These docs are for Cribl Stream 4.6 and are no longer actively maintained.
See the latest version (4.17).
Lacework API Collection
You can configure the Lacework v2 API within Stream. This enables you to collect data from the Lacework API without introducing custom scripts or add-ons into your Lacework environment.
Your workflow will be based on the Discover and Collect pattern that’s standard for REST/API Collectors. In the Lacework API variation described here, the Discover job will generate the access token that the collection job uses in requests to the API. As an example, we’ll configure Cribl Stream to collect Host Vulnerability data, using optional filters available in the Lacework API.
Before you begin, make sure you have a Lacework API KeyID and secretKey, or create them as described in the Lacework docs.
Configuring the REST Collector
Collector Sources currently cannot be selected or enabled in the QuickConnect UI.
For additional details about all the configuration options specified here, see our REST/API Endpoint and Scheduling and Running topics.
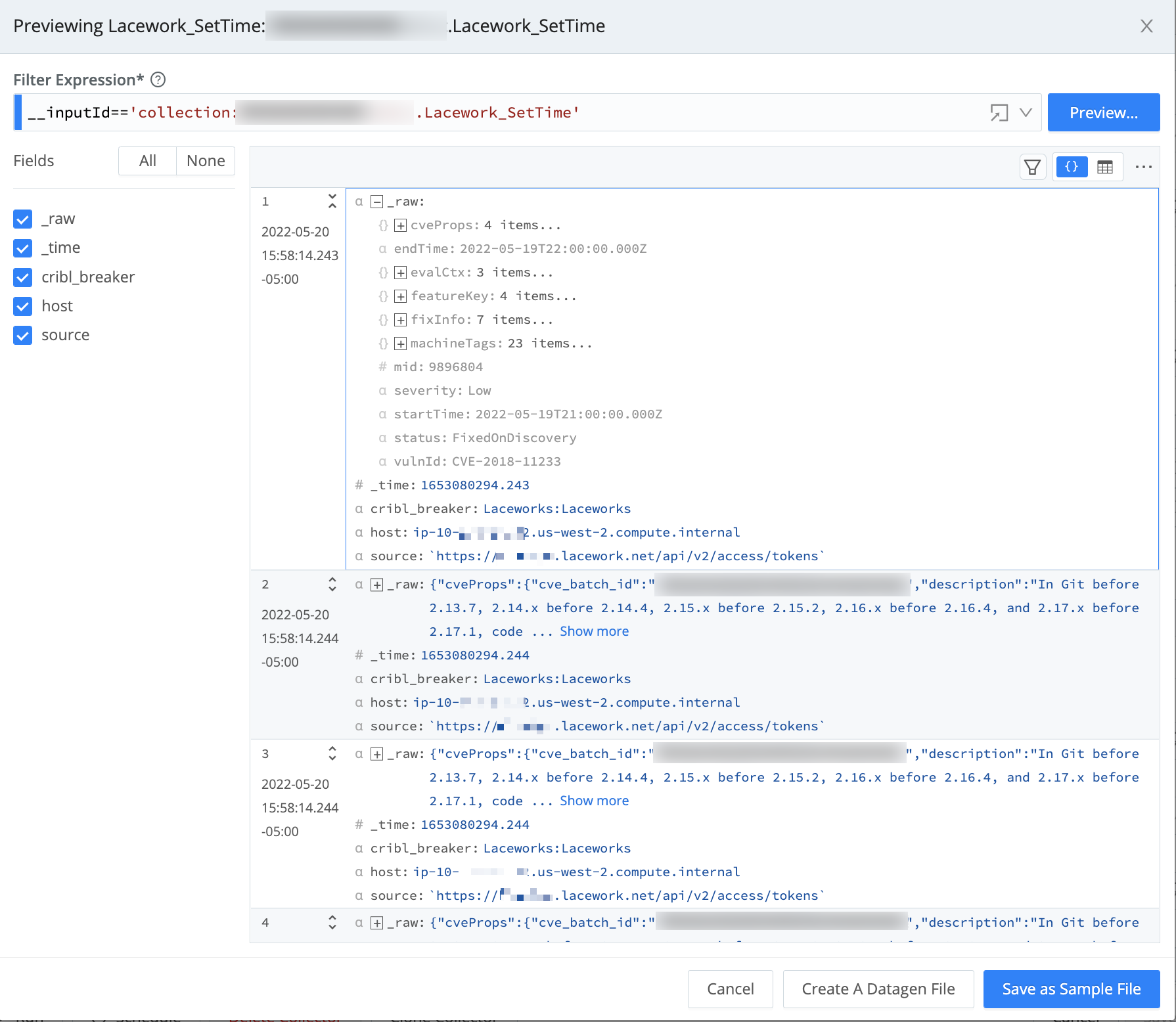
From the top nav of a Cribl Stream instance or Group, select Data > Sources, then select Collectors > REST from the Data Sources page’s tiles or the Sources left nav. Click Add Collector to open the REST > New Collector modal. Enter a Collector ID, then complete the following options and fields.
Discover Settings
From the Discover type drop-down, select HTTP Request. Then complete the Discover settings as follows.
Discover URL: Enter the URL at which Cribl Stream should access the Lacework v2/access/tokens endpoint.
Discover method: From the drop-down, select POST with Body.
Discover POST Body: Enter `{"keyId":"<keyID>", "expiryTime":3600}`, substituting your Lacework API KeyID for the placeholder.
Discover headers: Create the two headers specified in the table below, substituting your Lacework API secretKey for the placeholder.
| Name | Value |
|---|---|
U-LW-UAKS | '<secretKey>' |
Content-Type | 'application/json' |
Your Collector configuration should look similar to this:
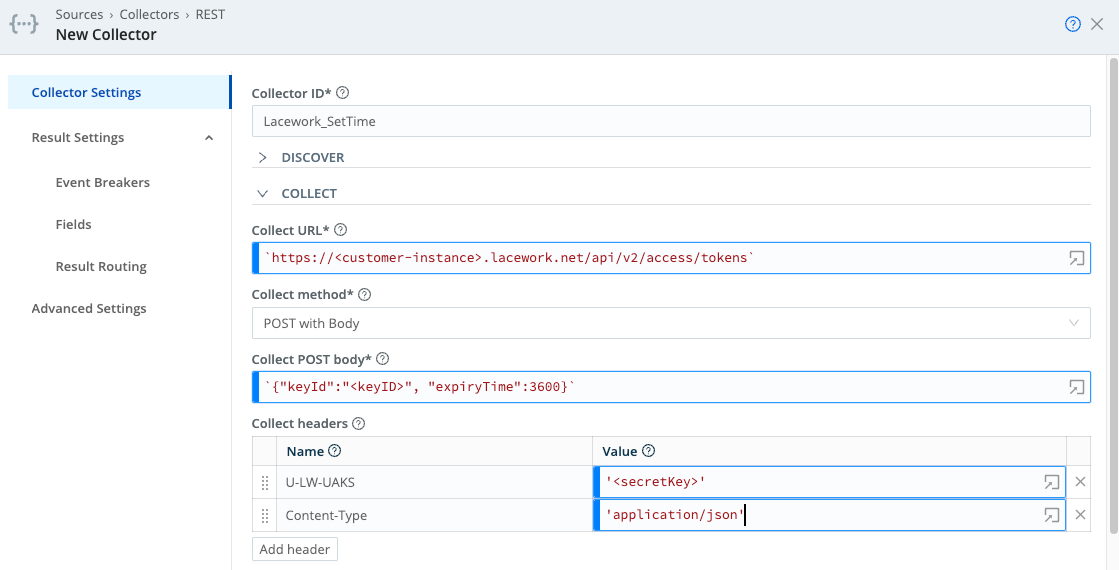
Collect Settings
Collect URL: Enter the URL at which Cribl Stream should access the Lacework v2/Vulnerabilities/Hosts/search endpoint.
Collect method: From the drop-down, select POST with Body.
Collect POST body: Enter the following request body.
`{"timeFilter": { "startTime": "${C.Time.strftime(earliest || new Date().getTime()/1000-(24*60*60), '%Y-%m-%dT%H:%M:%SZ')}", "endTime": "${C.Time.strftime(latest || new Date().getTime()/1000, '%Y-%m-%dT%H:%M:%SZ')}"},"filters": [ { "expression":"eq","field":"vulnId", "value": "CVE-2018-11233" } ] }` Here’s what’s happening in the request body example:
In our example, we’ve chosen to collect data only about hosts where one particular vulnerability, CVE-2018-11233, was detected. To accomplish this, we’ve added a filters element that specifies that the value of the vulnId field must equal CVE-2018-11233.
Note the earliest and latest variables. Later, in the Run Collector modal, you’ll set Time Range values that will populate these variables when the Collector runs. Both variables are formatted as UNIX epoch time, in seconds units. (When using them in contexts that require milliseconds resolution, multiply them by 1,000 to convert to ms.) If you omit these variables, jobs will run for a period of 24 hours.
Collect Headers
We know that the Discover job, which we will run before the Collect job, will make a request to the Lacework API v2/access/tokens endpoint, and that the Lacework API’s response body will include an access token. That means that the access token will be available to the Collect job, to pass in a Collect header.
Create the two Collect headers specified in the table below. The first will convey the access token.
| Name | Value |
|---|---|
Authorization | `Bearer ${token}` |
Content-Type | 'application/json' |
Your Collect settings should look similar to this:
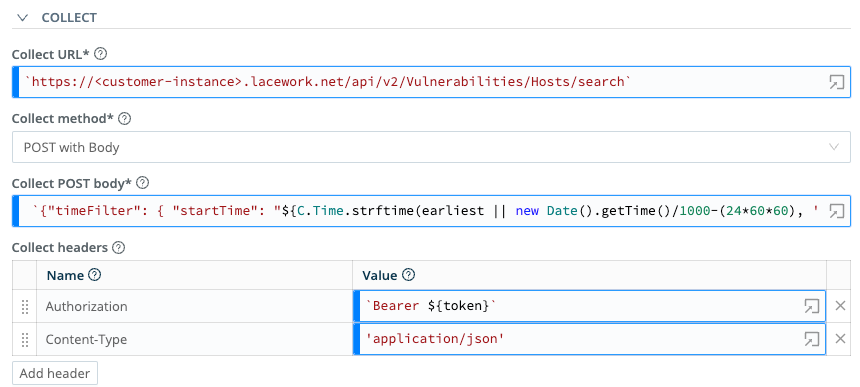
Pagination
From the Pagination drop-down, select Response Header Attribute. In the Response Attribute field, enter nextPage. This configures your Collector to work with the Lacework API response body, which includes nested fields of pagination metadata, such that urls contains nextPage, whose value is the Next Page URL.
You should see something like this:
The Lacework API authentication mechanism requires HTTP header parameters. Since Cribl Stream does not (currently) support header parameters for authentication, we cannot use that authentication method, and you should skip the Authentication settings. This is why we use the Discover job to obtain an access token, and then include that token in the Collect job.
Additional Settings
Tags: Optionally, add tags that you can use for filtering and grouping in Cribl Stream. Use a tab or hard return between (arbitrary) tag names.
Result Settings
Every call to the Lacework API v2/Vulnerabilities/Hosts/search endpoint returns data formatted as a single event. Every event contains multiple nested JSON arrays, where each array is a data element. We’ll now create an Event Breaker that parses the larger structure into individual events - one for each data element.
- From Cribl Stream’s top nav, select Processing > Knowledge.
- Click the Event Breaker Rules left tab. From the resulting Event Breaker Rulesets form, click New Ruleset to open the New Ruleset modal.
- Enter an ID for the new ruleset, and optionally add a Description and Tags.
- Click Add Rule.
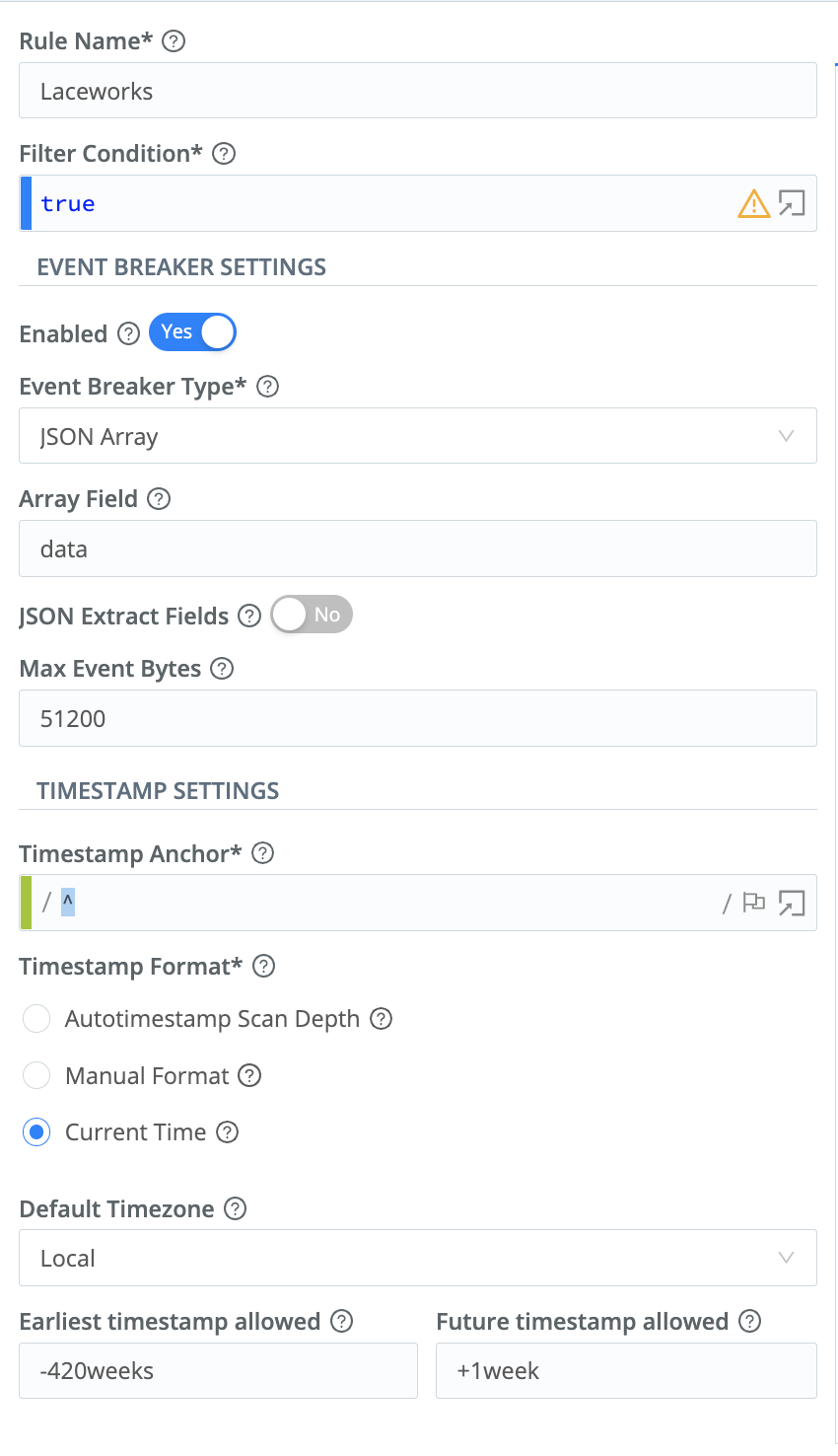
In the resulting Rules modal, name the Rule, and configure it as follows:
- Filter Condition: Enter
true. - Enabled: Toggle to
Yes. - Event Breaker Type: Select
JSON Array. - Array Field: Enter
data.
Optionally, you can use the Timestamp Settings to return events whose timestamp (_time) matches the startTime or endTime field defined in the Lacework data.
Click OK to return to the previous New Ruleset modal, then click Save.
Then return to your REST Collector’s configuration modal, and:
- Select the Result Settings > Event Breakers left tab.
- Under Event Breaker rulesets, click * Add ruleset**.
- From the drop-down that now appears above the System Default Rule, select your new ruleset.
- Click Save.
Discovering and Collecting
We’ll start with the Discovery run:
- On the Manage REST Collectors page, click Run beside your new Collector.
- In the resulting Run Collector modal, select Mode > Discovery.
- Configure a Time range, if desired.
- Click Run to retrieve Discovery results.
After inspecting these results, launch the Collector run:
- Back on the Manage REST Collectors page, again click Run beside your new Collector.
- In the resulting Run Collector modal, this time select Mode > Full Run.
- Configure a Time range, if desired.
- Click Run.
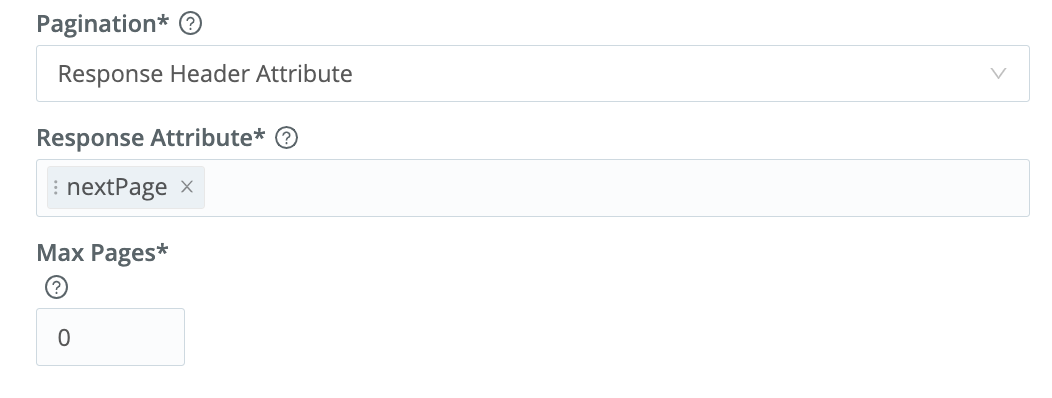
Once the Lacework API responds, you should see data similar to this: