



Packs
Packs enable Cribl Stream administrators and developers to pack up and share complex configurations and workflows across multiple Worker Groups, or across organizations.
This page is a general reference for Packs. For more information about specific use cases for Packs, see:
- Onboard Faster With Packs for information about using Packs from the Cribl Dispensary.
- Pack-Based Configuration Management for information about using Packs to templatize your entire end-to-end Cribl deployment into a single, portable, reusable unit.
- Packs Publication Standards for community guidelines about contributing a Pack to the Cribl Dispensary.
Get Packs
You can add Packs to your deployment by importing them from:
Pack Naming on Import
Each Pack that you install within a given Worker Group (or Single-instance deployment) must have a unique ID. The ID is based on the internal configuration of the Pack - not its container file name, nor on its Display name.
If you import a Pack whose internal ID matches an installed Pack - whether an update, or just a duplicate - you can choose one of two options:
- Assign a unique New Pack ID. This will import the Pack as a new, separate Pack with the new ID.
- Toggle Overwrite on to overwrite the installed Pack, reusing the same ID.
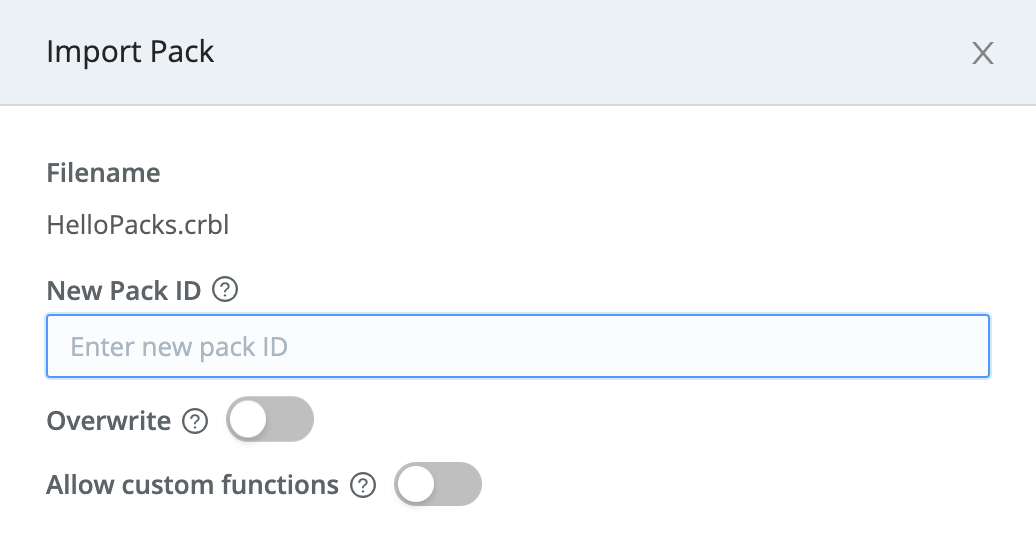
Be careful about enabling the Overwrite option. Doing so will cause the imported Pack to completely overwrite your existing Pack configuration.
Each Pack within a Worker Group must have a unique Pack ID, so you cannot share an ID between two (or more) installed Packs.
Add From Dispensary
See Onboard Faster With Packs for more information about using Packs from the Cribl Dispensary.
Import from a File
To import a Pack (.crbl file) from your local filesystem:
- Navigate to the Packs page.
- Select Add Pack at the upper right and select Import from File.
- Select the file to import.
- Optionally, give the Pack an explicit, unique New Pack ID. (For details about this option, see Upgrade an Existing Pack.)
- Select Import to confirm the import.
- If the Pack you are importing binds variables to any fields, you will see a Configure Variables button in the notification about successful import. Select it to go to the Variables page, where you can configure the values for the variables for your deployment.
Import from a URL
To import a Pack from a known, public or internal, URL:
- Navigate to the Packs page.
- Select Add Pack at the upper right and select Import from URL.
- Enter a valid URL for the Pack’s source. (This field’s input is validated for URL format, but not for accuracy, before you submit the modal.)
- Optionally, give the Pack an explicit, unique New Pack ID. (See Upgrade an Existing Pack.)
- Select Import to confirm the import.
- If the Pack you are importing binds variables to any fields, you will see a Configure Variables button in the notification about successful import. Select it to go to the Variables page, where you can configure the values for the variables for your deployment.
To import a Pack from a public URL, the Leader Node (or single instance) requires internet access. A Distributed deployment Leader can then deploy the Pack to Workers even if the Workers lack internet access.
Import from Git Repos
When you import a Pack from a private Git repository using a personal access token, you can also push changes back to the same branch or repository you imported from. If you don’t provide an access token, Cribl Stream cannot write back to the repository. This means you won’t be able to push changes to a repository without authenticating with a personal access token.
Some additional considerations:
- If you don’t specify a branch during import, Cribl Stream assumes you want to use the repository’s default branch.
- You cannot push changes to a Git tag. Importing from a tag is allowed, but writeback is only supported when importing from a branch.
- If you need to change the token used for Git operations, you’ll need to re-import the Pack using the new token.
To import a Pack from a known public or private Git repo:
Navigate to the Packs page.
Select Add Pack at the upper right and select Import from Git.
Enter the source repo’s valid URL.
This field’s input is validated for URL format, but not for completeness or accuracy, before you submit the modal. When targeting a private repo, use the format:https://<username>:<token/password>@<repo-address>. Public repos need onlyhttps://<repo-address>, as shown in the following example.Optionally, give the Pack an explicit, unique New Pack ID. (See Upgrade an Existing Pack.)
Optionally, enter a Branch or tag to filter the import source using the repo’s metadata. You can specify a branch (such as
master) or a tag (such as a release number:0.5.1, and so forth).Select Import to confirm the import.
If the Pack you are importing binds variables to any fields, you will see a Configure Variables button in the notification about successful import. Select it to go to the Variables page, where you can configure the values for the variables for your deployment.
To import a Pack from a public repo, the Leader Node (or single instance) requires internet access. A Leader in a Distributed deployment can then deploy the Pack to Workers even if the Workers lack internet access.
Prepare Pack for Use
After you have imported a Pack, take the following steps to ensure it is ready for use on your Worker Nodes:
Verify secrets: If the Pack was exported in
mergemode, any encrypted fields will have been removed for security. You must re-enter your secrets in the imported Pack to ensure it works as expected.Configure variables: If you did not configure values for a Pack variable during import, you can do it later by navigating to Knowledge > Variables in the imported Pack.
Commit and Deploy: If your Pack includes Collectors and jobs, you must Commit and Deploy it after import. This step is critical because it ensures your Worker Nodes have the correct Pack context to successfully run jobs.
Use Packs
Version Compatibility
Packs created or modified in Cribl Stream 4.0.x cannot be used in any Cribl Stream version older than 4.0. (If you try, you’ll see a
should NOT have additional propertieserror.) To avoid this problem, Cribl recommends that you upgrade to Cribl Stream 4.0.x or newer.For compatibility questions about any individual Packs, please contact us in the Cribl Community Slack
#packschannel.
For Packs that do not contain Sources or Destinations, you can use them in all places where you can reference a Pipeline:
- In Sources, where you attach pre-processing Pipelines.
- In Destinations, where you attach post-processing Pipelines.
- In Routes, in the Routing table’s Pipeline and Destination columns.
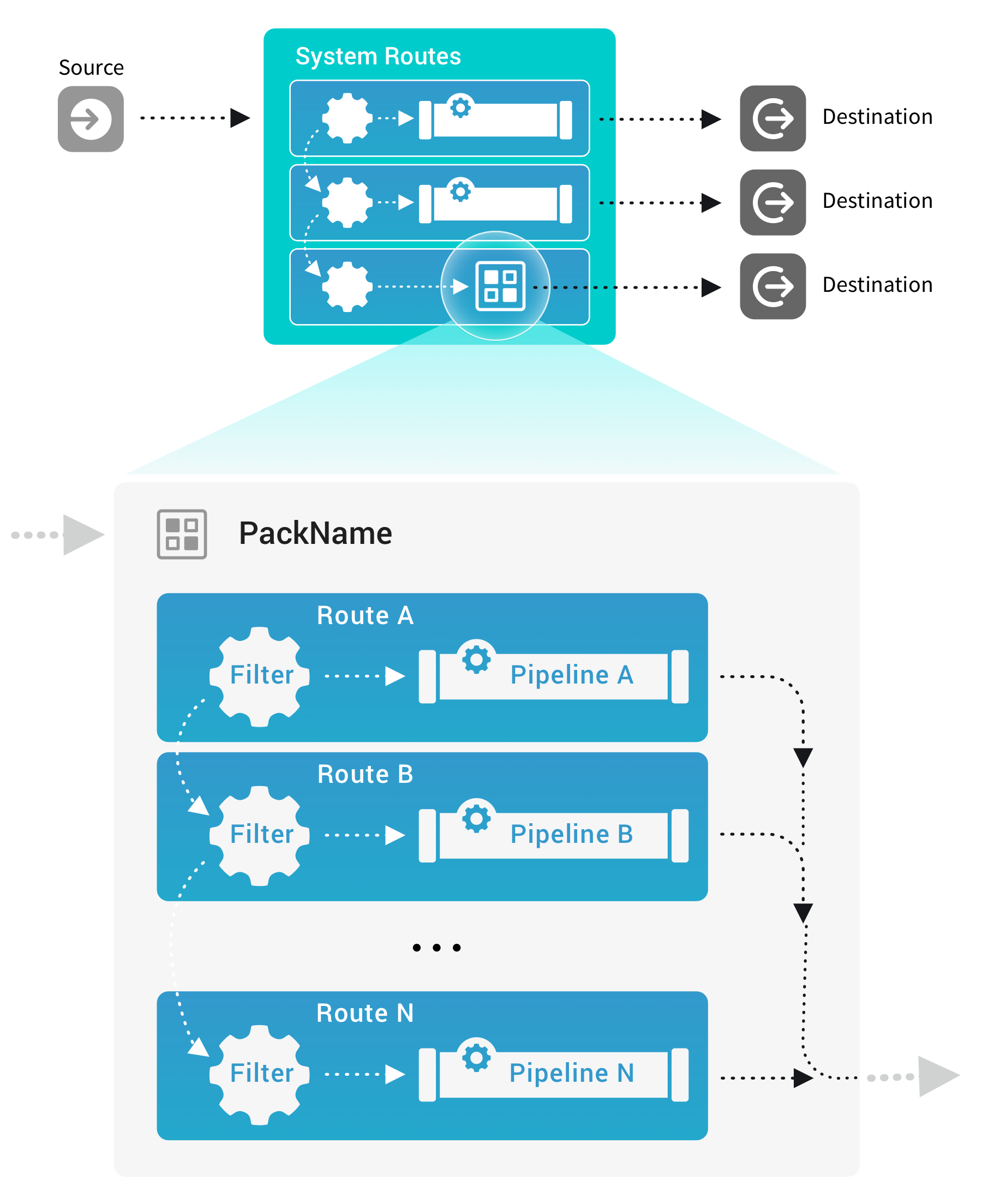
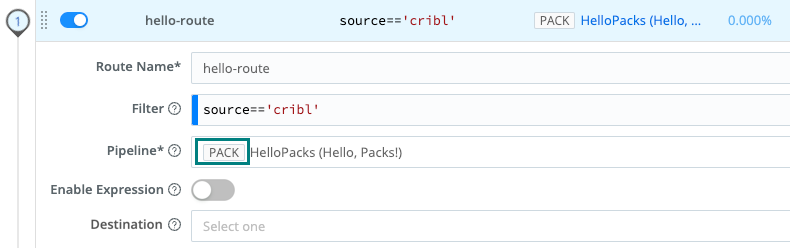
This expanded view shows how a Pack can replace a Pipeline in a Route:
Packs are distinguished in the display with a PACK badge, as you can see here in the Routing table:
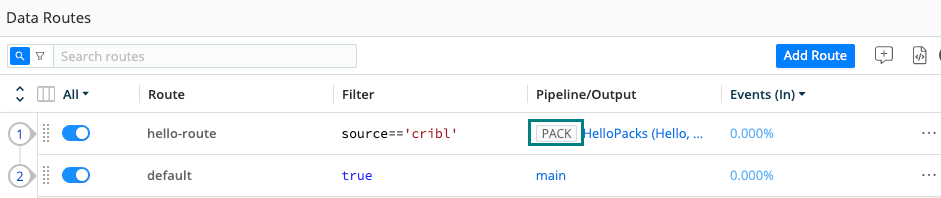
The PACK badge is also displayed when you click into a resource - shown here on one of the Routes from the above table:
Cribl Stream’s Monitoring page includes a Packs link where you can monitor the throughput of a Pack.
Access Packs
You access Packs differently, depending on your deployment type.
Single-Instance Deployment
In a Single-instance deployment, Packs are global. On the top bar, select Processing > Packs. On the filesystem, Packs (including those that you add) are stored at $CRIBL_HOME/default/.
Distributed Deployment
In a Distributed deployment, Packs are associated with (and installed within) Worker Groups. In the sidebar, select Worker Groups, and then select the Worker Group you want to manage. Next, from that Worker Group’ submenu, select Processing > Packs (Stream) or More > Packs (Edge).
Each Group’s Packs are stored at $CRIBL_HOME/groups/<groupName>/default/.
By design, you can readily share Packs across Worker Groups by copying them between Groups.
Use Sample Data
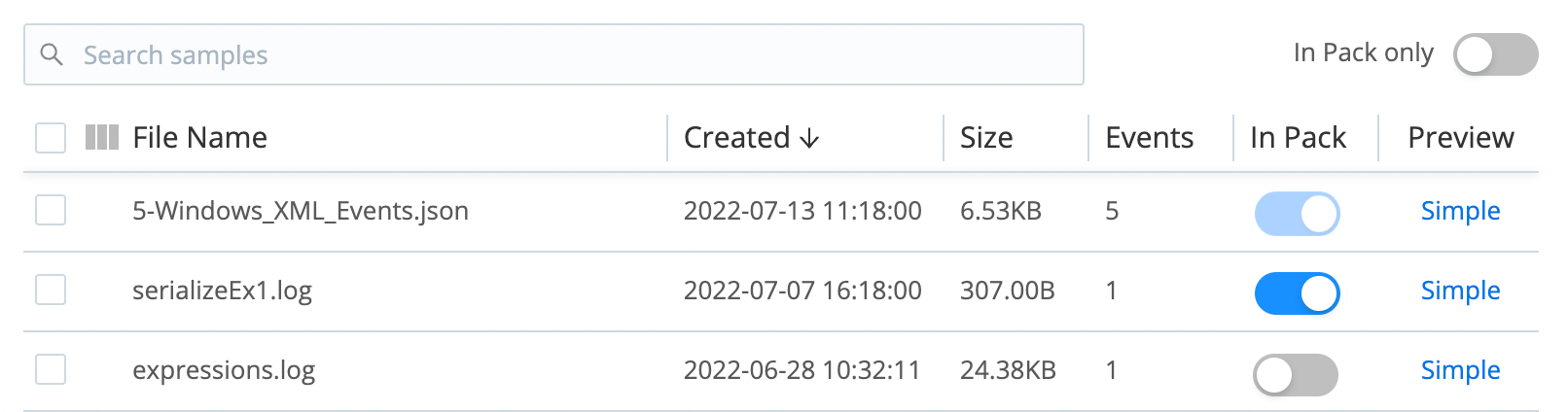
Within a Pack, the right pane defaults to displaying all sample data files available on your Cribl Stream instance. If you prefer to filter only sample files internal to the Pack, select the In Pack only option.
If you add sample data files via a Pack UI, they will be internal to that Pack. Each sample file here displays its own In Pack toggle on its row, which works as follows:
A light-blue toggle is locked, meaning that this sample file is internal to the Pack. It will export with the Pack. If you want to make this sample available across Cribl Stream, you’ll need to also add it via the global right preview pane (accessed from Routing > Data Routes or Processing > Pipelines).
The toggle indicates whether the sample file is global to Cribl Stream and available to this Pack. Toggle on if you want the sample file to export along with the Pack.
Basically, you can manipulate all the options here as you would work with the equivalent options in the global navigation.
Upgrade an Existing Pack
To upgrade an existing Pack, open the Options ••• menu on its row, and then select Upgrade.
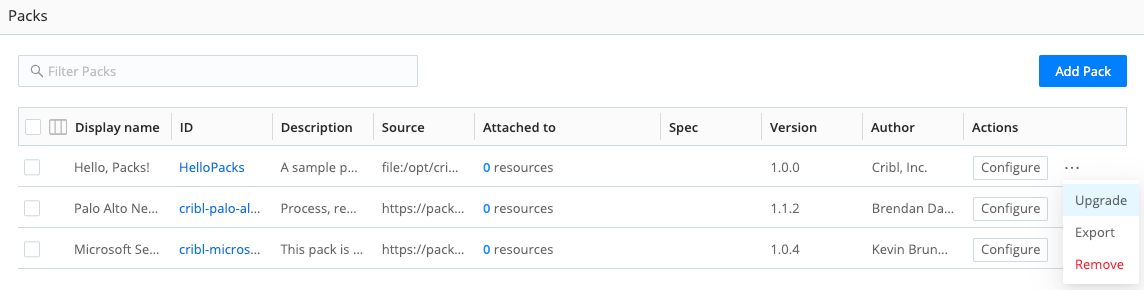
If you’ve modified an installed Pack, Cribl Stream will block the overwrite of the Pack, to prevent deletion of your locally created resources.
When upgrading a Pack, Cribl recommends that you:
- Import the updated Pack under a new name that includes the version number (for example,
cribl-syslog-input-120). This allows you to review and adjust new functionality against currently-deployed configurations. - Do a side-by-side comparison of the previous and new versions of the Pack - remember to review all comments in the new Pack. Doing this side-by-side comparison allows you to copy Function expressions and other settings from the current version into the same fields in the new version.
- Enable or disable any Functions in the new Pack as necessary.
- Update any Routes, Pipelines, Sources, or Destinations that use the previous Pack version to reference the new Pack.
- If the Pack includes any user-modified versions of default Cribl Stream Knowledge objects (for example, lookup files): Be sure to copy the modified files locally for safekeeping, before upgrading the Pack. After you install the upgrade, copy those files back to the upgraded Pack, overwriting the default versions in the Pack.
- Test, test, and test!
- Commit and Deploy.
Copy a Pack
You can share Packs in a Distributed deployment by copying the Packs between Worker Groups. You can copy one or more Packs from the Packs page as described here or using the Cribl API.
To copy a single Pack, your first step is to open its Options ••• menu, then select Copy to another Worker Group.
To copy multiple Packs in one operation:
Select the check boxes for all Packs you want to copy on the Packs page.
In the options ••• menu, select Copy selected Packs to another Worker Group.
Select the Worker Groups to which you want to copy the Pack.
Optionally, select the Overwrite option to replace existing Packs that have the same Pack ID.
Be careful about enabling the Overwrite option. Doing so will cause the imported Pack to completely overwrite your existing Pack configuration.
Select Copy.
A status modal will either display a success message, or list any Packs that failed to copy.
Create a Pack
You can create a new Pack from scratch, to consolidate and export multiple Cribl Stream configuration objects:
Navigate to the Packs page and select Add Pack.
From the submenu, select Create Pack.
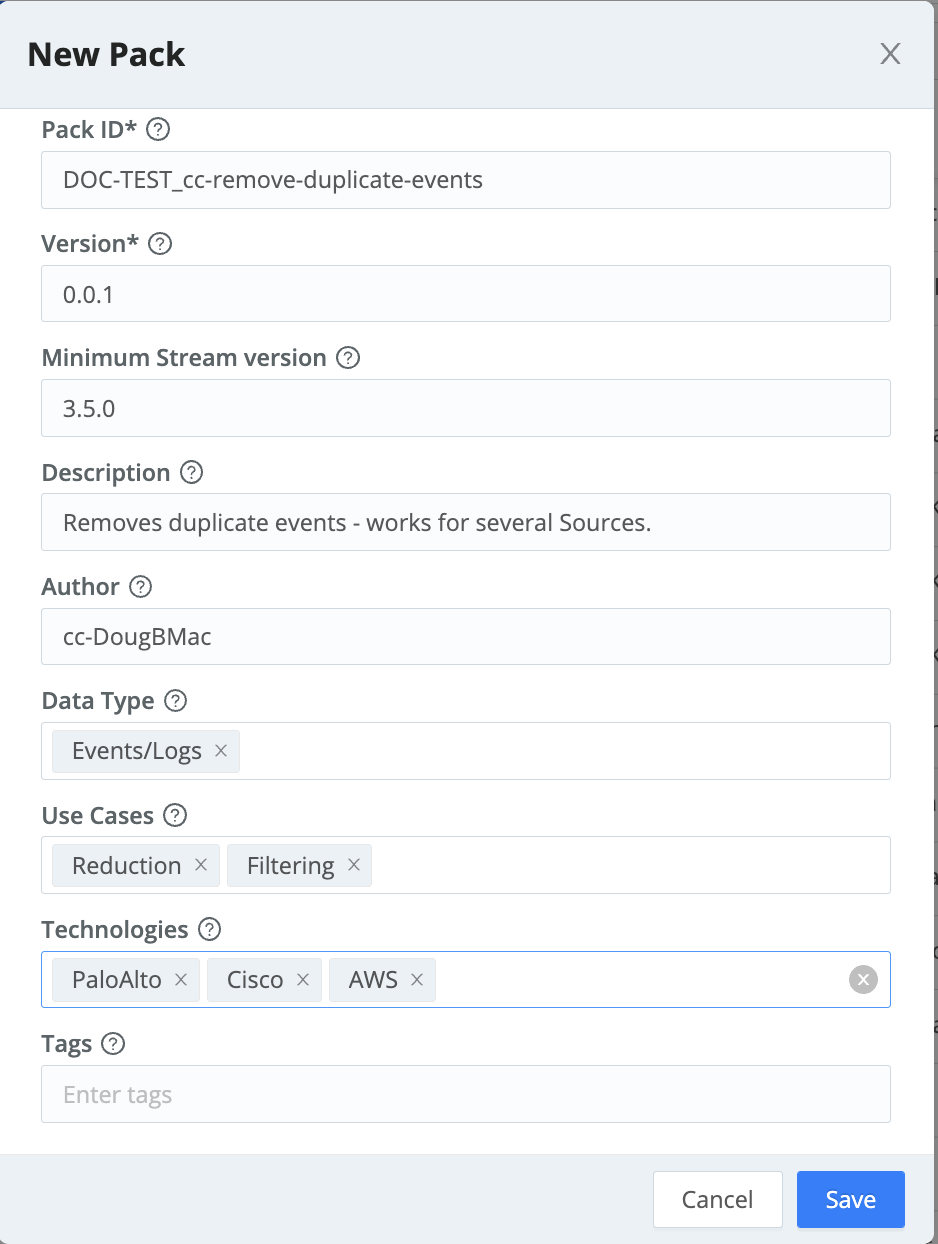
Enter a unique Pack ID and other details:
- Each Pack within a Worker Group must have a separate Pack ID, but you can assign arbitrary Display names.
- Version is a required field identifying the Pack’s own versioning.
- Minimum Stream version is an optional field specifying the lowest compatible version of Cribl Stream software.
- Description and Author are optional identifiers.
- Data type, Use cases, and Technologies are optional combo boxes. You can insert one or multiple keywords to help users filter Packs that you post publicly on the Cribl Packs Dispensary.
- Tags are optional, arbitrary labels that you can use to filter/search and organize Packs.
Select Save.
- On the Packs page, select the new Pack’s row to open the Pack.

- Use the standard Cribl Stream controls to configure and save the infrastructure you want to pack up. As you save changes in the UI, they’re saved to the Pack.
Pack Variables
To make your Packs portable and reusable across different environments, replace fixed values in your configuration with variables and secrets. This practice, known as templatization, allows your Pack to adapt to different environments without you having to manually edit it each time.
For more information about Pack variables, see:
- Pack Variables
- Create a New Variable
- Use Variables in a Pack
- Update Variables After Import or Update
- Delete Variables
Use Named TLS Certificates
Cribl Stream allows you to optionally authenticate to Sources or Destinations using TLS (Transport Layer Security), which encrypts traffic and helps ensure secure communication with upstream or downstream services. TLS certificates help verify the identity of the remote service and can also support mutual authentication when required. See Secure Cribl Stream Sources and Destinations with Certificates for general information about authenticating with TLS certificates and specific instructions on adding and selecting a certificate to a Source or Destination.
For Sources or Destinations defined at the global level (outside of a Pack), Cribl Stream stores TLS certificates at the Worker Group level. Any Worker Nodes in the Worker Group can access those certificates when processing data.
For Sources or Destinations defined at the Pack level (inside a Pack), you can reference a TLS certificate by its name. This approach enables portable and secure configurations across environments:
- When you export that Pack, it does not include the TLS certificate itself, only the reference to the certificate name.
- When you import that Pack to a Worker Group, Cribl Stream checks the local certificate store for that Worker Group. If a certificate with the same name exists, Cribl Stream automatically binds it to the Worker Group.
This approach allows you to:
- Build TLS-secured Sources and Destinations directly within Packs.
- Reuse Pack configurations across environments without exporting certificate data.
- Maintain secure, environment-specific certificate management practices.
Packs do not include certificate files. Instead, they store the name of the certificate to reference. To ensure a successful deployment, make sure each environment contains a certificate with the expected name for the target Worker Group.
If you create the certificate after importing the Pack, commit and deploy the changes to restart the Worker Nodes. The Worker Nodes will pick up the new certificate after restart.
Modify Pack Settings
You can update Pack metadata (such as Version, Description, and Author) and the Pack’s display settings. If you’re developing a new Pack to share, you’ll want to use this interface to populate the README and display logo within the Pack:
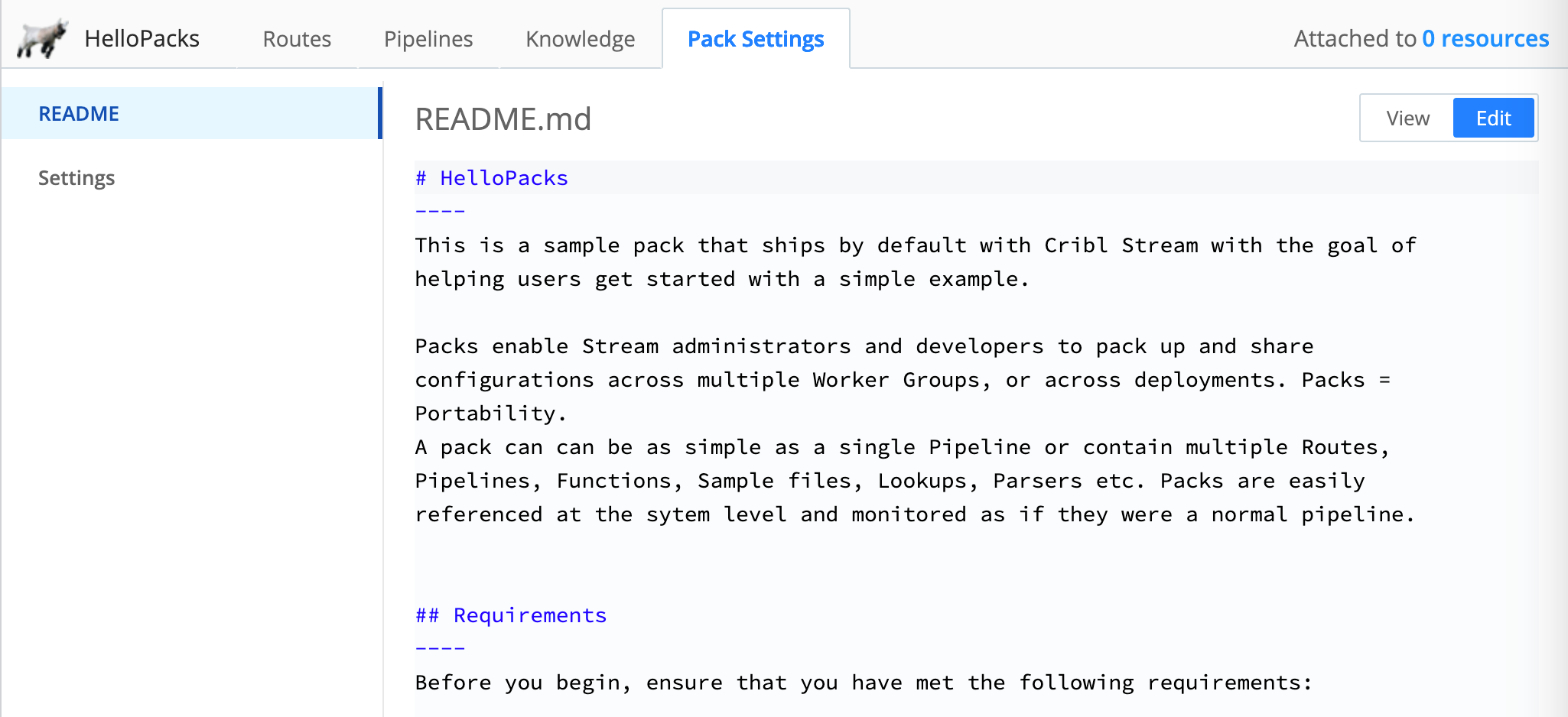
- Open a Pack and select Pack Settings. The left README tab will gain focus.
- To populate the Pack README file, toggle View to Edit, replace the placeholder markdown content with your actual Pack description, and Save.
- To update other metadata, select the left Settings tab.
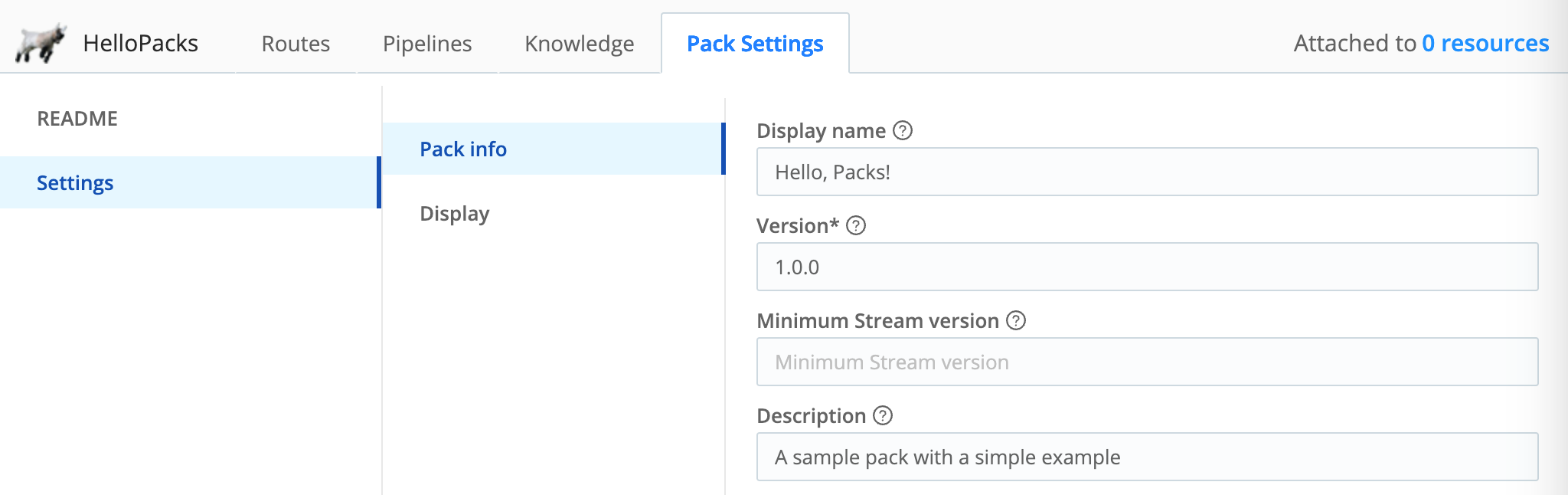
You can add a Pack logo on the Settings tab.
Cribl recommends adding a logo to each custom Pack, to visually distinguish the Pack UI from the surrounding Cribl Stream UI (as well as from other Packs). You can upload a
.pngor.jpg/.jpegfile, up to a maximum size of 2 MB and 350x350 px. Cribl recommends a transparent image, sized approximately 280x50 px.
Share and Publish Packs
To share your Pack with other users, you first need to export it from your deployment.
Then, if you wish, you can publish it to the Cribl Pack Dispensary to make it available for the whole Cribl ecosystem.
Export a Pack
You can also use the Cribl API to export a Pack.
To export a newly created or modified Pack from the Packs page, open its Options ••• menu and select Export.
The Export Pack modal provides the following options.
Export Mode
Select one of these three buttons to determine the export mode:
Merge safe: (Deprecated) Attempt to safely merge local modifications into the Pack’s default layer (original configuration), then export.
Merge: Force-merge local modifications into the Pack’s original configuration, then export. When you export Packs in
mergemode, Cribl Stream deletes all encrypted fields from Pipelines. Upon importing these packs, you will need to re-enter the secrets to make them functional again.Default only: Export only the Pack’s original configuration, without local modifications.
The (deprecated) Merge safe option is conservative, and will block the export where Cribl Stream can’t readily merge modified contents with the Pack’s original contents, due to conflicts. If you encounter an error like the example shown below, use the Merge or Default only export mode instead.

Exported Pack ID
Defaults to the Pack’s current ID, with the version number appended. This field provides an opportunity to change the Pack’s ID, if you’re exporting a new version of the Pack.
Publish a Pack
If you’d like to share your Pack with the community of Cribl users, you can publish it on the Cribl Packs Dispensary.
The Cribl Packs Dispensary site is designed for sharing completed Packs. If you want to collaborate with others on iteratively developing a Pack, Cribl recommends relying on our Dispensary GitHub Repo for the development phase.
If you have a Cribl.Cloud account, you can also collaborate there by inviting team members to your Cribl.Cloud Organization. See Invite Members.
Once your Pack is ready to share, we encourage you to submit it to the Cribl Packs Dispensary site. If you already have completed Packs on our GitHub repo, bring them over here!
Change Pack Owner
If you no longer can or wish to maintain a Pack you published to the Cribl Packs Dispensary, you can transfer its ownership to another user. The new owner will have full control over the Pack.
To transfer a Pack to a new owner:
- Log in to the Cribl Packs Dispensary.
- Optionally, toggle View only my Packs to Yes to narrow down the list to the Packs you own.
- Select Configure on your Pack’s tile.
- At the bottom of the Pack pane, select Change Owner.
- Enter the email address of the new owner and, optionally, a message you want to send them.
- Confirm by selecting Change Owner.
The recipient will get an email message with a request to accept ownership of the Pack. They will have 24 hours to respond.
When the new owner either accepts or rejects the request, you will be notified by email. Until the new owner responds, you can withdraw the request. To do it, open the Pack again and select Cancel Ownership Request.
Supported Pack Integrations
While all Destinations are supported in Packs, a small subset of Sources cannot be included:
| Product | Unsupported Sources |
|---|---|
| Cribl Stream |
|
| Cribl Edge |
|