



Optimize Destination Persistent Queues
Cribl Stream’s Destination persistent queues supplement in-memory queues to prevent data loss during a backpressure event, such as when a downstream Destination receiver is unreachable or slow to respond. See Supported Destinations for more information about which Destinations support persistent queueing.
Read this guide to learn how to optimize your Destination persistent queue. This guide is helpful when you are in the initial planning and configuration stage and also when you have an active deployment that you want to performance tune. This guide explains:
- How Destination persistent queues respond to a backpressure event.
- The overall goals and key metrics involved in optimizing Destination persistent queues.
- An in-depth discussion of the Destination persistent queue configuration options and their potential impact on your system.
- The available notifications, monitoring dashboards, and troubleshooting tools for persistent queues.
See also:
On Cribl-managed Cribl.Cloud Workers with an Enterprise plan, you can enable persistent queue for supported Destinations. However, be aware that mode options and storage limits have specific restrictions in Cribl.Cloud. See For Cribl.Cloud Only: Whether to Use a Hybrid Group for more information.
How Destination Persistent Queues Work
Backpressure occurs when there is a temporary imbalance between the rates of inbound and outbound data that is either coming in or going out of Cribl Stream.
Different events trigger persistent queues on Destinations. For Destinations, the triggers depend on what kind of Destination it is, such as whether it is filesystem-based, TCP, UDP, and so on. See Destination Backpressure Triggers for more detailed information.
When persistent queue (PQ) engages, it writes and stores data on a local file system in your environment until the backpressure event resolves.
Destinations handle data rate imbalances using the following order of operations:
In-memory buffers store data under normal conditions. Under normal conditions, Destinations store data in in-memory buffers before sending the data to a receiver. These in-memory buffers on Destinations help absorb temporary imbalances between inbound and outbound data rates.
If inbound data rates begin to spike, data shifts to storage in all the available buffers for that Destination. Cribl Stream then attempts to output events at a more appropriate rate for the downstream receiver.
The threshold for triggering a backpressure event varies by Destination type. See Destination Backpressure Triggers for more information.
A backpressure event triggers when buffers are full.
Backpressure behavior engages. During a backpressure event, Cribl Stream responds in one of the following ways, based on the Destination Backpressure behavior options you configured on the Destination:
Setting Description Block All data is blocked until the backpressure event has resolved. If set to Block, the output will refuse to accept new data until the receiver is ready. The system will return block signals back to the sender.
If the sender also supports backpressure backpressure response mechanisms, the sender may stop sending data. Consult the documentation for the sender to ensure you know how that specific sender handles a backpressure signal. In general, TCP-based senders support backpressure and stop sending data once Cribl Stream stops sending TCP acknowledgments back to it.Drop Events The Destination will discard all new events until the backpressure event has resolved and the receiver is ready. Persistent Queue If the Destination supports it, the Destination will engage the persistent queue behavior. If enabled, persistent queue engages. If the persistent queue behavior engages, Cribl Stream responds in one of the following ways, based on its configured backpressure mode:
Mode Description Error Queues and stores data on a disk when the Destination is unavailable or in an error state. Backpressure Queues and stores data to a disk when it detects backpressure from the Destination until the backpressure event resolves. Always On Cribl Stream immediately queues and stores all data on a disk for all events, even when there is no backpressure. You can configure additional settings to determine:
- How much data to store in memory.
- What happens to data when the queue reaches its capacity limit.
When the backpressure event ends, data starts flowing out of the persistent queue and into the Destination. Cribl Stream begins to drain persistent queues when the receiver can accept data. In the case of load-balanced receivers, this means when at least one receiver can accept data. By default, after data flow is re-established, the persistent queue flushes every 10 seconds. It uses FIFO (first in, first out) event forwarding, ensuring Cribl Stream sends earlier queued events first when receivers recover. However, in Cribl Stream 4.1 and newer, you can instead prioritize new events by disabling Strict ordering on a Destination.
If you turn off Destination persistent queue (or shut down the whole Destination) before its queues drain, you will orphan any events still queued on disk. See Steps to Safely Disable and Clear Persistent Queues for more information.
Configure Destination Persistent Queue
You configure Destination persistent queue behavior when you configure each individual Destination. Consult the documentation for that Destination for more information about initial configuration.
This section provides a configuration quick start for experienced users. However, new Cribl Stream users should consider reading the full guidance in this topic to get a deeper understanding of the decisions and ideal system architecture design for persistent queue.
To configure persistent queue on a Destination:
In the General Settings tab, set the Backpressure Behavior option to Persistent Queue. See Whether to Enable Persistent Queues for Backpressure Events for guidance about the decision to enable persistent queue.
In the Persistent Queue Settings tab, select an appropriate Mode from the available options. See When and How to Store Data to Disk During a Backpressure Event for information about which mode to select.
Set the File size limit to specify the maximum amount of data stored in each queue file before the file closes and starts a new file. Set the Queue size limit to determine the maximum amount of disk space that Cribl allows the queue to consume on each Worker Process. See How Much Data to Store in Memory for more information about these settings.
Set the Queue file path to determine the location for the persistent queue files. See Where to Store Data and How Much Disk Space to Allocate for more information.
Optional: Set the Compression type to apply compression to the data before the queue file closes. See Whether to Compress Data for more information.
Set the Queue-full behavior to determine what happens when the persistent queue reaches its Queue size limit and runs out of space. See What Happens to Data when the Queue Reaches Its Configured Limits for more information.
The Backpressure duration limit setting displays when the Mode is set to
Backpressure. It controls the duration a Destination must experience backpressure before data is queued to disk. The default waiting time is30seconds. Lowering this limit strengthens data loss prevention, while increasing it helps prevent unnecessary queue activation in environments with frequent, short network interruptions.Optional: If needed, turn off Strict Ordering to more finely tune the Drain rate limit (EPS). See How to Drain Persistent Queues When Backpressure Events End for more information.
Overview of Destination Persistent Queue Optimization
A well-optimized data throughput system can efficiently and reliably processes and transfer data from Sources to Destinations. Optimized systems maximize performance while minimizing latency, errors, and resource consumption. An optimized system has these characteristics:
- High efficiency: Data flows seamlessly at the maximum achievable rate without bottlenecks or excessive resource usage. The system gracefully handles backpressure events, ensuring that data intelligently throttles or queues without overwhelming downstream components.
- Reliability: The system consistently handles variations in data volume or speed without losing or corrupting data, even during spikes or failures.
- Scalability: The system adapts smoothly to increasing data loads or additional data senders or receivers without degradation in performance.
- Low latency: The system processes and delivers data in near real-time, meeting the required time constraints for your business use cases.
- Cost-efficient resource allocation: The system uses CPU, memory, disk, and network resources effectively, avoiding over-provisioning or waste.
- Security and compliance: The system transmits data securely, meeting all relevant privacy, encryption, and regulatory requirements.
Ultimately, you and your business stakeholders should have confidence in the system’s performance, reliability, and ability to adapt to future needs. Persistent queue is an important tool to achieve this confidence.
Persistent Queue Optimization Metrics
The most effective way to performance tune is to understand which key metrics give insights into your persistent queues system’s overall health. Effective system administrators study their deployments to establish a performance baseline that they can use for comparison if a performance issue arises. Most system administrators understand their system well and can easily identify peak data periods.
Pay attention to these metrics:
- CPU utilization: When your system gets sudden increases in data loads, you might notice that your Worker Processes operate at full capacity and use all their CPU. Generally, that’s a sign of inefficiency or the need for more resources. If needed, you can teleport into a single Worker and view all the processes and their individual CPU utilization. To see your CPU utilization, you can use the system monitoring tools to analyze CPU utilization. If needed, you can also teleport into a single Worker and view all the processes and their individual CPU utilization.
- Data latency: Some persistent queues can add latency because of the amount of overhead time it takes to write data to disk. As a starting point, assume that each event incurs a few milliseconds of added latency. Be aware that data latency can vary by file system, such as whether you are using a local file system or a Network File System (NFS). NFS file systems tend to introduce higher and more variable latency. To measure the latency impact of your persistent queue system, compare the throughput times of your system without persistent queues enabled and then introduce persistent queue and measure the difference.
- Memory: When your system experiences sudden increases in data, your Workers need memory to store that data in temporary buffers. Consider what should happen in your system when memory is fully utilized.
- Data storage: When you back up data to a disk, that requires available disk space to use. Allocating memory and disk space can potentially be expensive. Be aware of the rate at which you consume disk memory and the general costs you estimate you will incur to write data to disk. Have systems in place for knowing when disk space is running out and adding more memory as needed.
- Data throughput: You need to understand your system’s throughput under normal conditions so that you can identify potential bottlenecks in the system. Use the system monitoring tools to develop this baseline.
Key Decisions When Configuring Destination Persistent Queues
You configure Destination persistent queue behavior when you configure each individual Destination. Consult the documentation for that Destination for more information about initial configuration.
This section explains the decision-making process you should consider when implementing persistent queue on a Destination. It explains the benefits and tradeoffs of different configuration settings for most use cases.
Whether to Enable Persistent Queues for Backpressure Events
The first decision you need to make is whether to use persistent queue to respond to backpressure. See When to Use Persistent Queues for a detailed explanation of which kinds of environments benefits from persistent queues.
In general, you should not use persistent queue is you are already using a backpressure mechanism on a downstream receiver. Implementing backpressure mechanisms such as persistent queue on both Cribl Stream and the Destination is redundant and could cause unnecessary data latency or impact data throughput.
The alternatives to using persistent queue are to block data or to drop events when a backpressure event occurs. Consider blocking events if you need Cribl to return block signals back to an upstream sender. If the sender also supports backpressure backpressure response mechanisms, the sender may stop sending data.
Consult the documentation for the sender to ensure you know how that specific sender handles a backpressure signal. In general, TCP-based senders support backpressure and stop sending data once Cribl Stream stops sending TCP acknowledgments back to it.
For Cribl.Cloud Only: Whether to Use a Hybrid Group
On Cribl-managed Cribl.Cloud Workers (with an Enterprise plan), persistent queue does not come with many of the configuration options described in the rest of this page. For Cribl.Cloud, enabling persistent queue only exposes the destructive Clear Persistent Queue button. Use this button with caution to avoid data loss. See Steps to Safely Disable and Clear Persistent Queues for more information.
When you enable persistent queues in Cribl.Cloud, Cribl automatically allocates up to 1 GB of disk space per Destination, per Worker Process. This 1 GB limit applies to outbound uncompressed data, and the queue does not perform any compression. If the queue fills up, Cribl Stream blocks data flow.
You cannot change this limit. If the queue fills up, Cribl Stream/Edge will block outbound data. Use a hybrid Group if you need to configure:
- Queue size
- Compression
- Backpressure modes
- Other persistent queue settings
When and How to Store Data to Disk During a Backpressure Event
Once the backpressure queue behavior engages, you need to determine how it should write data to disk. You have three available options (modes) for storing data during a backpressure event:
| Mode | Description |
|---|---|
| Error | Queues and stores data on a disk when the Destination is unavailable or in an error state. |
| Backpressure | Queues and stores data to a disk when it detects backpressure from the Destination until the backpressure event resolves. |
| Always On | Cribl Stream immediately queues and stores all data on a disk for all events, even when there is no backpressure. |
Consider using the Always On mode if your business has a low tolerance for data loss. However, do so with some caution. Enabling this mode could have impacts on the persistent queue optimization metrics, such as disk space, throughput, data latency, and CPU utilization.
Consider experimenting with this mode to see whether it’s right for your business needs. Establish a baseline for system performance before you enable Always On and then observe the impacts when you turn that mode on. Ensure you have enough disk storage space to handle your data storage needs.
How Much Data to Store in Memory
When you enable persistent queues, you can configure the File size limit setting to specify the maximum amount of data stored in each queue file before the file closes and starts a new file. You can enter a value in units such as KB, MB, and more. If left unspecified, Cribl Stream/Edge defaults to 1 MB.
Additionally, you can use the Queue size limit setting to determine the maximum amount of disk space that Cribl allows the queue to consume on each Worker Process. Once the queue reaches this limit, the Source will stop queueing data and engage the configured backpressure mode. You can enter a value in units such as KB, MB, GB, or TB.
If the Queue size limit is not specified, it defaults to 5 GB. You can adjust this value to better suit your needs. For Sources with undefined Queue size limit values, queues exceeding 5 GB will trigger the configured queue-full behavior until you resize the limit.
To set a higher maximum value, navigate to Worker Group/Fleet Settings > General Settings > Limits > Storage > Worker Process PQ size limit. The corresponding key in the limits.yml file is maxPQSize. (See Config Files: limits.yml for more information.) The default for this setting is 1 TB. Before increasing this limit, consult Cribl Support for guidance.
The information in this section applies only to on-prem or hybrid Worker Groups. For Cribl-managed Cribl.Cloud Organizations using persistent queue, Cribl automatically allocates up to 1 GB of disk space per Source, per Worker Process. You cannot change this limit.
This 1 GB limit applies to outbound uncompressed data, and the queue does not perform any compression. If the queue fills up, Cribl Stream/Edge blocks data flow, including outbound data.
Whether to Compress Data
When the queue file reaches its maximum file size, you can use the optional Compression setting to apply compression to the data before the queue file closes. Currently, the only available compression codec is Gzip.
If you enable Compression and also enter a Queue size limit, be aware of how these options interact:
- Cribl Stream/Edge currently applies the Queue size limit against the uncompressed data volume entering the queue.
- With this combination, Cribl recommends that you set the Queue size limit higher than the volume’s total available disk space, not including compression. This will maximize queue saturation and minimize data loss.
Where to Store Data and How Much Disk Space to Allocate
Use the Queue file path setting to determine the location for the persistent queue files. The default is $CRIBL_HOME/state/queues. When writing data, Cribl Stream/Edge will append /<worker-id>/<output-id> to this path.
For queuing to operate properly, you must provide sufficient disk space. In Distributed mode, this minimum disk space configuration is set on each Worker Group/Fleet. You can access this setting at Group/Fleet settings > General Settings > Limits > Min free disk space.
If available disk space falls below this minimum threshold, Cribl Stream/Edge will stop maintaining persistent queues, and data loss will begin. The default minimum is 5 GB.
Queue file path: The location for the persistent queue files. Defaults to $CRIBL_HOME/state/queues. To this value, Cribl Stream/Edge will append /<worker-id>/<output-id>.
What Happens to Data when the Queue Reaches Its Configured Limits
You can use the Queue-Full Behavior setting to determine what happens when the persistent queue reaches its Queue size limit and runs out of space. There are two options:
| Setting | Description |
|---|---|
| Block | Blocks all data until the backpressure event has resolved. If set to Block, the output will refuse to accept new data until the receiver is ready. The system will return block signals back to the sender. |
| Drop new data | The Destination will discard all new events until the backpressure event has resolved and the receiver is ready. |
How to Drain Persistent Queues When Backpressure Events End
When a backpressure event ends, the persistent queue begins to drain to the downstream Destination. You can configure the order of event delivery and the rate at which Cribl Stream forwards events.
Use the Strict Ordering setting to configure the order that Cribl Stream sends data to the Destination. Toggle Strict Ordering on (default) to use FIFO (first in, first out) processing. This means Cribl prioritizes earlier queued events before sending newly arrived data. Toggle Strict Ordering off to change this behavior, prioritizing new data over the events already in the queue.
If you toggle Strict Ordering off, you must configure the Drain rate limit (EPS). This setting allows you to throttle the rate at which events drain from the persistent queue to the Destination. The default value of 0 disables throttling. Throttling the drain rate helps Cribl manage the incoming stream of live data more effectively, preventing delays caused by queue processing. It also improves the throughput of active connections by reserving additional resources for them.
The Drain rate limit (EPS) is set in Events Per Second (EPS). To determine your system’s EPS value:
- Open the Monitoring page. From Cribl Stream’s sidebar, select Monitoring to access dashboards displaying data for all Worker Groups and all nodes.
- Filter by a specific node. Use the Groups menu at the top to restrict monitoring data to a single Worker Node.
- Adjust the time granularity. Use the time menu change the display granularity from the default
15 minto1 dayfor better accuracy. - Locate the EPS metrics. On the Monitoring page, find the Events In and Out metrics group. Copy the value listed under THROUGHPUT IN (AVG). For example, a typical value might be
31,000 EPS.
Cribl recommends setting the Drain Rate Limit to 10% of the Worker Process EPS to prioritize live data processing. To calculate an appropriate drain rate:
- Determine EPS per Worker Process. Divide the Worker Process EPS by the number of Worker Processes (WPs). For example:
31,000 EPS / 14 WPs = 2,200 EPS per WP. - Calculate 10% of EPS per Worker Process. Multiply the result by
0.10to find the recommended drain rate. For example:10% of 2,200 EPS = 220 EPS. - Configure the Drain Rate Limit. In the persistent queue settings for the Destination, enter this value in the Drain rate limit (EPS) field. For example:
220.
After applying this setting, monitor the queue’s drain rate. If the queue is draining too slowly, carefully increase the Drain rate limit (EPS) while ensuring it doesn�t interfere with live data processing. Avoid setting the limit too high, as this can impact the performance of live streams. If needed, consider optimizing Worker startup connections and managing CPU load to further enhance performance at Group Settings > Worker Processes.
Cribl’s guarantee for data delivery is that all data is delivered at least once, but not exactly once. Sometimes Cribl Stream sends duplicate data events when the persistent queue drains.
Steps to Safely Disable and Clear Persistent Queues
If you want to disable persistent queuing, always wait for the queue to fully drain. The Clear Persistent Queue button is available as a destructive fallback. This action frees up disk space, but it also deletes the queued data without sending it on to receivers.
After the queue has drained, then you can select a different backpressure behavior. Save the configuration after changing it.
Destination Persistent Queue Notifications
Some Cribl licenses allow you to configure Notifications for Destination persistent queues for on-prem deployments. In general, Cribl recommends setting Notifications for these events when using persistent queue to ensure you are aware of important system events. These Notifications always appear in Cribl Stream’s user interface and internal logs. You can also send them to external systems.
You can set notifications for these scenarios:
- Persistent queue files exceed a configurable percentage of allocated storage.
- A Destination reaches the queue-full state, meaning it is running out of available disk space.
- A Destination backpressure engages, causing blocked or dropped events.
- Persistent Queue Usage (saturation).
See About Notifications for information about adding Notifications for Destinations.
Monitor Destination Persistent Queues
Cribl Stream provides metrics and health indicators to monitor your Destination persistent queue through the Status tab on your Destination. Cribl Stream provides metrics and health indicators to monitor your Source persistent queue through the Status tab on your Source. The Status tab aggregates metrics and health from all Worker Processes, allowing you to assess the health of your persistent queues and the status of the Destination in real time.
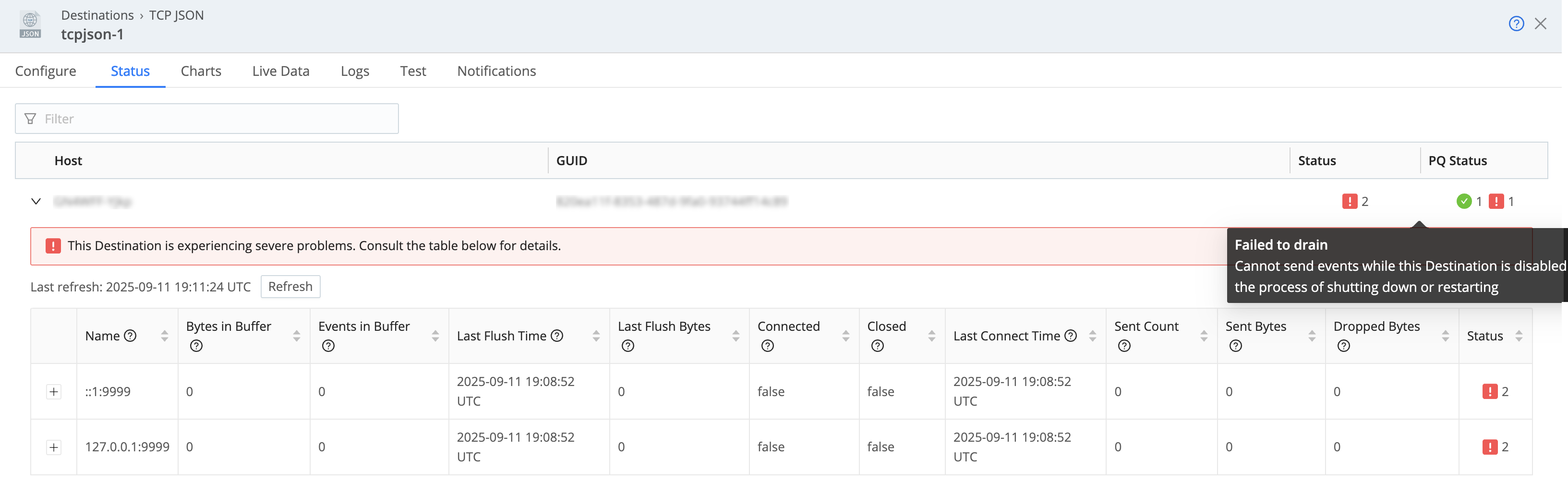
To view the Destination persistent queue metrics:
On the top bar, select Products, and then select Cribl Stream. Under Data, select Destinations.
From the sidebar, select the type of Destination you want to view.
Select the Destination from the list of currently configured Destination.
In the resulting modal, select the Status tab.
Inside this view, you can expand individual Worker Nodes for more details.
For additional analysis, you can also use Monitoring dashboards:
Navigate to Monitoring on the product sidebar.
Navigate to System > Queues (Sources) and view relevant data.
Troubleshooting Tools
Cribl internal logs for Cribl-managed Workers might include entries labeled Revived PQ Worker Process. These indicate where a Cribl-managed Worker was newly assigned to drain a persistent queue left over from a shut-down Worker Node. You can use these log events to troubleshoot Cloud PQ issues.
Reference: Destination Persistent Queue Fields
The Persistent Queue Settings tab displays when the Backpressure behavior option in General settings is set to Persistent Queue. Persistent queue buffers and preserves incoming events when a downstream Destination has an outage or experiences backpressure.
Before enabling persistent queue, learn more about persistent queue behavior and how to optimize it with your system:
- About Persistent Queues
- Optimize Destination Persistent Queues (dPQ)
- Destination Backpressure Triggers
On Cribl-managed Cloud Workers (with an Enterprise plan), this tab exposes only the destructive Clear Persistent Queue button (described at the end of this section). A maximum queue size of 1 GB disk space is automatically allocated per PQ-enabled Destination, per Worker Process. The 1 GB limit is on outbound uncompressed data, and no compression is applied to the queue.
This limit is not configurable. If the queue fills up, Cribl Stream/Edge will block outbound data. To configure the queue size, compression, queue-full fallback behavior, and other options below, use a hybrid Group.
Mode: Use this menu to select when Cribl Stream/Edge engages the persistent queue in response to backpressure events from this Destination. The options are:
| Mode | Description |
|---|---|
| Error | Queues and stores data on a disk when the Destination is unavailable or in an error state. |
| Backpressure | Queues and stores data to a disk when it detects backpressure from the Destination until the backpressure event resolves. |
| Always On | Cribl Stream or Edge immediately queues and stores all data on a disk for all events, even when there is no backpressure. |
If a Worker/Edge Node starts with an invalid Mode setting, it automatically switches to Error mode. This might happen if the Worker/Edge Node is running a version that does not support other modes (older than 4.9.0), or if it encounters a nonexistent value in YAML configuration files.
File size limit: The maximum data volume to store in each queue file before closing it. Enter a numeral with units of KB, MB, etc. Defaults to 1 MB.
Queue size limit: The maximum amount of disk space that the queue can consume on each Worker Process. When the queue reaches this limit, the Destination stops queueing data and applies the Queue-full behavior. Defaults to 5 GB. This field accepts positive numbers with units of KB, MB, GB, and so on. You can set it as high as 1 TB, unless you’ve configured a different Worker Process PQ size limit on the Worker Group/Fleet Settings page.
Queue file path: The location for the persistent queue files. Defaults to $CRIBL_HOME/state/queues. Cribl Stream/Edge will append /<worker-id>/<output-id> to this value.
Compression: Set the codec to use when compressing the persisted data after closing a file. Defaults to None. Gzip is also available.
Queue-full behavior: Whether to block or drop events when the queue begins to exert backpressure. A queue begins to exert backpressure when the disk is low or at full capacity. This setting has two options:
- Block: The output will refuse to accept new data until the receiver is ready. The system will return block signals back to the sender.
- Drop new data: Discard all new events until the backpressure event has resolved and the receiver is ready.
Backpressure duration Limit: When Mode is set to Backpressure, this setting controls how long to wait during network slowdowns before activating queues. A shorter duration enhances critical data loss prevention, while a longer duration helps avoid unnecessary queue transitions in environments with frequent, brief network fluctuations. The default value is 30 seconds.
Strict ordering: Toggle on (default) to enable FIFO (first in, first out) event forwarding, ensuring Cribl Stream/Edge sends earlier queued events first when receivers recover. The persistent queue flushes every 10 seconds in this mode. Toggle off to prioritize new events over queued events, configure a custom drain rate for the queue, and display this option:
- Drain rate limit (EPS): Optionally, set a throttling rate (in events per second) on writing from the queue to receivers. (The default
0value disables throttling.) Throttling the queue drain rate can boost the throughput of new and active connections by reserving more resources for them. You can further optimize Worker startup connections and CPU load in the Worker Processes settings.
Clear Persistent Queue: For Cloud Enterprise only, click this button if you want to delete the files that are currently queued for delivery to this Destination. If you click this button, a confirmation modal appears. Clearing the queue frees up disk space by permanently deleting the queued data, without delivering it to downstream receivers. This button only appears after you define the Output ID.
Use the Clear Persistent Queue button with caution to avoid data loss. See Steps to Safely Disable and Clear Persistent Queues for more information.