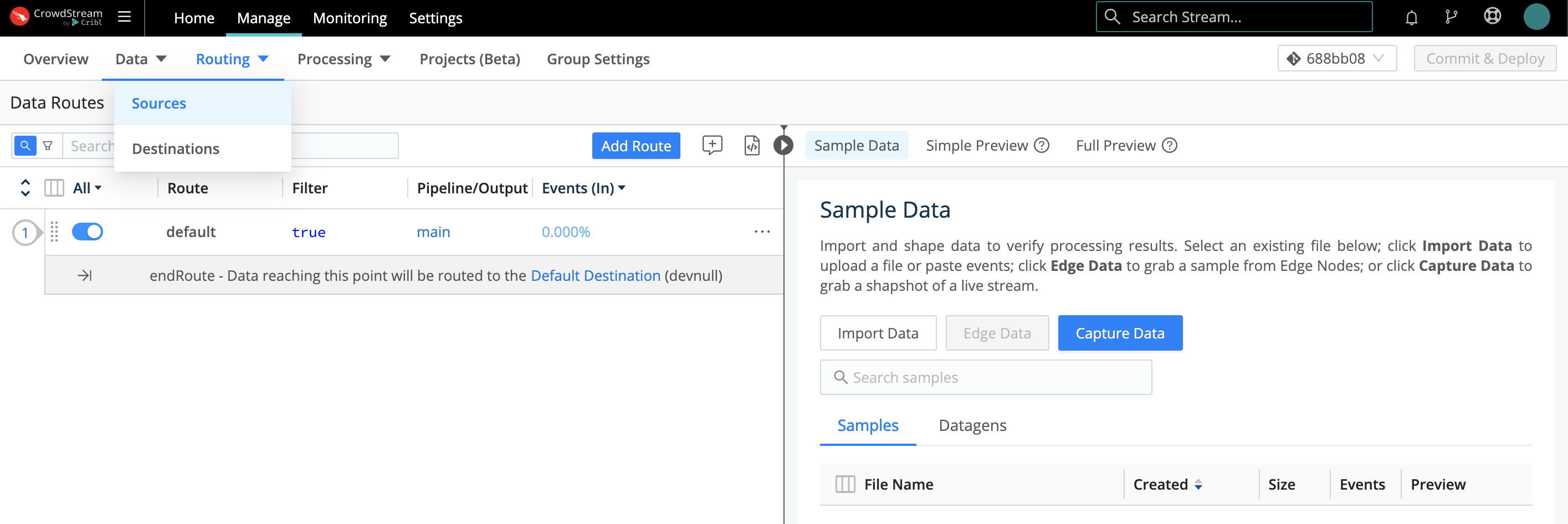
On the resulting Manage Sources page, search for your desired Source type, then click its tile to begin configuring a new instance of that Source.
(After you click through to a Source, the same set of peer Sources will be available in the left nav.)
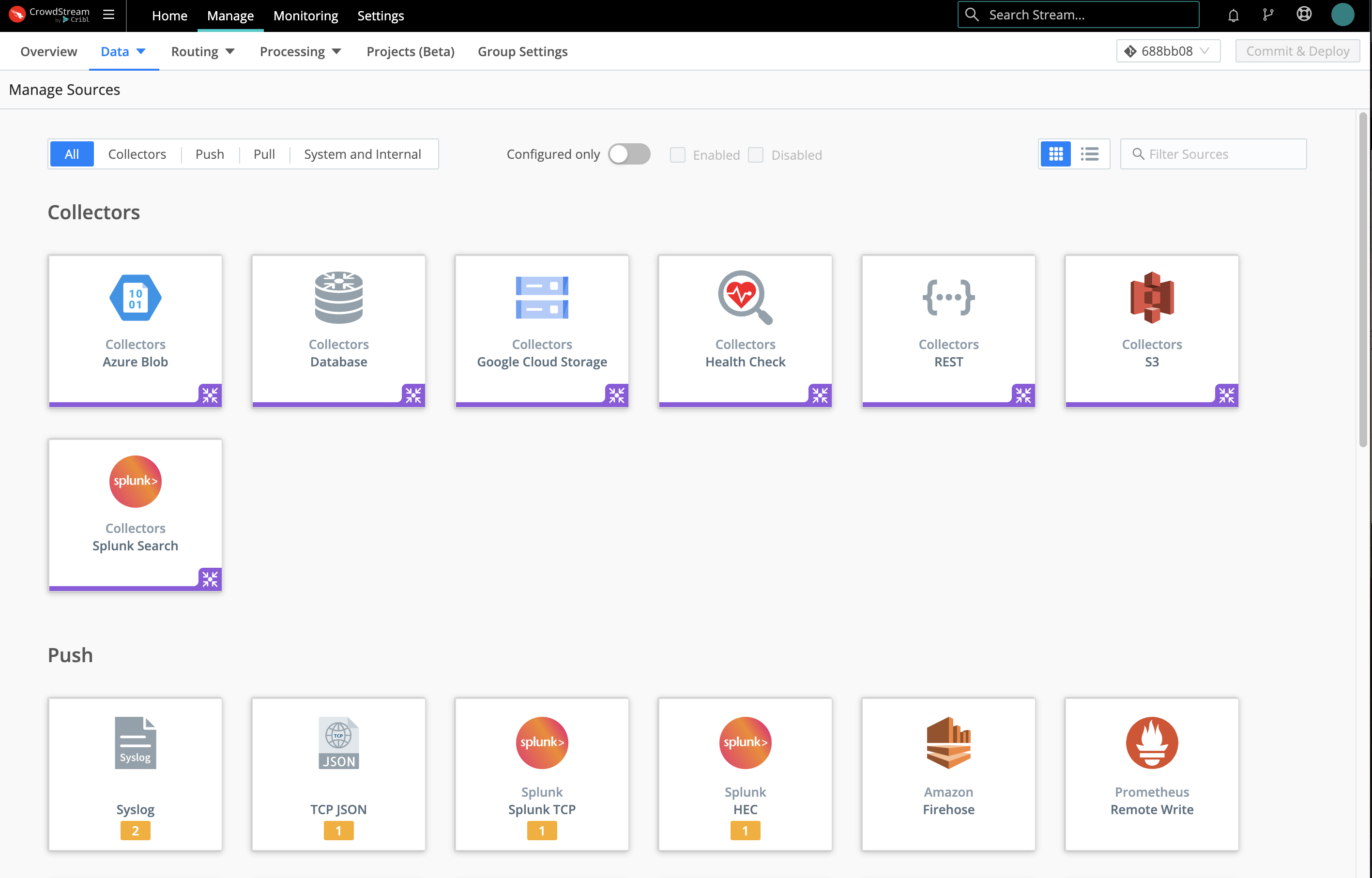
Click an existing Source’s row here to access its configuration, or click Add Source to configure a new instance of that Source.
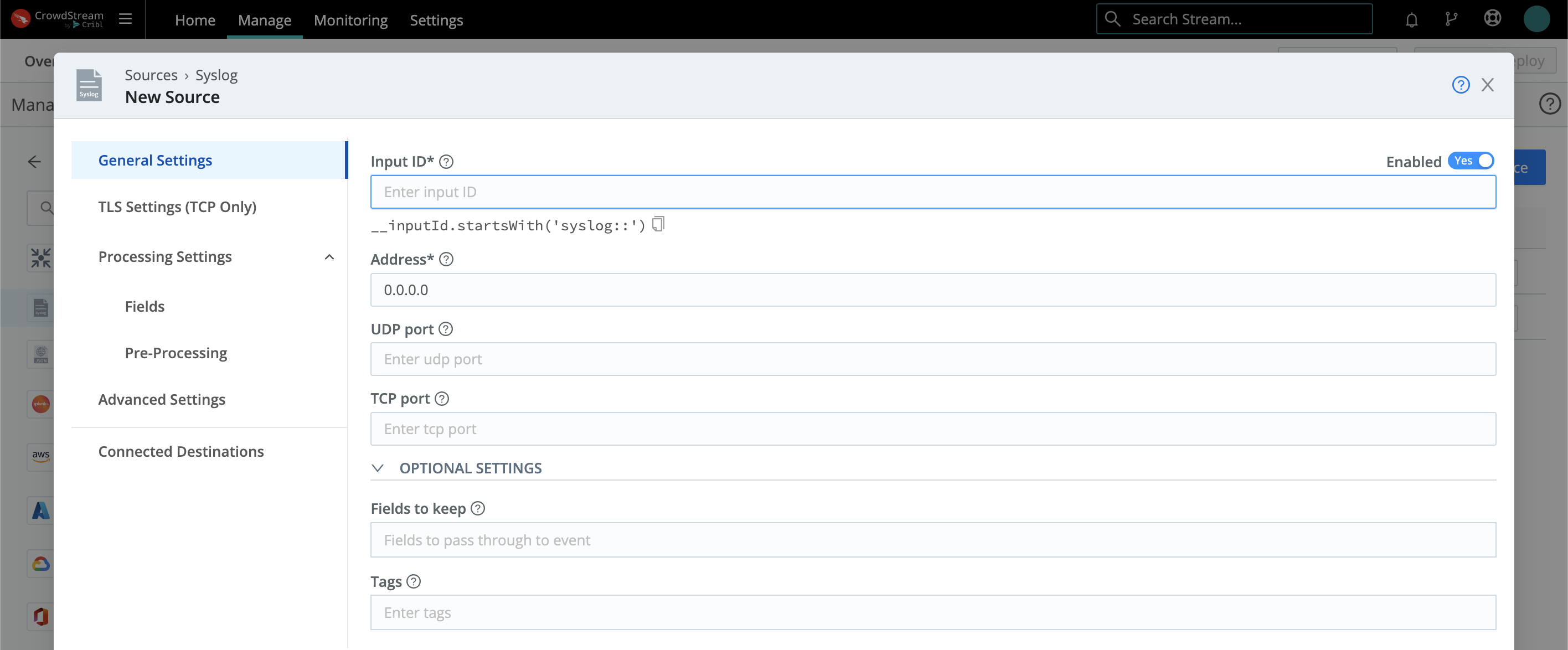
You then configure (or reconfigure) the Source in a modal like this:
For More Information
Configure a Destination
A CrowdStream Destination is a model of a downstream receiver of events, enabling you to configure authentication and/or other needed parameters.
As with Sources, you can configure multiple instances of a given Destination type, each with different parameters. You can attach processing that’s specific to each instance. CrowdStream provides the following Destinations:
- CrowdStrike Falcon LogScale - Set up your LogScale endpoint, token, and other parameters here.
- Amazon S3 Compatible Stores - Route full-fidelity data to cost-effective storage for later replay and analysis.
- Data Lakes > Amazon S3 - Store full-fidelity data for later retrieval or analysis. Compatible with Cribl Search (a separate product).
- DevNull - This output simply consumes and discards events, to facilitate development and testing.
Using QuickConnect
To connect a configured Source to a Destination tile already present on the right, just drag from the Source and drop the connector onto the Destination. A pop-up will prompt you to configure the connection via a Passthru, Pipeline or Pack (explained below).
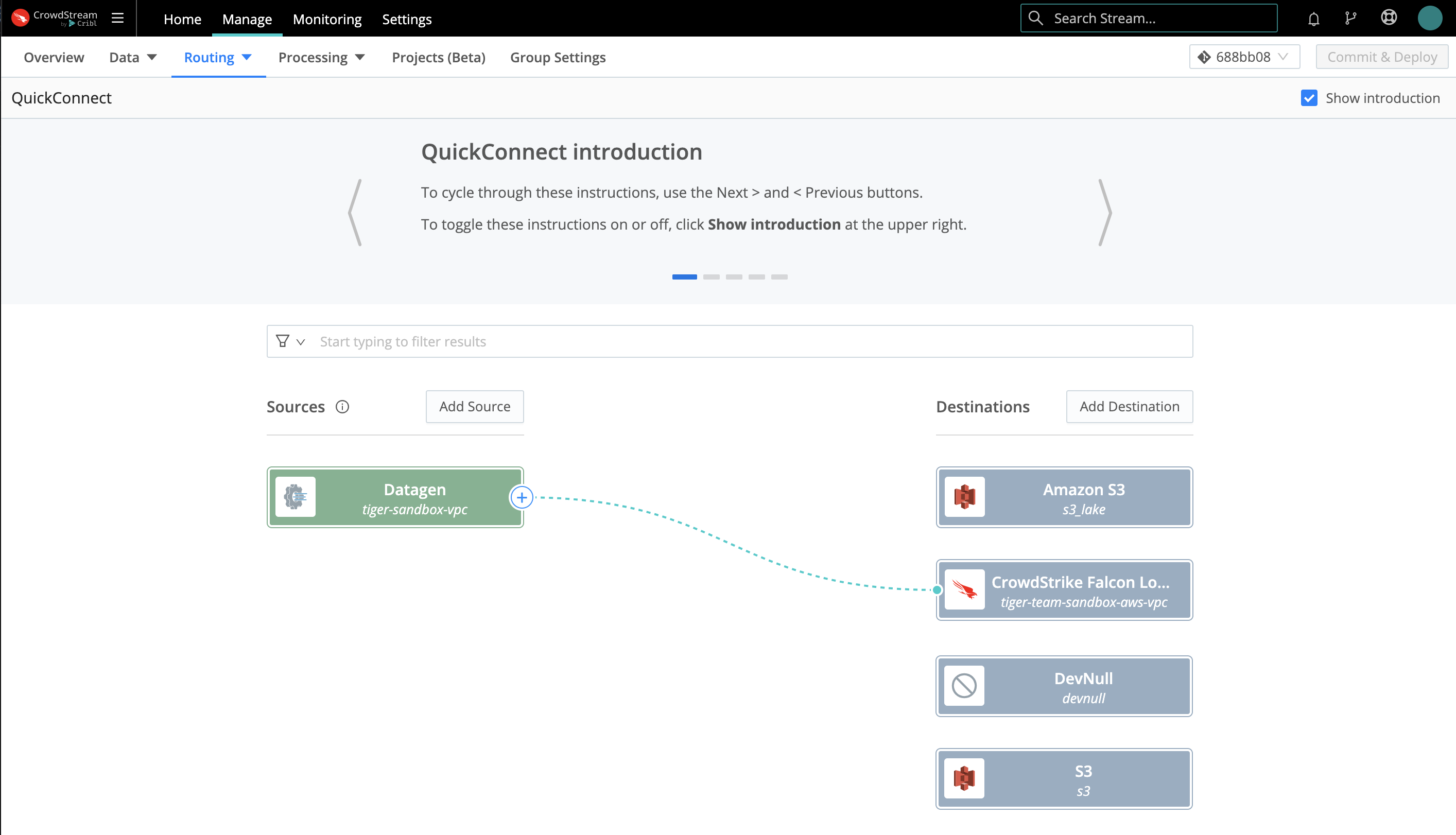
To configure (or reconfigure) the Destination, hover over its tile and click the ⚙️ Configure button. For multiple Destinations of the same type, tiles will display stacked until you hover over the stack.
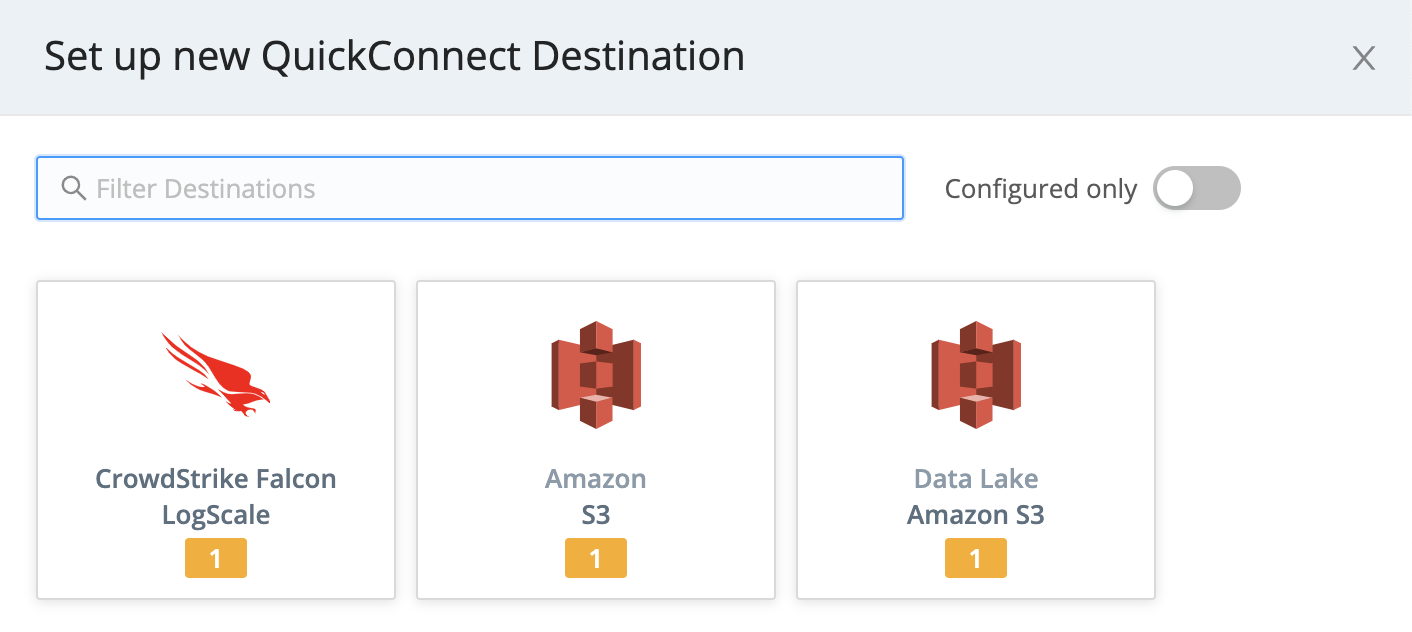
To add a new Destination, click the Add Destination button on the right (Destinations) side. In the resulting right drawer, search for and click your desired Destination type to begin configuring a new instance of that Destination.
Using Data Routes
In the Routing UI, first click Data > Destinations. On the resulting Manage Destinations page, search for your desired Destination type, then click its tile to begin configuring it.
(After you click through to a Destination, the same set of peer Destinations will be available in the left nav.)
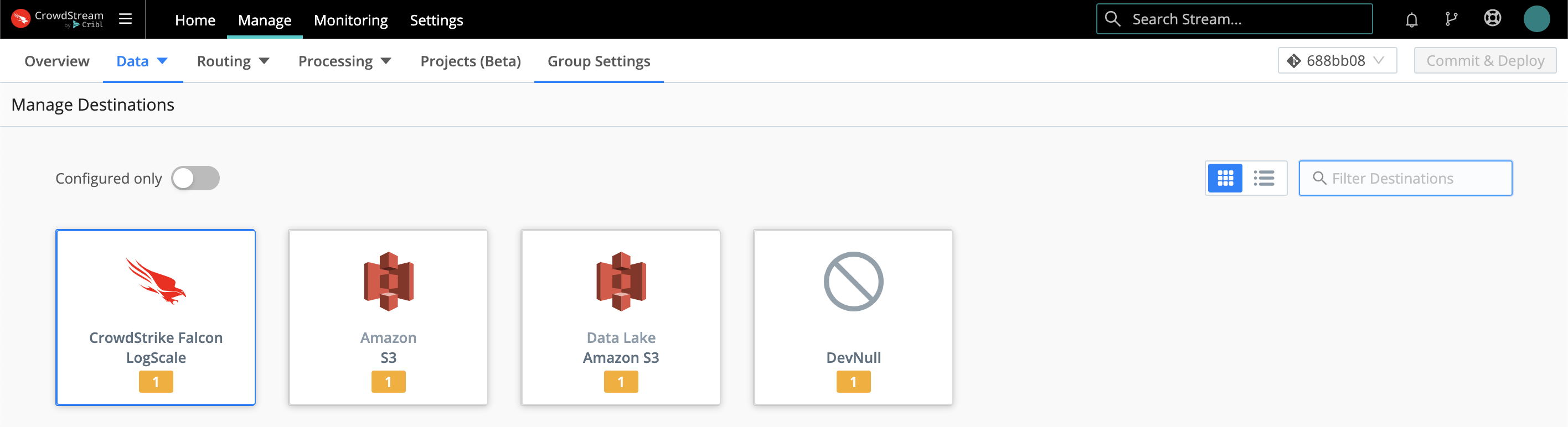
Click an existing Destination’s row here to access its configuration, or click Add Destination to configure a new instance of that Destination.
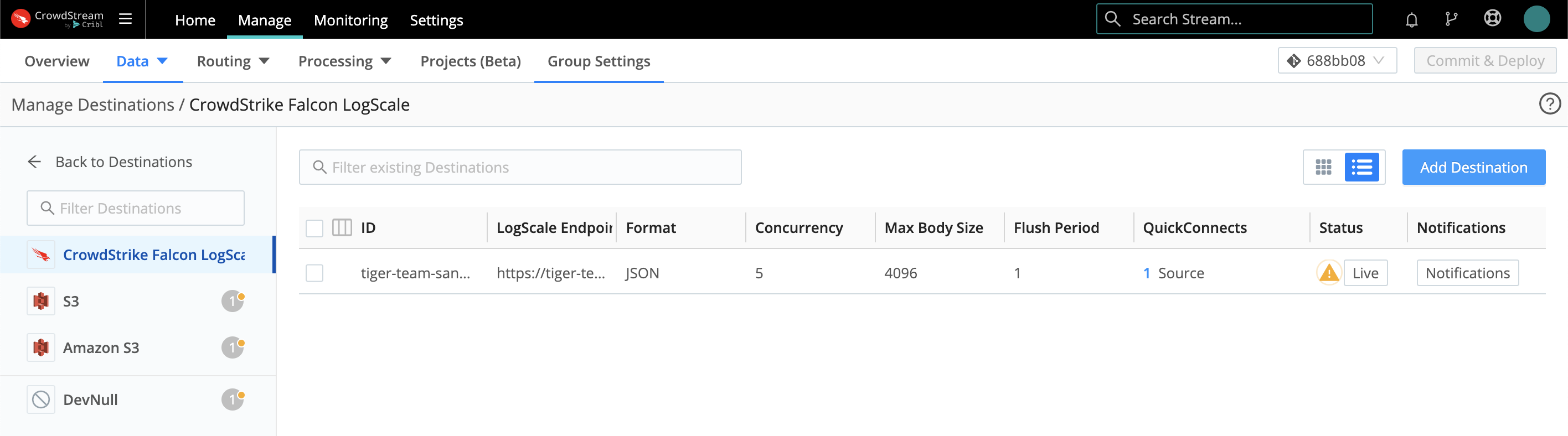
You then configure (or reconfigure) the Destination in a modal like this:
For More Information
- See the individual Destination topics linked at the head of this section.
Connect: Passthru, Pipeline, or Pack
In QuickConnect, as soon as you drag and drop a Source -> Destination connection, a pop-up dialog will prompt you to select a connection type: Passthru, Pipeline, or Pack. (In Data Routes, you’ll make the same choices elsewhere.)
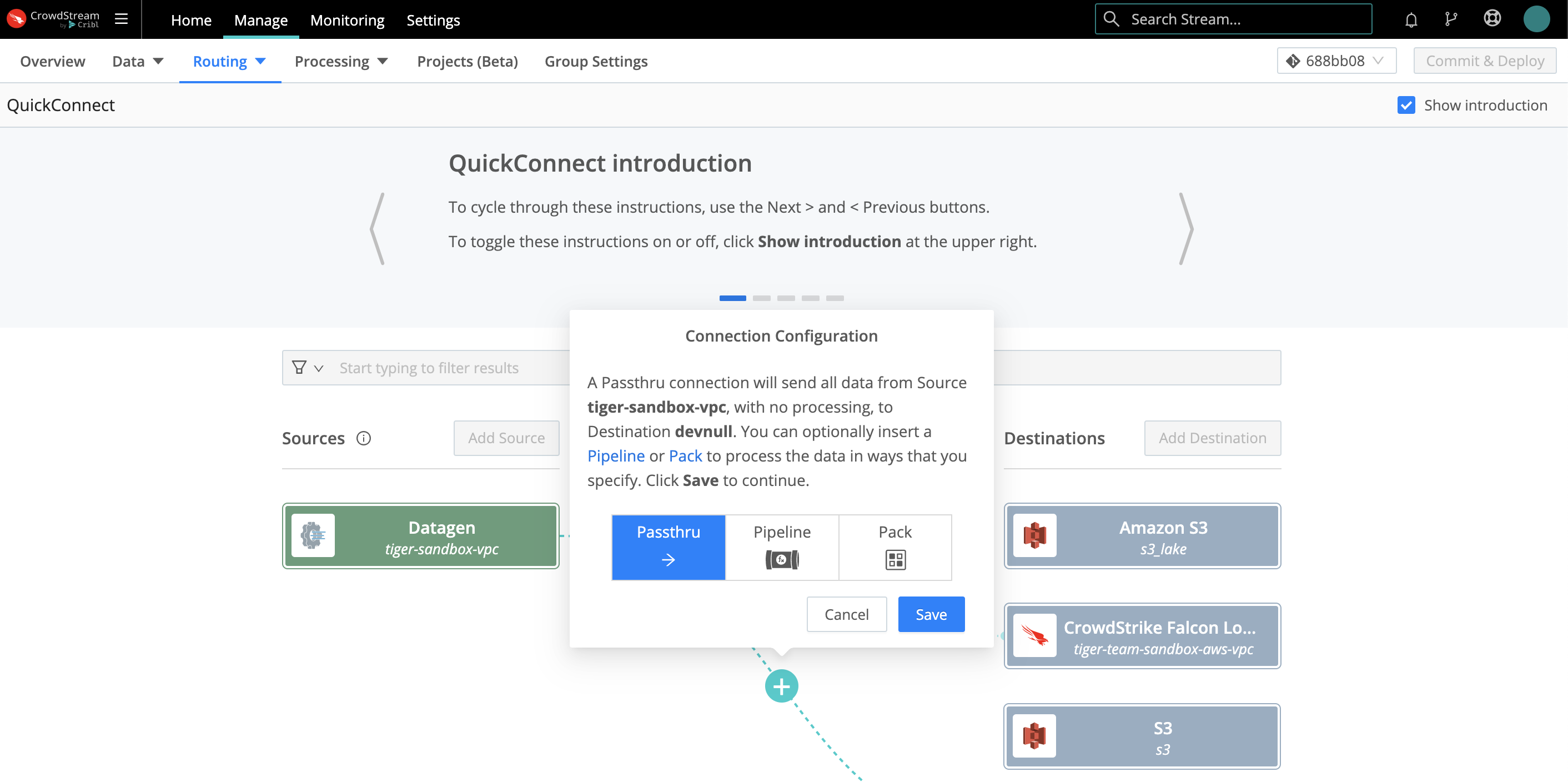
What are these options?
A Passthru establishes a simple direct connection between a Source -> Destination pair.
A Pipeline hosts a stack of Functions to process your data, in the order you arrange them.
A Pack is a microcosm of a whole CrowdStream configuration, designed to share configs between Worker Groups or deployments. A Pack can encapsulate its own Pipelines, Routes, Knowledge libraries, and sample data (but not data Sources or Destinations). A Pack can snap in wherever you can use a Pipeline.
So let’s unpack Pipelines, where you’ll define most of your event processing.
Pipeline Options
When you first create a new Pipeline, it’s empty, making it equivalent to Passthru. CrowdStream provides a set of out-of-the-box Pipelines for specific purposes. As you can see below, one of these is a passthru Pipeline. This similarly contains no Functions - making it the Data Routes UI’s equivalent of QuickConnect’s Passthru button.
For these reasons, it’s easy to start with an empty Pipeline, and then add Functions as you need them.
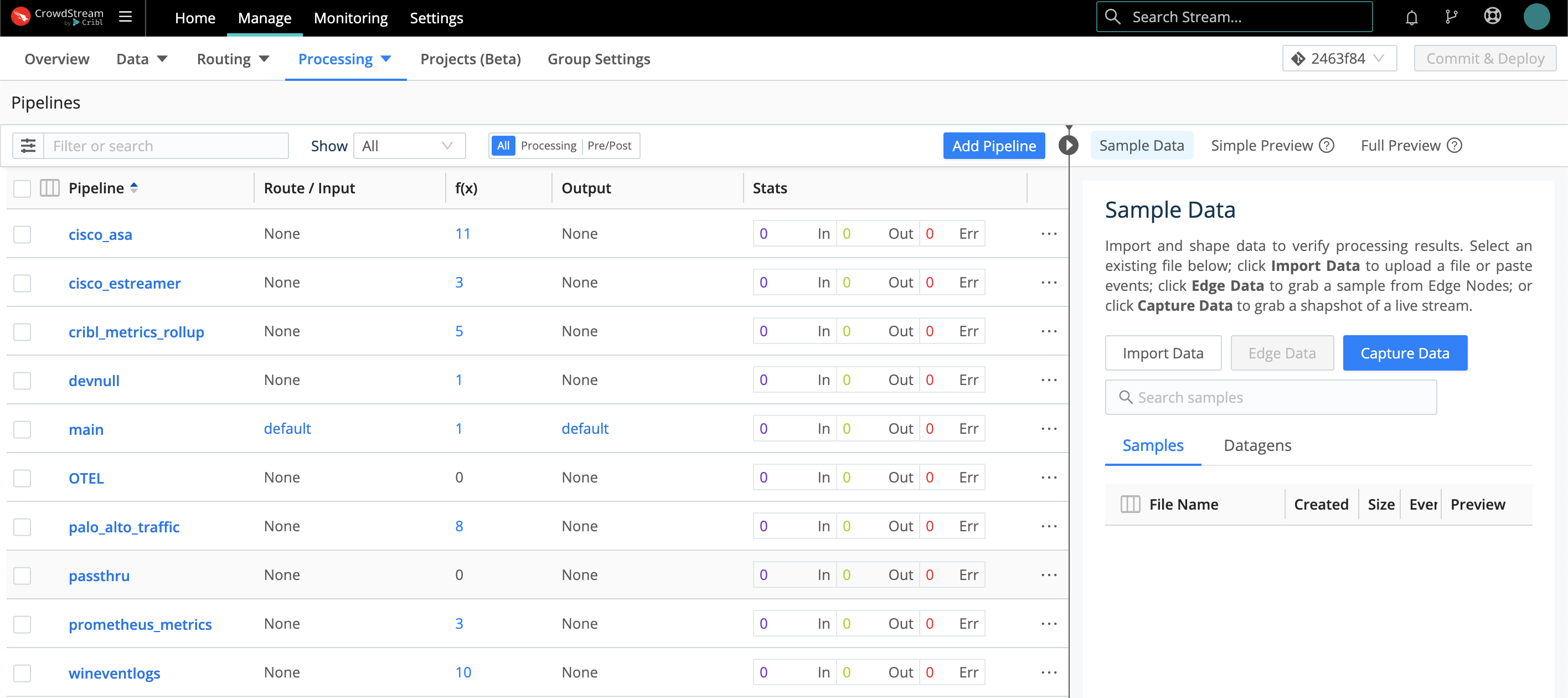
A Pipeline, as you populate it, is a stack of processing Functions and optional comments. Use the accordions on the left to expand or collapse each Function. Use the toggles on the left to enable/disable each Function - preserving structure as you develop and debug.
Use the right Sample Data pane to preview how the Pipeline’s current state transforms a set of events. (Controls here enable you to capture live data, save it to sample or Datagen files, and reload those files.)
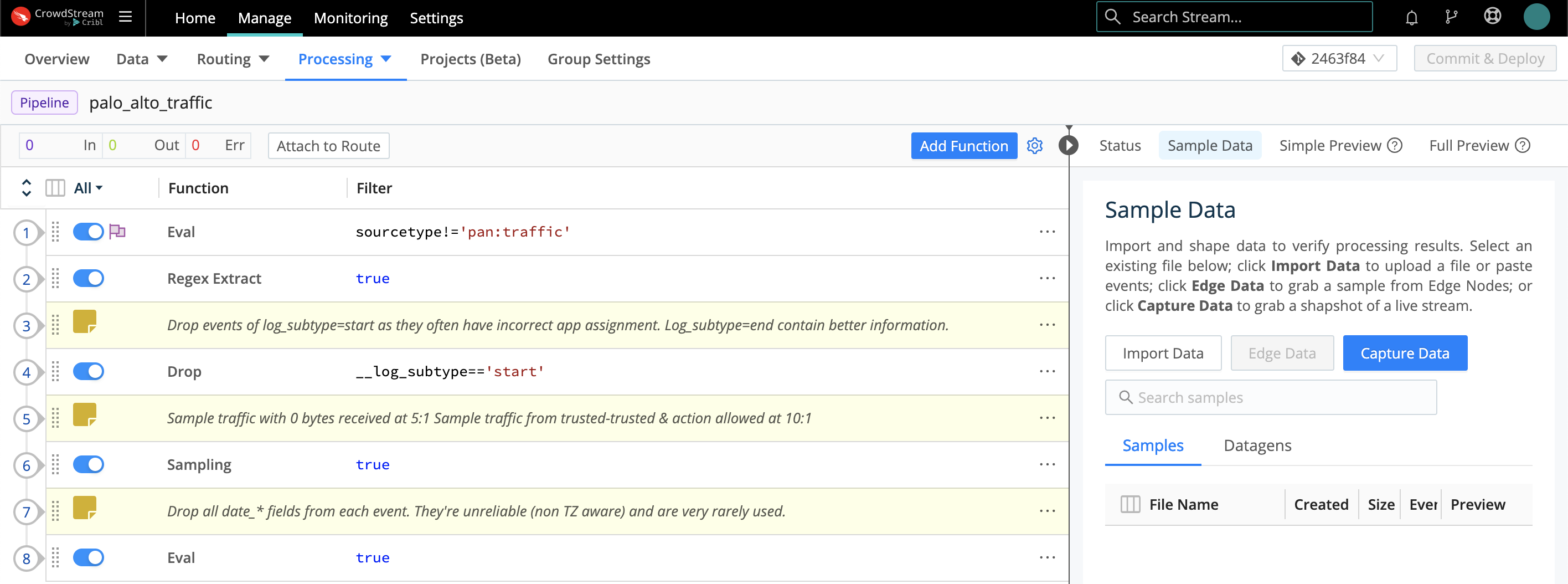
Although you’ll configure most data shaping in processing Pipelines between Sources and Destinations, you can also attach a pre-processing Pipeline to any Source instance, and a post-processing Pipeline to any Destination instance. Use these options when you need to “condition” the specific data type handled by a particular inbound or outbound integration.
Connect via QuickConnect
To select a connection type in QuickConnect, click the appropriate button in the pop-up dialog shown above. To accept the default Passthru option, just click Save. Your Source and Destination will now be connected.
If you select Pipeline, you’ll see an Add Pipeline to Connection modal. Here, you can click to select an existing Pipeline, or click Add Pipeline to define a new one. Then click Save here to establish the connection.
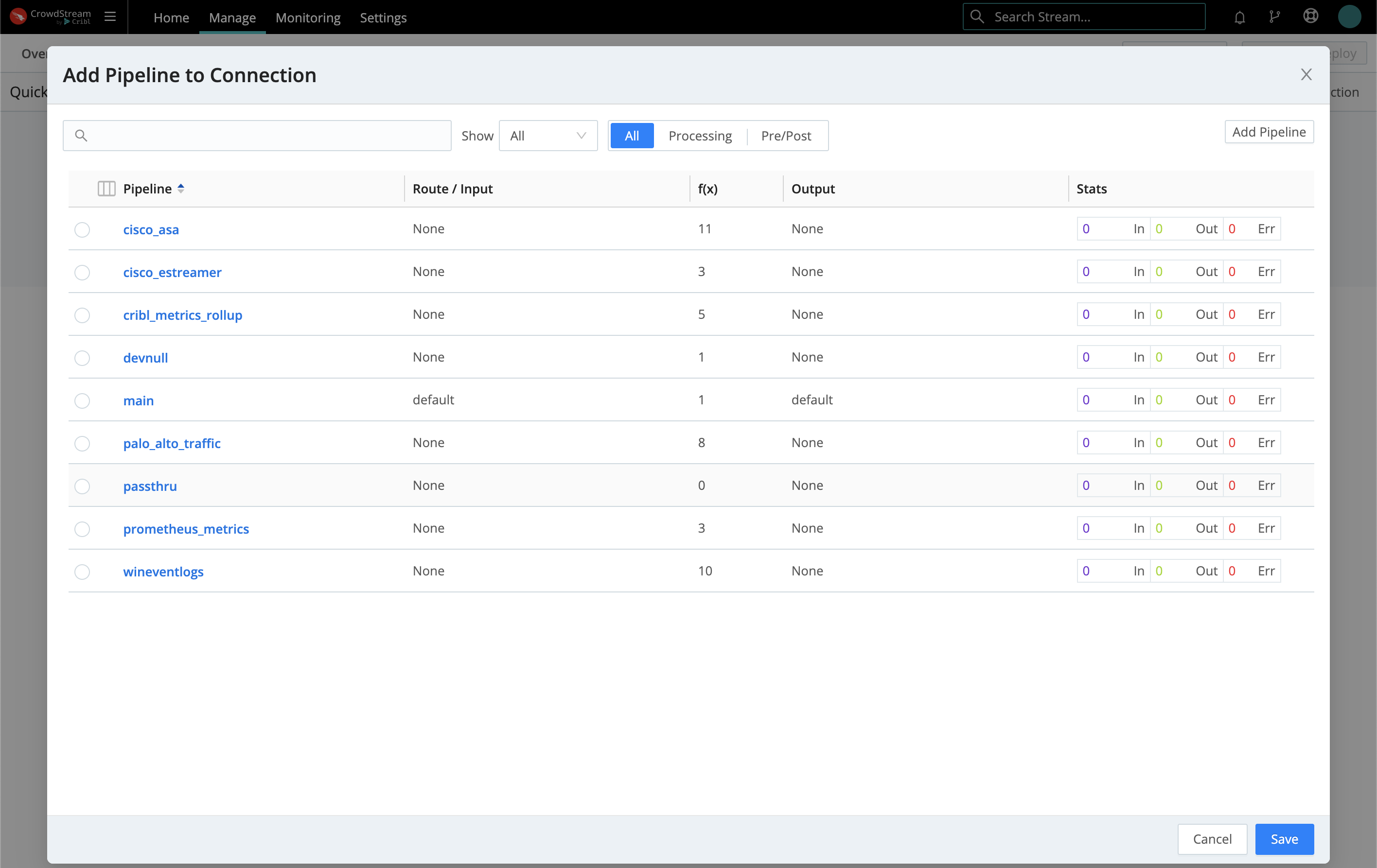
Selecting Pack opens an Add Pack to Connection modal that works exactly the same way.
Whichever option you choose here, your connection between this Source and Destination is now complete.
To get data flowing, jump ahead to commit and deploy your new configuration.
Connect via Data Routes
The Data Routes UI enables you to finely configure multiple, interdependent connections between Sources and Destinations. Events clone and cascade across a Routing table, based on the filtering rules and sequence you define.
In exchange for this flexibility, you sacrifice QuickConnect’s one-stop, snap-together UI metaphor. After configuring your Sources and Destinations - which you’ve already done above - you need to connect them by separately setting up at least one Pipeline and one Route.
Pipelines Access
From a Group’s Manage tab, select Processing > Pipelines. In addition to the minimal passthru Pipeline identified above, other simple building blocks here include main (which initially contains only a simple Eval Function) and devnull (which contains a single Function that just drops events).
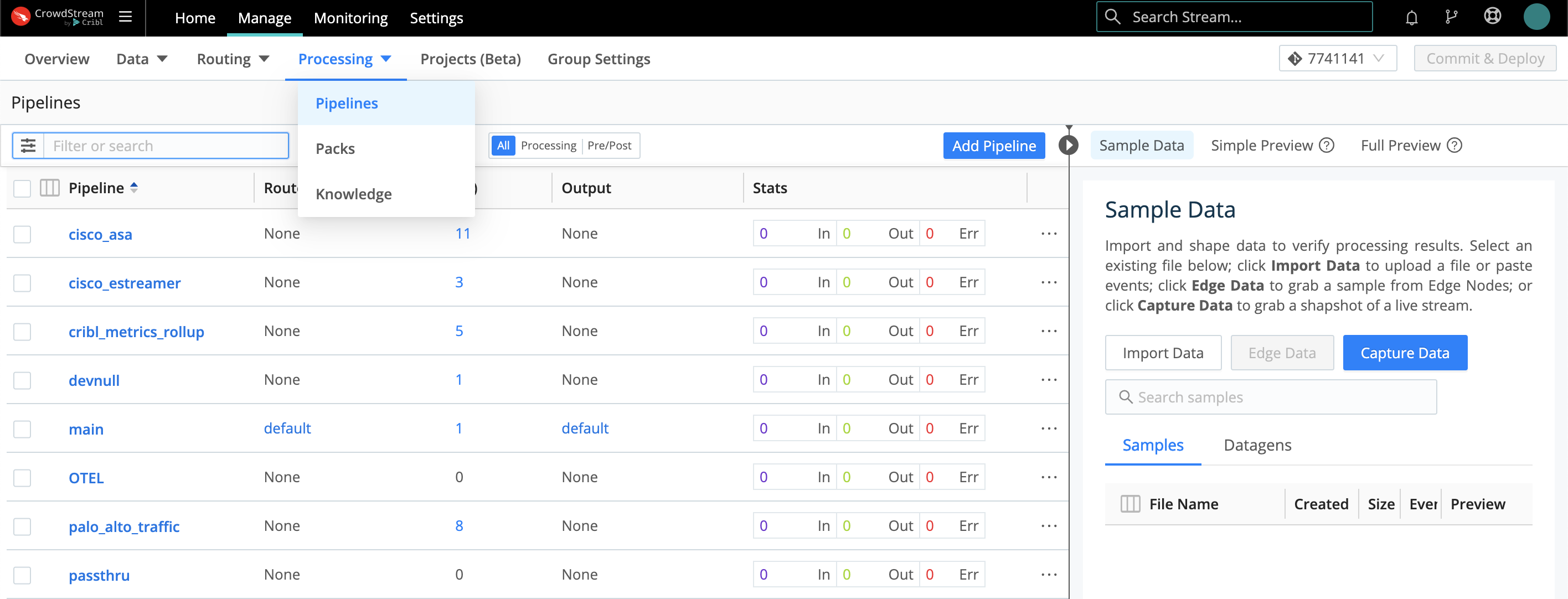
Out-of-the-box Pipelines are already connected to Routes. When you click into a Pipeline, you can hover to display the connected Route, as shown here. But as our final connection step, let’s next look at how to connect up everything (Source, Pipeline, Destination) in a Route.
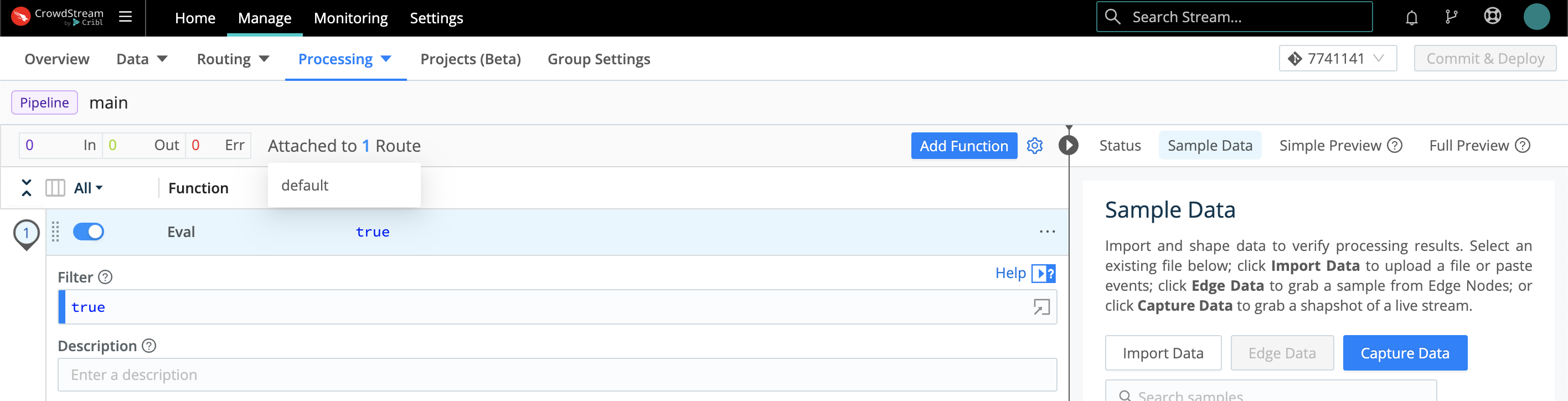
Configure a Route
In the Data Routes UI, a Route is where you complete a data-flow connection. Each Route connects exactly one Pipeline with exactly one Destination.
This combination can consume data from one, multiple, or all the Sources you’ve configured on the Data Routes side. (QuickConnect Sources are separate, but you can open those Sources’ configs to move them to the Data Routes UI.) This is governed by the filtering we’ll see below.
To open the Routing table, from a Group’s Manage tab, select Routing > Data Routes.
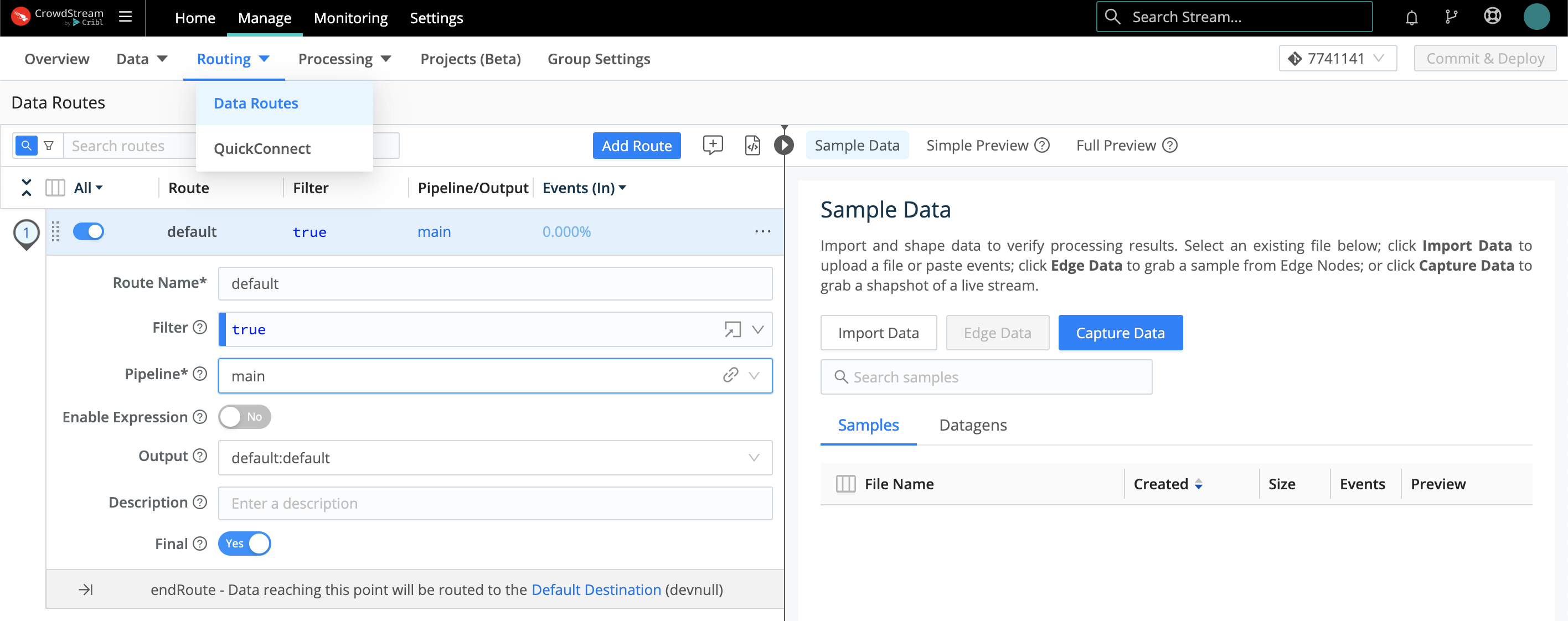
As you can see, CrowdStream ships with one starter Route named default. It’s configured as follows:
The Filter expression is set to true. This simple, default expression makes data from all active Sources available to this Route. (See finer filtering options below.)
The Pipeline drop-down is where you set the 1:1 Pipeline:Route connection. This starter Route’s Pipeline defaults to main, but you can select any one other configured Pipeline.
The Output drop-down defines the single Destination for this Pipeline:Route connection. If this isn’t already set to your LogScale Destination, you’ll most likely want to select that here. (Note that each option displayed on this list corresponds to the unique, arbitrary Output ID set on one instance of a Destination type. So some names might initially be unfamiliar.)

To get data flowing, jump ahead to commit and deploy your new configuration.
Filter a Route’s Input Data
When you want a Route to ingest data from only one Source, or a subset of Sources, you expand its Filter expression beyond the default true catch-all.
Filter is itself a drop-down. Open it to select among typeahead suggestions for several common inbound data types.
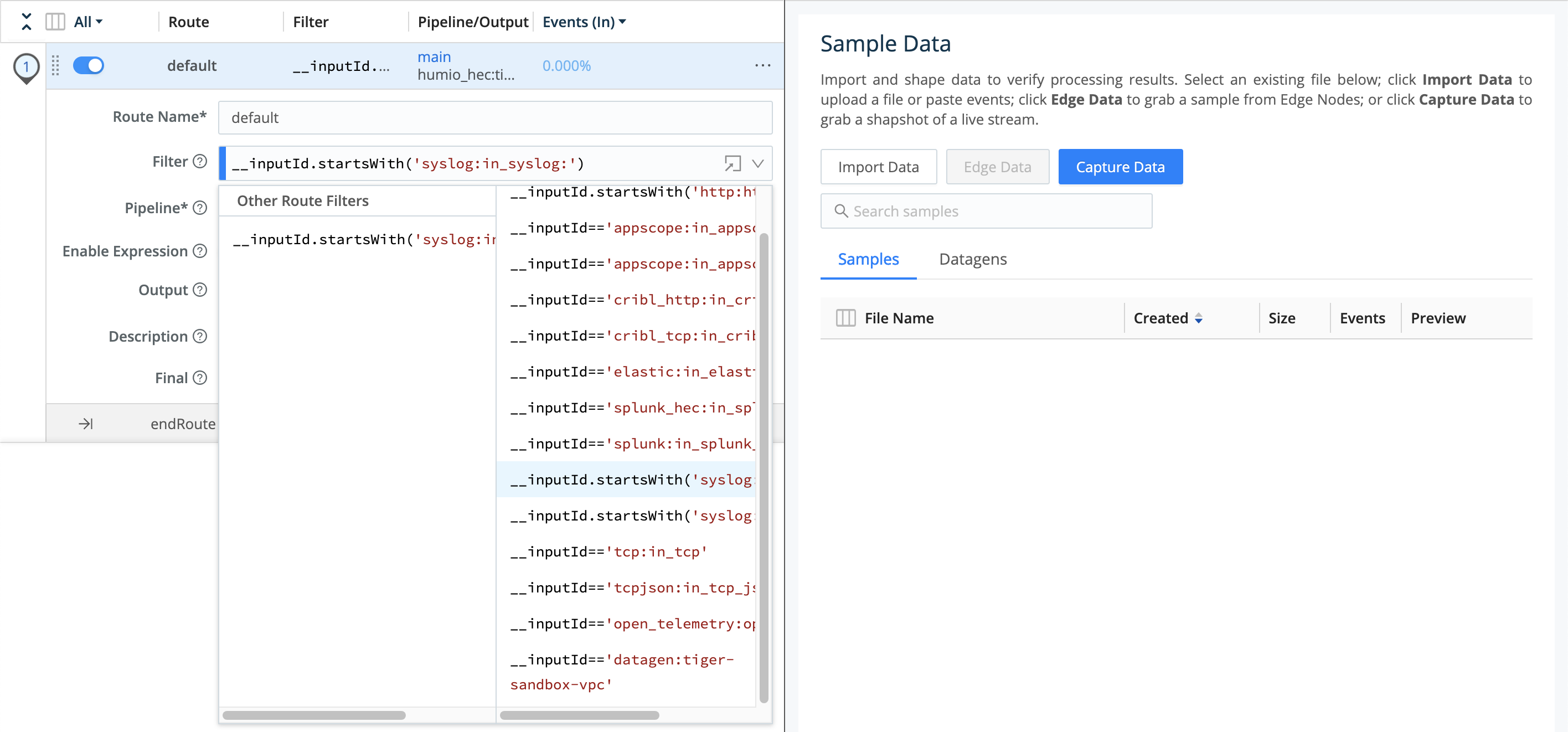
You can select one of these expressions and then modify it, using the same __inputId syntax. In the example expression below, note that the identifier after the : is - as with the Output options we saw above - the arbitrary name of one Syslog Source instance:
__inputId.startsWith('syslog:in_syslog:')
For More Information
Commit/Deploy Config Changes
To get data flowing as you expect, you’ll always need to use CrowdStream’s built-in Git version-control integration to commit your configuration changes and deploy them to your event-processing Worker instances. After any significant configuration change, you’ll be prompted with Group-level Commit/Deploy buttons like this at the upper right:

Depending on your version-control settings, Commit and Deploy might appear as separate buttons:

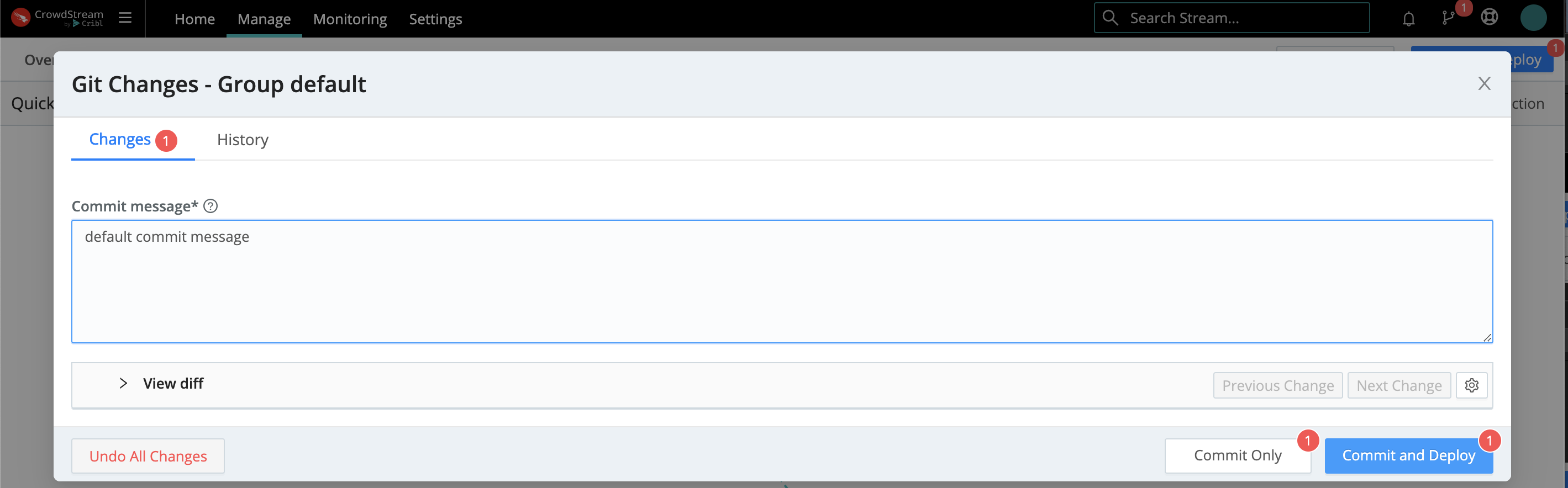
Clicking either flavor of the Commit button will display a confirmation modal like this. You can either accept the default commit message, or enter a specific message. Then be sure to select the appropriate buttons to both commit and deploy your changes.
Data should now start flowing through the Workers. (You can check this by selecting the top nav’s Monitoring link. This takes you to read-only dashboards, so remember to click Manage when you want to return to configuration options.)
In return for clearing all the red-dot prompts, your reward will be one more red dot, on the top nav’s CrowdStream-wide Version Control button. This is because CrowdStream sees the preceding deploy to Workers as a change to record (commit) on the Leader’s configuration.

This top-level commit isn’t necessary to enable data flow, but it backs up and safeguards your overall configuration. Click the button to display one final confirmation prompt:

Click Commit here, and your configuration is complete!
For More Information
Moving Ahead with CrowdStream
To quote a fundamental treatise on DevSecOps: you know all the rules by now, and the fire from the ice. To delve deeper into CrowdStream’s data shaping and routing options, follow these links to conceptual overview and reference topics.
For More Information
- Stream Basic Concepts
- Event Model
- Data Preview
- Functions
- Knowledge Objects
- Distributed Quick Start - This tutorial’s middle sections walk you through configuring Pipelines, Functions, and Routes, and scaling Workers, via the Routing UI
- Techniques & Tips
- Setup Guides