



Onboard Data
Onboarding data into Cribl Stream can vary in complexity, depending on your organization’s needs, requirements, and constraints. Proper onboarding from all Sources is key to system performance, troubleshooting, and ultimately the quality of data and decisions both in Cribl Stream and in downstream Destinations.
General Onboarding Steps
Typically, a data onboarding process revolves around these steps, both before and after turning on the Source:
- Create configuration settings.
- Verify that settings do the right thing.
- Iterate.
Below, we break down individual steps.
Before Turning On the Source
Cribl recommends that you take the following steps to verify and tune incoming data, before it starts flowing.
Preview Sample Data
Use a sample of your real data in Data Preview. Sample data can come from a sample Source file that you upload or paste into Cribl Stream.
You can also obtain sample data in a live data capture from a Source. One way to do this before going to production is to configure your Source with a devnull Pipeline (which just drops all events) as a pre-processing Pipeline. Then, let data flow in for just long enough to capture a sufficient sample.
Very Large Integer Values
Cribl Stream’s JavaScript implementation can safely represent integers only up to the Number.MAX_SAFE_INTEGER constant of about 9 quadrillion (precisely, {2^53}-1). Data Preview will round down any integer larger than this, and trailing 0’s might indicate such rounding down.
Check the Processing Order
While events can be processed almost arbitrarily by Functions in Cribl Stream Pipelines, make sure you understand the event processing order. This is very important, as it tells you exactly where certain processing steps occur. For instance, as we’ll see just below, quite a few steps can be accomplished at the Source level, before data even hits Cribl Stream Routes.
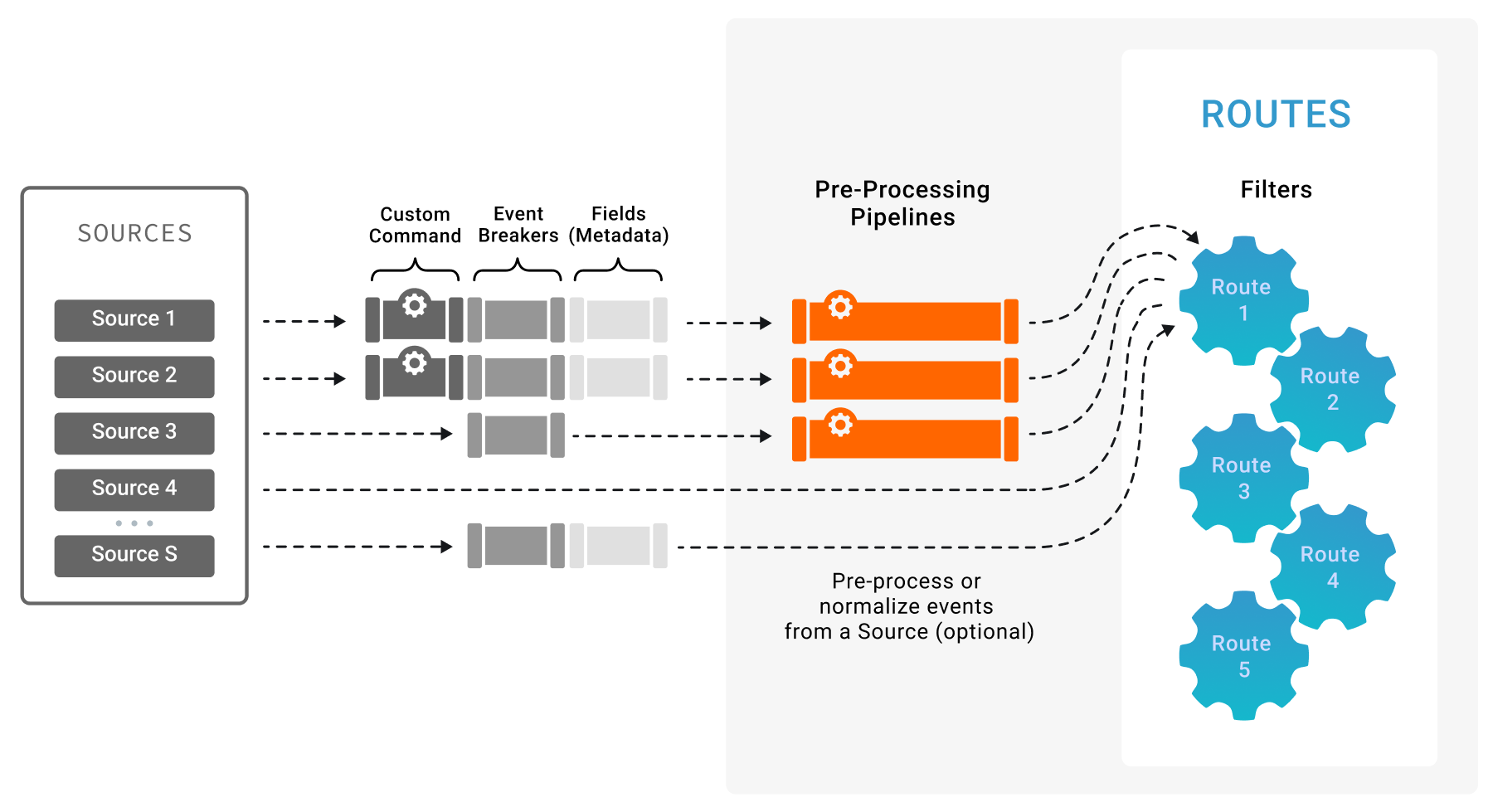
Custom Command
Where supported, data streams will be handled by custom commands. These are external system commands that can (optionally) be used to pre-process the data. You can specify any command, script, etc., that consumes via stdin and outputs via stdout.
Verify that such commands are doing what’s expected, as they are the very first in a series of processing steps.
Event Breakers
Next, data streams are handled by Event Breakers, which:
- Convert data streams into discrete events.
- Extract and assign timestamps to each event.
If the resulting events do not look correct, feel free to use non-default breaking rules and timestamp recognition patterns. Downstream, you can use the Auto Timestamp Function to modify _time as needed, if timestamps were not recognized properly. Examples of such errors are:
- Timestamps too far out in the future or past
- Wrong timezone.
- Incorrect timestamp is selected from multiple timestamps present in the event.
Fields
Next, events can be enriched with Fields . This is where you’d add static or dynamic fields to all events delivered by a particular Source.
Pre-Processing Pipeline
Next, you can optionally configure a pre-processing Pipeline on a particular Source. This is extremely useful in these cases:
- Drop non-useful events as early as possible (so as to save on CPU processing).
- Normalize events from this Source to conform a certain shape or structure.
- Fix/touch up events accordingly. E.g., if event breakers assigned the wrong timestamp, this is the best place to use the Auto Timestamp Function to adjust
_time.
We Can’t Say This Enough
Verify, verify, verify, data integrity before turning on the Source.
After Turning On the Source
Use data Destinations to verify that certain metrics of interest are accurate. This will depend significantly on the capabilities of each Destination, but here’s a basic checklist of things to ensure:
- Timestamps are correct.
- All necessary fields are assigned to events.
- All expected events show up correctly. (E.g., if a Drop or Suppress Function was configured, ensure that it’s not dropping unintended events.)
- Throughput - both in bytes and in events per second (EPS) - is what’s expected, or is within a certain tolerance.
Iterate
Iterate on the steps above as necessary. E.g., adjust fields values and timestamps as needed.
Remember that there is almost always a workaround. Any arbitrary event transformation that you need is likely just a Function or two away.