



These docs are for Cribl Stream 4.8 and are no longer actively maintained.
See the latest version (4.17).
Amazon Security Lake Integration
Cribl Stream supports sending data to Amazon Security Lake as Parquet files that adhere to the Open Cybersecurity Schema Framework (OCSF). The diagram below illustrates the all-AWS variant of this architecture.
This guide walks you through an example where Cribl Stream, running in Cribl.Cloud, sends Palo Alto Networks logs to Amazon Security Lake. The workflow starts with a Cribl Stream Syslog Source, which ingests the Palo Alto data and routes it to a Cribl Stream Amazon Security Lake Destination, which then writes Parquet files to Amazon Security Lake. These Parquet files organize the data according to the OCSF schema for the appropriate OCSF Event Class, in this case Network Activity [4001].
You can work with other data sources besides Palo Alto Networks, and other OCSF Event Classes besides Network Activity [4001]. See Going Beyond This Example below.
If you want to use Amazon Security Lake with a Cribl Stream instance deployed on-prem or in your private cloud, the setup procedures will differ from those documented here. Please contact Cribl via the #packs channel of Cribl Community Slack.
Setting Up Amazon Security Lake
Complete the Amazon Security Lake Getting Started instructions, paying particular attention to the following actions:
- Enable Amazon Security Lake for your AWS account.
- Define the collection objective and target objective.
- Select the regions where you want to create S3 buckets to store the data in OCSF format.
Note your Amazon Security Lake S3 bucket name for use later in the setup process.
Setting Up Cribl Stream
Complete the procedures in this section before doing anything else in Cribl Stream.
First, find and note the Amazon Resource Name (ARN) that enables AWS to locate your Cribl Stream instance.
- Log in to Cribl.Cloud to open the Portal Page.
- In the top nav, click Network Settings and open the Trust tab.
- Click the copy icon next to the Worker ARN, and paste the ARN into a local text editor.
- Copy the 12-digit number in the middle of the ARN. This is the AWS Account ID you’ll need later in the setup process.
For example:
- If your ARN is
arn:aws:iam::222233334444:role/main-default, then … - Your AWS Account ID will be
222233334444.
Next, install the Cribl Pack that Cribl Stream will use to send data to Amazon Security Lake in the required OCSF format. (As the reference shows, the Palo Alto Networks data chosen for this example requires the OCSF Post Processor Pack.)
- In the top nav, click Cribl.Cloud to return to the Portal Page.
- Click Manage Stream or Manage Edge to open the Worker Groups page.
- Click the name of the Worker Group whose Worker Nodes you want to send data to Amazon Security Lake. (For this example, we’ll use the
defaultWorker Group.) This takes you to the Manage > Overview page. - Navigate to Processing > Packs and click Add Pack. From the drop-down, select Import from Git to open the Import modal.
- For the URL, enter:
https://github.com/asc-me-cribl/cribl_ocsf_postprocessing - For the New Pack ID, enter:
Cribl-OCSF_Post_Processor - Click Import to close the modal. Cribl Stream will take a little time to finish importing the Pack.
At the bottom of the list of Packs, you should now see your newly imported Pack, listed with the display name of OCSF Post Processor.
Finally, you will need the Parquet schema that supports the OCSF Event Class you’re working with. In this example, that’s OCSF Event Class 4001, so as shown in the reference below, you’ll need the OCSF 4001 Network Activity Parquet schema.
- First, download the Parquet schema from this GitHub repo.
- Then, upload the schema to the Cribl Stream Parquet schema library as described here.
Once this is done, the Parquet schema you need should be available when you configure the Parquet Settings for your Cribl Stream Amazon Security Lake Destination.
Please post any questions you have about these procedures to the #packs channel of Cribl Community Slack.
Creating an Amazon Security Lake Custom Source
Because Cribl is not a native Amazon service, you’ll configure what Amazon calls a Security Lake custom source, and the Cribl Stream Amazon Security Lake Destination will write to that.
Before you begin:
- Have your Cribl.Cloud AWS account ID, which you identified earlier, handy.
- Ensure that you have permissions in AWS Lake Formation to create AWS Glue databases and tables. For more information, see Granting and revoking permissions using the named resource method in the AWS docs.
Then complete the instructions here in the AWS docs. These docs will take you through the Create custom data source template show below.
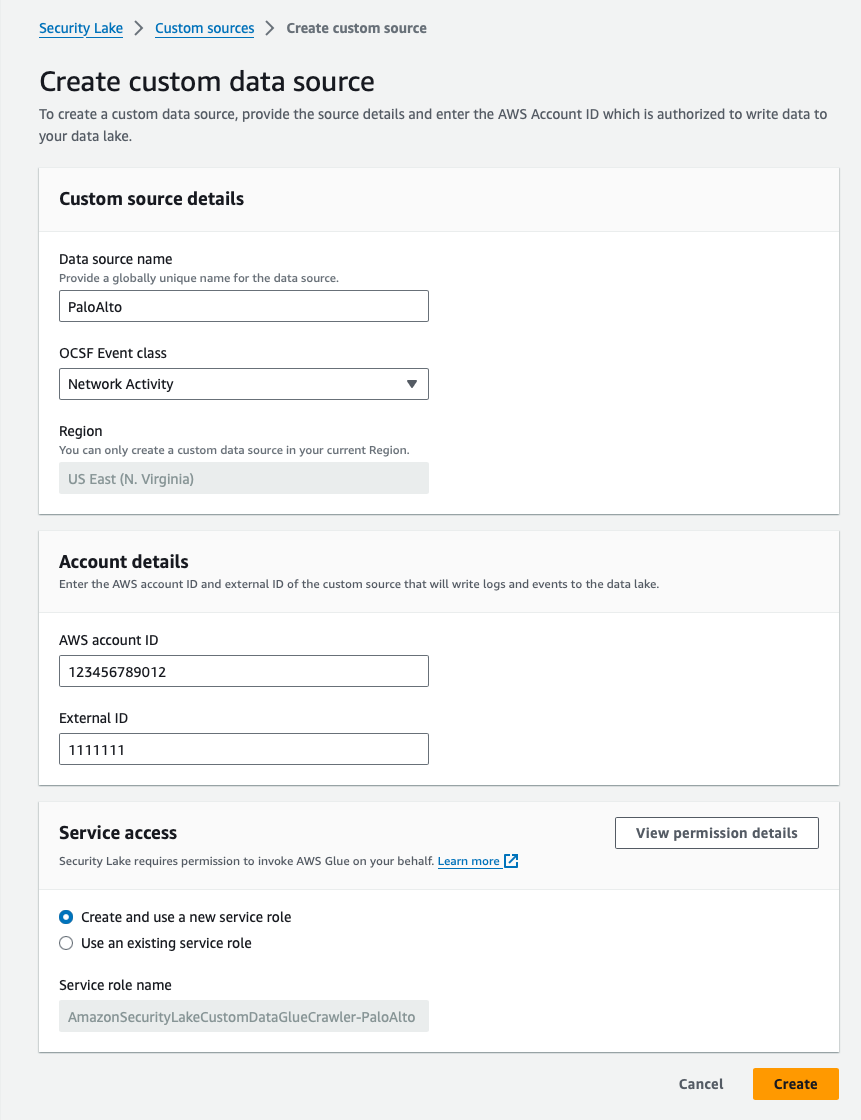
Once the custom source has been created, still in AWS, navigate to Security Lake > Custom sources and you should see your new custom source in the list.
Now locate the Provider role ARN. This is the ARN that Cribl Stream will use to declare its role to AWS.
- Click the copy icon next to the Provider role ARN to add it to your clipboard. Keep the ARN handy for use later in the setup process.
- Navigate to the Identity and Access Management (IAM) screen.
- From the left menu, select Access management > Roles.
- In the Roles search box, paste the part of the ARN that begins
AmazonSecurityLakeand ends with the region. - When the role name appears below, click the link.
- In the Trust relationships tab, view the
ExternalIdelement in the JSON object that appears there.
This is the External ID for the trust relationship, which you created when went through the template. You will need this ID later in the setup process.
Creating a Cribl Amazon Security Lake Destination
Back in Cribl Stream, create a new Amazon Security Lake Destination in the Routing UI as described in the Destination topic. In the New Destination modal, configure the settings specified below. For all settings not mentioned in the following notes, you can keep the defaults.
General Settings
S3 Bucket name: The S3 bucket name you noted when setting Up Amazon Security Lake.
Region: Select the region where the S3 bucket is located.
Optional Settings
File name prefix expression: Keep the default (CriblOut) if it satisfies your requirements; otherwise, edit to suit your needs.
Authentication
Authentication method must be set to Auto (the default).
Assume Role
Cribl strongly recommends using the Auto authentication method in conjunction with the Assume Role settings as described below. Both Cribl and Amazon discourage the use of other approaches.
When using Assume Role to access resources in a different region than Cribl Stream, you can target the AWS Security Token Service (STS) endpoint specific to that region by using the CRIBL_AWS_STS_REGION environment variable on your Worker Node. Setting an invalid region results in a fallback to the global STS endpoint.
AssumeRole ARN: This is the Provider role ARN you copied after creating your custom source in Amazon Security Lake.
External ID: Enter the ID that you specified when creating your Amazon Security Lake custom source.
Processing Settings
Post-Processing
Pipeline: From the drop-down, select the Pack you installed earlier:
PACK Cribl-OCSF_Post_Processor (OCSF Post Processor)System fields: Remove any fields specified here.
Parquet Settings
Parquet schema: From the drop-down select OCSF 4001 Network Activity, since OCSF Event Class 4001 describes the events coming from Palo Alto Networks in this example.
At this point, you can click Save; the defaults for Advanced Settings should work fine for this example. Then, Commit and Deploy.
You must create one Cribl Stream Amazon Security Lake Destination for each unique pairing of a data source with an OCSF Event Class.
- In this example, we’re ingesting Palo Alto Networks Threat and Traffic data, which requires the OCSF Network Activity [4001] Event Class. That’s one pairing.
- If you also wanted to ingest CrowdStrike Network Activity data, that would be a new data source paired with the same OCSF Event Class - such as, that would be a second unique pairing. You would need to create a separate Cribl Stream Amazon Security Lake Destination for that pairing.
The reference below shows all the possible pairings of data sources and OCSF Event Classes.
Connecting a Cribl Source to the S3 Destination
We’ll now configure a Cribl Stream Syslog Source to ingest Palo Alto Networks system logs, using the QuickConnect UI. (The reference below shows what Cribl Stream Source to use for each supported data source.)
Navigate to QuickConnect as described here. After clicking the Syslog Source tile, click Select Existing, then click the preconfigured in_syslog Source. When prompted to Switch in_syslog to send to QuickConnect instead of Routes?, click Yes.
Click + and drag the connection line to the S3 Destination you created above.
The connection between the Syslog Source and the S3 Destination should now be enabled.
Commit and Deploy the changes.
Sending Data to Amazon Security Lake
Return to your AWS Console. You should see Parquet files landing in the S3 bucket. These files should contain the Palo Alto Networks syslog data you sent through Cribl Stream.
Troubleshooting and Testing
Good things to double-check:
- Are you sending the events to your Amazon Security Lake in Parquet format?
- Are your permissions set properly for your IAM role to write to the S3 bucket?
If the answer to either question is “No,” your data will not make it into Amazon Security Lake.
To send sample events from the GitHub repo, using netcat:
- Download the
oYLbFU.jsonsample file. - Run the following command, replacing
<cribl_org_id>with your Cribl.Cloud Organization ID:
cat oYLbFU.json | nc default.main.<cribl_org_id>.cribl.cloud 10070With a Cribl.Cloud Enterprise plan, generalize the above URL’s
default.mainsubstring to<group-name>.mainwhen sending to other Worker Groups.
Going Beyond This Example
If you want to send data from sources other than Palo Alto Networks, you can adapt the above instructions to use the appropriate Source and Pack (and/or modifications to the OCSF Post Processor Pack) in Cribl Stream. This holds true as long as the OCSF Event Classes you want to work with are among those supported by Cribl Stream. For each unique pairing of a data source with an OCSF Event Class, you’ll need to create a separate Amazon Security Lake Destination.
In the next section is a list of the supported data sources, what OCSF Event Classes they handle, and what Packs and Parquet schemas you need to work with them.
Reference: Supported Data Sources
| Data Source | OCSF Event Classes Handled | Cribl Source | Cribl Pack Display Name | Parquet Schema(s) |
|---|---|---|---|---|
| Azure Audit Logs | 3002, 3004 | REST Collector against Microsoft Graph API | Azure Audit Logs to OCSF | OCSF 3002 AuthenticationOCSF 3004 Entity Management |
| Azure NSG Flow Logs | 4001 | Azure Blob Storage Source, run as scheduled jobs, not as a Pull Source | Azure NSG Flow Logs | OCSF 4001 Network Activity |
| Cisco ASA | 4001 | Syslog | Cisco ASA | OCSF 4001 Network Activity |
| Cisco FTD | 4001 | Syslog | Cisco FTD | OCSF 4001 Network Activity |
| CrowdStrike Account Change | 3001 | CrowdStrike FDR | Crowdstrike FDR Pack | OCSF 3001 Account Change |
| CrowdStrike Authentication | 3002 | CrowdStrike FDR | Crowdstrike FDR Pack | OCSF 3002 Authentication |
| CrowdStrike Network Activity | 4001 | CrowdStrike FDR | Crowdstrike FDR Pack | OCSF 4001 Network Activity |
| GCP Audit Logs Account Activity | 3001 | Google Cloud Pub/Sub | Google Cloud Audit Logs | OCSF 3001 Account Change |
| Palo Alto Networks (PAN) Threat and Traffic | 4001 | Syslog | OCSF Post Processor Pack | OCSF 4001 Network Activity |
| SentinelOne | 1001, 2001, 3002, 4001 | Amazon S3 | SentinelOne Cloud Funnel | OCSF 1001 File System ActivityOCSF 2001 Security FindingOCSF 3002 AuthenticationOCSF 4001 Network Activity |
| Windows Logon Activity | 3002 | Splunk TCP | Splunk Forwarder Windows Classic Events to OCSF | OCSF 3002 Authentication |
| ZScaler Firewall and Weblogs | 4001 | Syslog | OCSF Post Processor Pack | OCSF 4001 Network Activity |