



These docs are for Cribl Stream 4.9 and are no longer actively maintained.
See the latest version (4.17).
Multiple Agents Reference Architecture
This reference architecture shows one Cribl Stream deployment possibility for ingesting data from a large quantity of agents. Here, a single basic configuration is replicated across multiple Worker Groups, organized by geographic location.
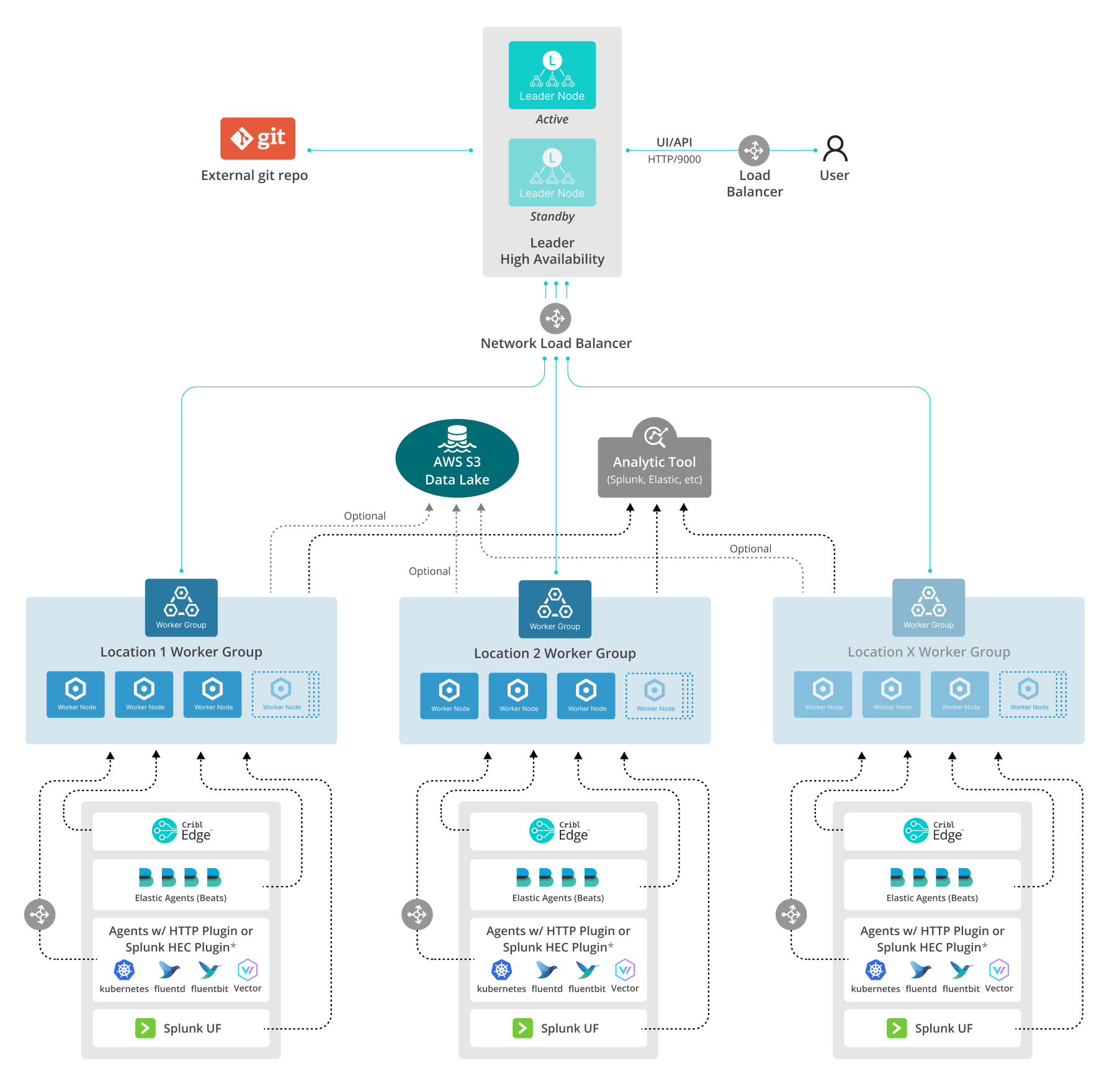
Download an editable version of this diagram in SVG or draw.io format. Download Cribl stencils here.
Single or Multiple Worker Groups?
The multiple-Groups architecture shown here is one approach. It might or might not be desirable for your use case.
Pros of using multiple Worker Groups:
- Configuration granularity.
- Can use Packs to export/reuse configurations across Groups.
Cons of using multiple Worker Groups:
- Multiple configurations to maintain (even if shared via Packs).
General Sizing Considerations
Size based on data throughput (in+out), and on number of incoming TCP connections.
Sizing Examples
Below are two scenarios demonstrating how to determine the number of Stream Worker Processes you’ll need to allocate. Both scenarios assume the same distribution of chatty versus medium-chatty agents, but with a different balance of throughput volume versus agents volume.
How Many Events per Second?
We assume three tiers of “chatty” agents, based on events per second. You’ll probably recognize your senders from these definitions:
- Chatty agents (100 EPS/agent) - Size 150 agents/vCPU. (Examples are domain controllers or intermediary agents.)
- Medium-chatty agents (30 EPS/agent) - Size 250 agents/vCPU. (Most servers will fall into this medium category.)
- Low-volume agents (3 EPS/agent) - Size 5000 agents/vCPU (Examples are workstations.)
For the most accurate sizing, obtain EPS reports from your current observability tools.
Using the Scenarios
In each scenario, to size based on the number of agents directly feeding Cribl Stream, take the largest vCPU count from the pair of volume versus ports calculations.
Scenario 1
40 TB/day throughput, 40,000 agents, 10% of them very chatty, 90% medium-chatty.
- Sizing for volume (non-hyperthreaded CPU cores): 205 Worker Processes.
- Sizing from TCP ports (non-hyperthreaded CPU cores): (0.10 x 40,000 / 150) + (0.90 x 40,000 / 250) = (27 + 144) = 171.
- Result: Allocate 205 Worker Processes, the larger of the two.
Scenario 2
4 TB/day throughput, 20,000 agents, 10% of them very chatty, 90% medium-chatty.
- Sizing from vCPUs (non hyperthreaded CPU Cores): 11 Worker Processes.
- Sizing from TCP ports (non-hyperthreaded CPU Cores): (0.10 x 20,000 / 150) + (0.90 * 20,000 / 250) = (14 + 72) = 86.
- Result: Allocate 86 Worker Processes, the larger of the two.
Cribl Edge Configuration
You can configure Cribl Edge to send data to Cribl Stream via a Cribl HTTP, Cribl TCP, or TCP JSON Destination.
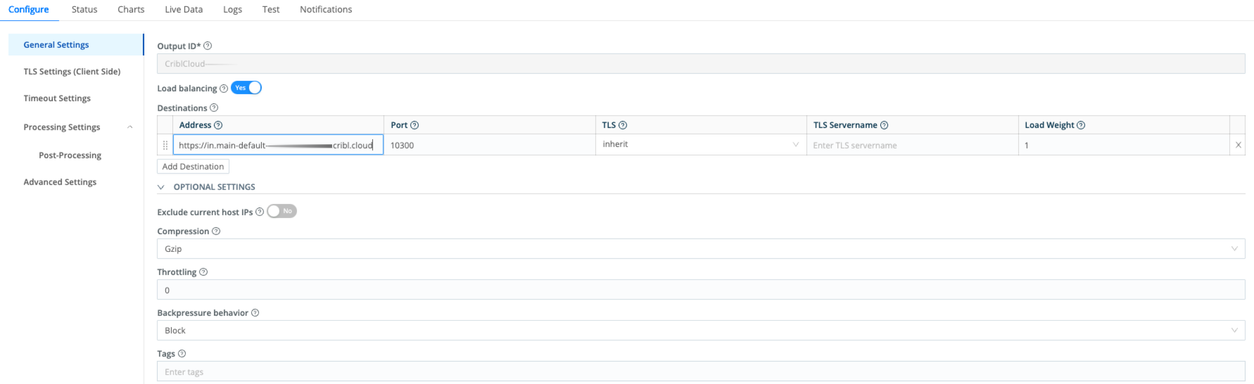
Cribl HTTP is ideal for environments where the Edge Nodes and the Cribl Stream Workers are managed by the same Leader. Cribl HTTP is particularly well-suited to scenarios where the data must traverse a proxy. (The proxy will reduce throughput performance, so monitor throughput when traversing a proxy.) You should always enable this Destination’s load-balancing option. When you use a Cribl HTTP Destination/Source pair to connect the applications, license metering occurs only when the data is collected by the Edge Node, so you are billed only once.
Cribl TCP is also available for environments where the Edge Nodes and the Cribl Workers are managed by the same Leader. Its limitation is vulnerability to “pinning” on persistent connections. When you use this Destination, you should always enable its load-balancing option. With Cribl TCP, as with Cribl HTTP, license metering occurs only when the data is collected by the Edge Node, so you are billed only once.
TCP JSON is ideal for environments where the Edge Nodes are managed by a different Leader than the Cribl Stream Workers. Neither Cribl HTTP nor Cribl TCP will work in this scenario. You should always enable this Destination’s load-balancing option.
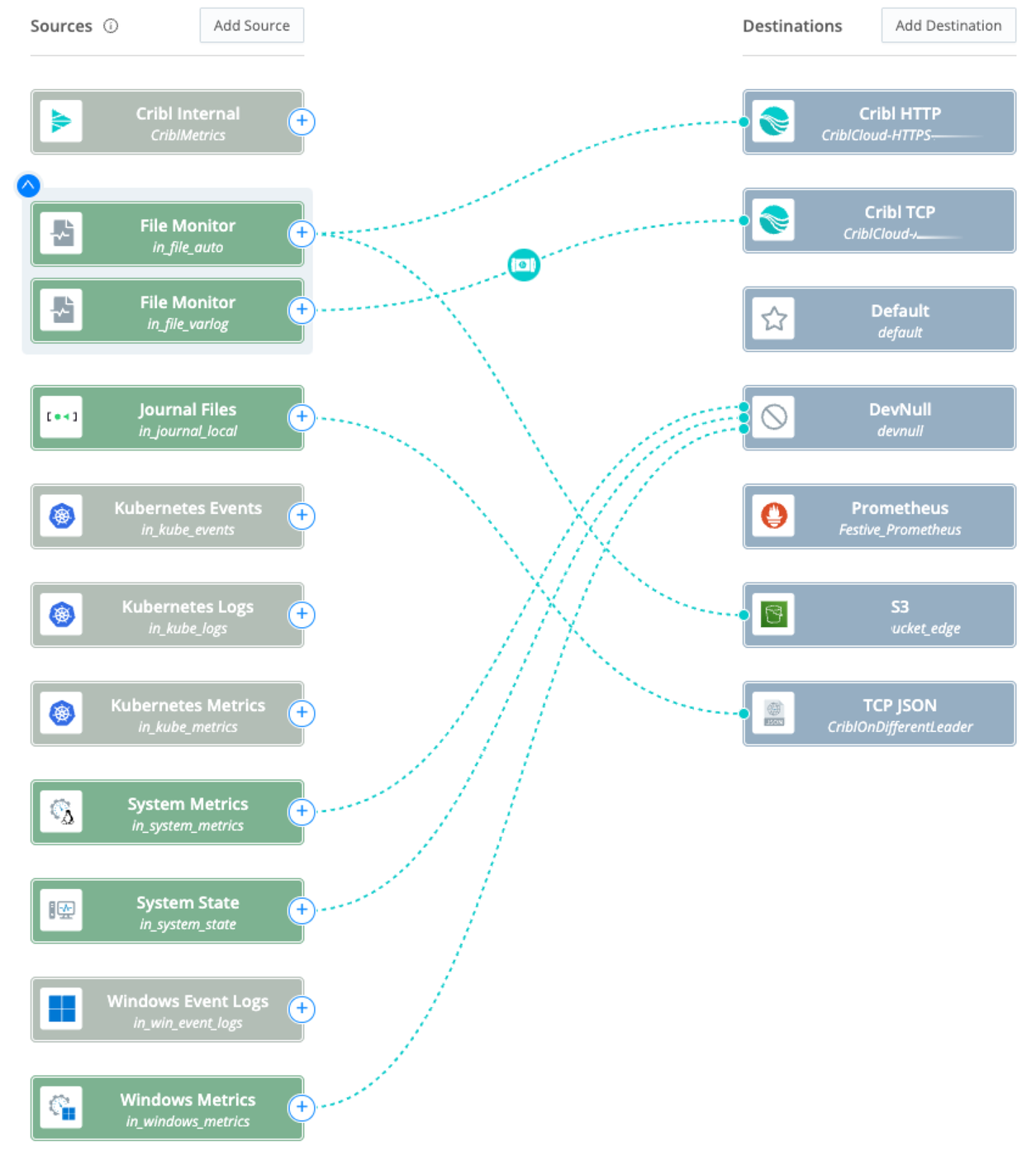
Elastic Agent Configuration
The configuration to use in filebeat.yml depends on your agent’s version.
Versions 8.x+
setup.ilm.enabled: falseVersions 7.15 Through 7.17
output.elasticsearch:
hosts: ["https://<your-host-here>.com:9200/elastic"]Or:
output.elasticsearch:
hosts: ["<server-name-here>:9200/elastic", "<another-server-name-here>:9200/elastic"]Versions 7.14 and Earlier
output.elasticsearch:
hosts: ["https://<your-host-here>.com:9200"]Or:
output.elasticsearch:
hosts: ["<server-name-here>:9200", "<another-server-name-here>:9200"]Configure the agent’s worker setting to avoid TCP pinning. See the worker configuration option in
Configure the Elasticsearch Output.
Splunk Forwarder Configuration
Here are configurations for a few different scenarios.
Setting
blockOnCloningtofalseensures that if either Cribl Stream or Splunk becomes unavailable, the other system will continue receiving data without dropping events. This prevents potential data loss or interruptions in transmission.
Send All Data to Cribl Stream
Default outputs.conf to forward all inputs to the stream servers:
[tcpout]
defaultGroup=stream
blockOnCloning=false
[tcpout:stream]
server=10.1.1.200:9997,10.1.1.201:9997
sendCookedData=true
blockOnCloning=falseSend to Splunk and Cribl Stream
This outputs.conf bifurcates all data to both Splunk and Cribl, by configuring defaultGroup with two tcpout values.
[tcpout]
defaultGroup=splunk,stream
blockOnCloning=false
[tcpout:splunk]
server=10.1.1.197:9997,10.1.1.198:9997
blockOnCloning=false
[tcpout:stream]
server=10.1.1.200:9997,10.1.1.201:9997
sendCookedData=true
blockOnCloning=falseBypass Internal Logs
The Splunk Universal Forwarder will send the splunkd.log and metrics.log sources to any configured tcpout stanza. This is because both monitor stanzas have _TCP_ROUTING = *. In certain scenarios, it’s desirable for the internal logs to bypass Cribl Stream, sending them directly to Splunk.
For example:
┌────┐
│ UF ├───_internal───┐
└──┬─┘ ┌───▼────┐
│ │ Splunk │
│ ┌───────┐ └───▲────┘
└─►│ Cribl ├──────┘
└───────┘ In this scenario, configure your settings as follows.
outputs.conf:
[tcpout]
defaultGroup=stream
blockOnCloning=false
[tcpout:splunk]
server=10.1.1.197:9997,10.1.1.198:9997
blockOnCloning=false
[tcpout:stream]
server=10.1.1.200:9997,10.1.1.201:9997
sendCookedData=true
blockOnCloning=falseinputs.conf for internal logs:
# splunkd.log and metrics.log will get sent to Splunk
[monitor://$SPLUNK_HOME/var/log/splunk/splunkd.log]
_TCP_ROUTING = splunk
[monitor://$SPLUNK_HOME/var/log/splunk/metrics.log]
_TCP_ROUTING = splunkinputs.conf for all other logs:
# datasource.log will get sent to Cribl by default
[monitor:/path/to/log/datasource.log]
index = ds_index
sourcetype = sourcetypeFluent Bit Configuration
Here are sample configurations for three different ways to ingest Fluent Bit data.
Splunk HEC Source on Cribl Workers
[OUTPUT]
Name cribl
Match *
host <HOST>
port 8088
Cribl_HEC_Token xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx
Cribl_HEC_Send_Raw On #optional: to raw instead of event endpoint
TLS On
TLS.Verify Off #optionalRaw HTTP Source on Cribl Workers
[OUTPUT]
Name http
Match *
Host cribl_worker_load_balanced_vip
Port 10443
URI /optional/uri/for/filtering/in/cribl
Format json_lines
Header Authorization <Cribl-generated token>
Header X-Key-B Value_BTCP JSON Source on Cribl Workers
[OUTPUT]
Name tcp
Format json_lines
Workers 2
tls on #optional for tls setting
json_date_key date
json_date_format epoch
# Note: Use mTLS, because this plugin doesn't appear to support authTokensCribl Destination Considerations
Adjust Cribl Destinations’ Advanced Settings > Max connections setting (where available) to limit the load on receivers. E.g.: For a Splunk Load Balanced Destination, if you have 5 Worker Groups sending data to the same Splunk indexer cluster, with 25 indexers, set Max connections to between 5-10.
Load Balancers
The load balancer in front of the Leader UI can be an Application Load Balancer or a Network Load Balancer.
The load balancer between the Cribl Workers and the Cribl Leader listening on port 4200 must be a Network Load Balancer or equivalent.
Leader High Availability
Configuring Leader high availability requires a standby server, a load balancer (details here) between users and the Cribl UI port, and a Network Load Balancer between the Cribl Leader and Workers.
Leader high availability is optional. Many customers opt instead for a single Leader, and a remote Git repo for scheduled backups. If the Leader becomes unavailable, you can use the Git repo to provision a new Leader, restoring configuration from a backup.
However, a single Leader is reliable only when Workers are running Cribl Sources that fully leverage a shared-nothing architecture (such as Raw HTTP, Splunk HEC, Elasticsearch API, Amazon S3 Source, etc). Here, Workers can process data even if the Leader is unavailable. A Leader without failover will not reliably support Collectors, which require a Leader’s ongoing orchestration.
Disclaimers
All product names, logos, brands, trademarks, registered trademarks, and other marks listed in this document are the property of their respective owners. All such marks are provided for identification and informational purposes only. The use of these marks does not indicate affiliation, endorsement, or ownership of the marks or their respective owners.
This document is provided “as is” with NO EXPRESS OR IMPLIED WARRANTIES OR REPRESENTATIONS. It is intended to aid users in displaying system architecture, but might not be applicable or appropriate in all circumstances. You should not act on any information provided until you have formed your own opinion through investigation and research. Cribl is not responsible for any use of this document or the information provided herein.